







文章目录
9.10 Mask-RCNN
9.10.1 Mask-RCNN 的网络结构示意图

其中黑色部分为原来的Faster-RCNN,红色部分为在Faster 网络上的修改:
1)将ROI Pooling层替换成了 ROIAlign;
2)添加并列的FCN层(Mask层);
先来概述一下 Mask-RCNN的几个特点(来自于Paper Mask R-CNN 的Abstract):
1) 在边框识别的基础上添加分支网络,用于语义Mask 识别;
2)训练简单,相对于 Faster仅增加一个小的 Overhead,可以跑到 5FPS;
3)可以方便的扩展到其他任务,比如人的姿态估计等;
4)不借助Trick,在每个任务上,效果优于目前所有的 single-model entries;包括 COCO 2016 的Winners。
9.10.2 RCNN行人检测框架
来看下后面两种RCNN方法与Mask结合的示意图:

图中灰色部分是原来的RCNN结合 ResNet or FPN的网络,下面黑色部分为新添加的并联 Mask层,这个图本身与上面的图也没有什么区别,旨在说明作者所提出的Mask RCNN方法的泛化适应能力:可以和多种RCNN框架结合,表现都不错。
9.10.3 Mask-RCNN 技术要点
1. 技术要点1-强化的基础网络
通过ResNet-101 + FPN用作特征提取网络,达到 state-of-the-art的效果。
2. 技术要点2-ROIAlign
采用ROIAlign替代RoiPooling(改进池化操作)。引入了一个插值的过程,先通过双线性插值到1414,再pooling到77,很大程度上解决了仅通过Pooling直接采样带来的Misalignment对齐问题。
PS:虽然 Misalignment 在分类问题上影响并不大,但在Pixel级别的Mask上会存在较大误差。
后面我们把结果对比贴出来(Table c & d),能够看到 ROIAlign带来较大的改进,可以看到,Stride越大改进越明显。
3. 技术要点3-Loss Function
每个ROIAlign对应 k*m^2维度的输出。K对应类别个数,即输出K个mask,m对应池化分辨率(7*7)。Loss函数定义:
平均二值交叉熵(average binary cross-entropy)Loss,通过逐像素的Sigmoid计算得到。
Why K 个 mask?通过对应每个Class对应一个Mask可以有效避免类间竞争(其他Class不贡献Loss)。
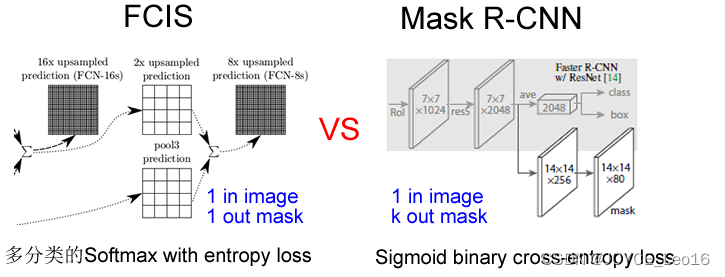
通过结果对比来看(Table2 b),也就是作者所说的 Decouple解耦,要比多分类的Softmax效果好很多。
另外,作者给出了很多实验分割结果,就不都列了,只贴一张和FCIS的对比图(FCIS出现了Overlap的问题)。

9.11 CNN在基于弱监督学习的图像分割中的应用
答案来源:CNN在基于弱监督学习的图像分割中的应用 - 知乎
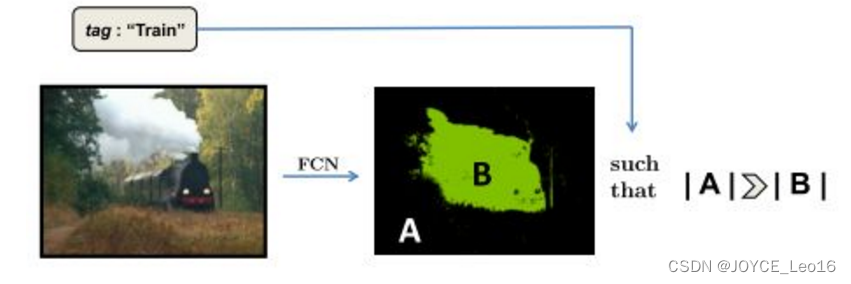
最近基于深度学习的图像分割技术一般依赖于卷积神经网络CNN的训练,训练过程中需要非常大量的标记图像,即一般要求训练图像中都要有精确的分割结果。
对于图像分割而言,要得到大量的完整标记过的图像非常困难,比如在ImageNet数据集上,有1400万张图有类别标记,有50万张图给出了bounding box,但是只有4460张图像有像素级别的分割结果。对训练图像中的每个像素做标记非常耗时,特别是对医学图像而言,完成对一个三维的CT或者MRI图像中各组织的标记过程需要数小时。
如果学习算法能通过对一些粗略标记过的数据集的学习就能完成好的分割结果,那么对训练数据的标记过程就很简单,这可以大大降低花在训练数据标记上的时间。这次粗略标记可以是:
- 只给出一张图像里面包含哪些物体。
- 给出某个物体的边界框。
- 对图像中的物体区域做部分像素的标记,例如画一些线条、涂鸦等(scribbles)。
9.11.1 Scribble 标记
论文地址:ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation (CVPR 2016)
香港中文大学的Di Lin提出了一个基于Scirbble标记的弱监督学习方法。Scribble是一个很方便使用的标记方法,因此被用得比较广泛。如下图,只需要画五条线就能完成对一副图像的标记工作。

ScribbleSup分为两步,第一步将像素的类别信息从scribbles传播到其他未标记的像素,自动完成所有的训练图像的标记工作;第二步使用这些标记图像训练CNN。在第一步中,该方法先生成super-pixels,然后基于graph cut方法对所有的super-pixel进行标记。

Graph Cut的能量函数为:
在这个graph中,每个super-pixel是graph中的一个节点,相接壤的super-pixel之间有一条连接的边。这个能量函数中的一元项包括两种情况,一个是来自scribble的,一个是来自CNN对该super-pixel预测的概率。整个最优化过程实际上是求graph cut能量函数和CNN参数联合最优值的过程:
上式的最优化是通过交替求和
的最优值来实现的。文章中发现通过三次迭代就能得到比较好的结果。

9.11.2 图像级别标记
论文地址:Constrained Convolutional Neural Networks for Weakly Supervised Segmentation (ICCV 2015)
UC Berkeley 的Deep Pathak使用了一个具有图像级别标记的训练数据来做弱监督学习。训练数据中只给出图像中包含某种物体,但是没有其位置信息和所包含的像素信息。该文章的方法将image tags转化为对CNN输出的label分布的限制条件,因此称为 Constrained convolution neural network(CCNN)。
该方法把训练过程看作是有线性限制条件的最优化过程:
其中的线性限制条件来自于训练数据上的标记,例如一幅图像中前景类别像素个数期望值的上界或者下界(物体大小)、某个类别的像素个数在某图像中为0,或者至少为1等。该目标函数可以转化为一个 loss function,然后通过SGD进行训练。

实验中发现单纯使用Image tags作为限制条件得到的分割结果还比较差,在PASCAL VOC 2012 test数据集上得到的mIOU为35.6%,加上物体大小的限制条件后能达到45.1%,如果再使用bounding box做限制,可以达到54%。FCN-8s可以达到62.2%,可见弱监督学习要取得好的结果还是比较难。
9.11.3 DeepLab+bounding box+image-level labels
论文地址:Weakly-and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation
Google的George Papandreou 和UCLA的Liang-Chieh Chen 等在DeeoLab的基础上进一步研究了使用bounding box和image-level labels作为标记的训练数据。使用了期望值最大化算法(EM)来估计未标记的像素的类别和CNN的参数。

对于image-level标记的数据,我们可以观测到图像的像素值和图像级别的标记 ,但是不知道每个像素的标号,因此把 y 当做隐变量。使用如下的概率图模式:
这篇论文是通过EM算法来学习模型的参数,具体推导过程可参考原论文。

对于给出bounding box标记的训练图像,该方法先使用CRF对该训练图像做自动分割,然后在分割的基础上做全监督学习。通过实验发现,单纯使用图像级别的标记得到的分割效果较差,但是使用bounding box的训练数据可以得到较好的结果,在VOC2012 test数据集上得到mIoU 62.2%。另外如果使用少量的全标记图像和大量的弱标记图像进行结合,可以得到与全监督学习(70.3%)接近的分割结果(69.0%)。
9.11.4 统一的框架
论文地址:Learning to Segment Under Various Forms of Weak Supervision (CVPR 2015)
Wisconsin-Madison大学的Jia Xu提出了一个统一的框架来处理各种不同类型的弱标记:图像级别的标记、bounding box和部分像素标记如scribbles。该方法把所有的训练图像分成共计 n 个super-pixel,对每个super-pixel提取一个 d 维特征向量。因为不知道每个super-pixel所属的类别,相当于无监督学习,因此该方法对所有的super-pixel做聚类,使用的是最大间隔聚类方法(max-margin clustering, MMC),该过程的最优化目标函数是:
在这个目标函数的基础上,根据不同的弱标记方式,可以给出不同的限制条件,因此该方法就是在相应的限制条件下求最大间隔聚类。

该方法在Siftflow数据集上得到了比较好的结果,比state-of-the-art的结果提高了10%以上。
小结:在弱标记的数据集上训练图像分割算法可以减少对大量全标记数据的依赖,在大多数应用中会更加贴合实际情况。弱标记可以是图像级别的标记、边框和部分像素的标记等。训练的方法一般看做是限制条件下的最优化方法。另外EM算法可以用于CNN参数和像素类别的联合求优。
9.11.5 弱监督分割最新进展
- bbox监督
1. Learning to Segment via Cut-and-Paste(ECCV 2018)
利用GAN对抗学习的思想,在cut-paste思想指导下利用bbox弱监督进行实例分割。
采用对抗学习的思想,网络主体分为两大部分:mask生成器和合成图像判别器。具体过程为:
(1)在图像上截取gt,经过特征提取后预测一个bbox内gt的mask;
(2)在原图上随机cut一个背景图像,将bbox内按照生成的mask提取出物体分割结果,然后paste到原图裁剪的背景上去;
3)合成的图像经过判别器进行真假判断。 通过生成器生成更好mask来使得判别器更难判别,在对抗学习中提升两者的性能,逐渐获得更好的结果 .
2. Simple Does It: Weakly Supervised Instance and Semantic Segmentation(CVPR2017)
本文做的是bbox弱监督语义/实例分割任务,能达到全监督分割效果(DeepLabv1)的95%。主要工作为:讨论了使用弱监督语义标签进行迭代训练的方法,以及其限制和不足之处;证明了通过类似GrabCut的算法能通过bbox生成分割训练标签方法的可行性,可以避免像上面的迭代方法重新调整网络训练策略;在VOC数据集上逼近监督学习的分割任务效果。 作者的启发是:将bbox level的mask送入网络训练后得到分割mask的比输入的bbox mask要好(这是很好的insight)。因此启发的操作是:将bbox level标注作为初始mask输入优化,每次得到的标注作为gt进行下一轮的迭代,从而不断获得更好的效果。
在此基础上,再加上优化的GrabCut+算法,以及部分区域的筛选,以及BSDS500的边界预测信息整合到一起,能够达到很好的弱监督迭代分割效果。
- 分类监督
1. Weakly Supervised Learning of Instance Segmentation with Inter-pixel Relations(CVPR2019)
使用分类标注作为弱监督信息,在CAM提取到特征的基础上,进一步设计IRNet学习额外的特征约束,从而到达更好的弱监督实例分割效果。为了解决CAM应用到实例分割的上述局限,设计IRNet。其组成为两部分:
(1)不分类别的实例响应图。
(2)pairwise semantic affinitie。其中通过不分类别的实例响应图和CAM结合,约束后得到instance-wise CAMS;另一个分支预先预测物体的边界然后得到pairwise semantic affinitie(关于这个的论文参考Related Work的对应部分,有相应的方法,暂时不深究)进行融合和处理得到最终的分割。
2. Weakly Supervised Instance Segmentation using Class Peak Response(CVPR2018)
本文使用图像级的类别标注监督信息,通过探索类别响应峰值使分类网络能够很好地提取实例分割mask。本工作是使用图像级标注进行弱监督实例分割的首个工作。 在分类监督信息之下,CNN网络会产生一个类别响应图,每个位置是类别置信度分数。其局部极大值往往具有实例很强视觉语义线索。首先将类别峰值响应图的信息进行整合,然后反向传播将其映射到物体实例信息量较大的区域如边界。上述从类别极值响应图产生的映射图称为Peak Response Maps (PRMs),该图提供了实例物体的详细表征,可以很好地用作分割监督信息。
首先将图片经过正常的分类网络训练,其中在类别预测响应图上提取出局部响应极值点,进行增强卷积后预测出PRM。然后结合多种信息进行推断生成mask。
3. Weakly Supervised Semantic Segmentation Using Superpixel Pooling Network(AAAI 2017)
本文介绍通过类别标注的标签实现弱监督语义分割的方法。该方法在语义分割mask生成和使用生成mask学习分割生成网络之间反复交替。要实现这种交替迭代学习,关键点就是如何利用类别标注得到较准确的初始分割。为了解决这一问题,提出了Superpixel Pooling Network (SPN),将输入图像的超像素分割结果作为低阶结构的表征,辅助语义分割的推断。
首先是SPN生成初始mask,然后用另一个网络DecoupledNet来学习每个像素的mask标注。其中,该分割网络将语义分割任务解耦为分类和分割两个子任务,并且能够从类别标注中学习形状先验知识用于辅助分割。
















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











