







文章目录
11.2 迁移学习的基本思路有哪些
迁移学习的基本方法可以分为四种。这四种基本方法分别是:基于样本的迁移,基于模型的迁移,基于特征的迁移,及基于关系的迁移。
11.2.1 基于样本迁移
基于样本的迁移学习方法(Instance based Transfer Learning)根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习。图14形象地表示了基于样本迁移方法的思想源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗这一种类别。在迁移时,为了最大限度地和目标域相似,我们可以人为地提高源域中属于狗这个类别的样本权重。
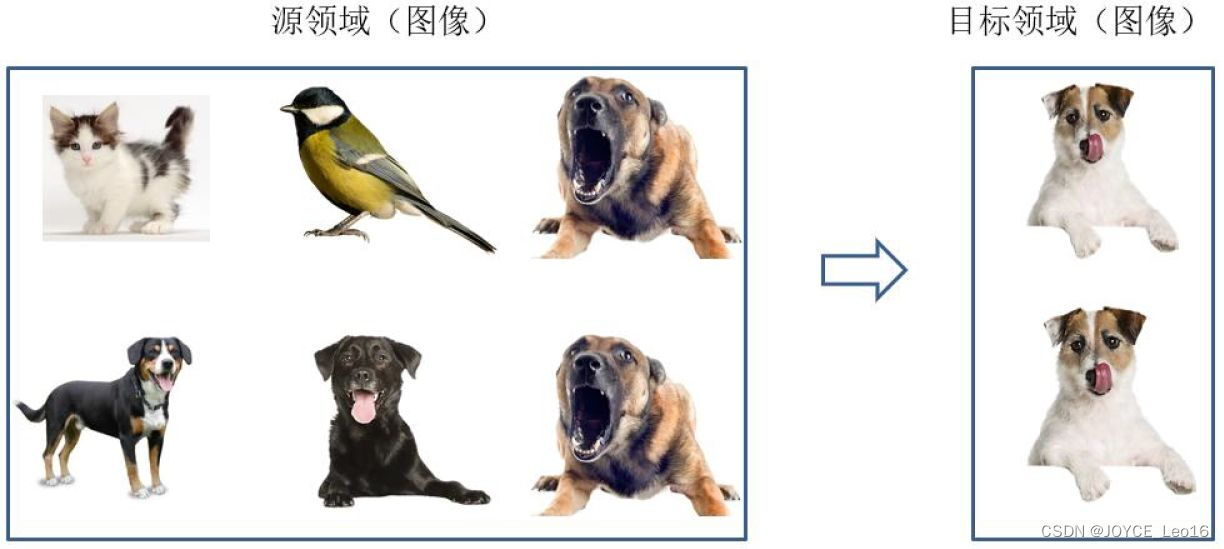
图14 基于样本的迁移学习方法示意图
在迁移学习中,对于源域Ds和目标域Dt,通常假定产生它们的概率分布是不同且未知的(P(Xs) =P(Xt))。另外,由于实例的维度和数量通常都非常大,因此,直接对 P(Xs) 和P(Xt) 进行估计是不可行的。因而,大量的研究工作 [Khan and Heisterkamp,2016, Zadrozny, 2004, Cortes et al.,2008, Dai et al., 2007, Tan et al.,2015, Tan et al., 2017]着眼于对源域和目标域的分布比值进行估计(P(Xt)/P(Xs))。所估计得到的比值即为样本的权重。这些方法通常都假设P(xs) <并且源域和目标域的条件概率分布相同(P(y|xs)=P(y|xt))。特别地,上海交通大学Dai等人 [Dai et al.,2007]提出了 TrAdaboost方法,将AdaBoost的思想应用于迁移学习中,提高有利于目标分类任务的实例权重、降低不利于目标分类任务的实例权重,并基于PAC理论推导了模型的泛化误差上界。TrAdaBoost方法是此方面的经典研究之一。文献 [Huang et al.,2007]提出核均值匹配方法 (Kernel Mean atching, KMM)对于概率分布进行估计,目标是使得加权后的源域和目标域的概率分布尽可能相近。在最新的研究成果中,香港科技大学的Tan等人扩展了实例迁移学习方法的应用场景,提出 了传递迁移学习方法(Transitive Transfer Learning, TTL) [Tan et al.,2015] 和远域迁移学习 (Distant Domain Transfer Learning,DDTL) [Tan et al.,2017],利用联合矩阵分解和深度神经网络,将迁移学习应用于多个不相似的领域之间的知识共享,取得了良好的效果。
虽然实例权重法具有较好的理论支撑、容易推导泛化误差上界,但这类方法通常只在领域间分布差异较小时有效,因此对自然语言处理、计算机视觉等任务效果并不理想。而基于特征表示的迁移学习方法效果更好,是我们研究的重点。
11.2.2 基于特征迁移
基于特征的迁移方法(Feature based Transfer Learning)是指通过特征变换的方式互相迁移 [Liu et al.,2011, Zheng et al.,2008, Hu and Yang 2011] 来减少源域和目标域之间的差距;或者将源域和目标域的数据特征变换到统一特征空间中 [Pan et al.,2011, Long et al.,2014b, Duan et al.,2012], 然后利用传统的机器学习方法进行分类识别。根据特征的同构和异构性,又可以分为同构和异构迁移学习。图15很形象地表示了两种基于特征的迁移学习方法。
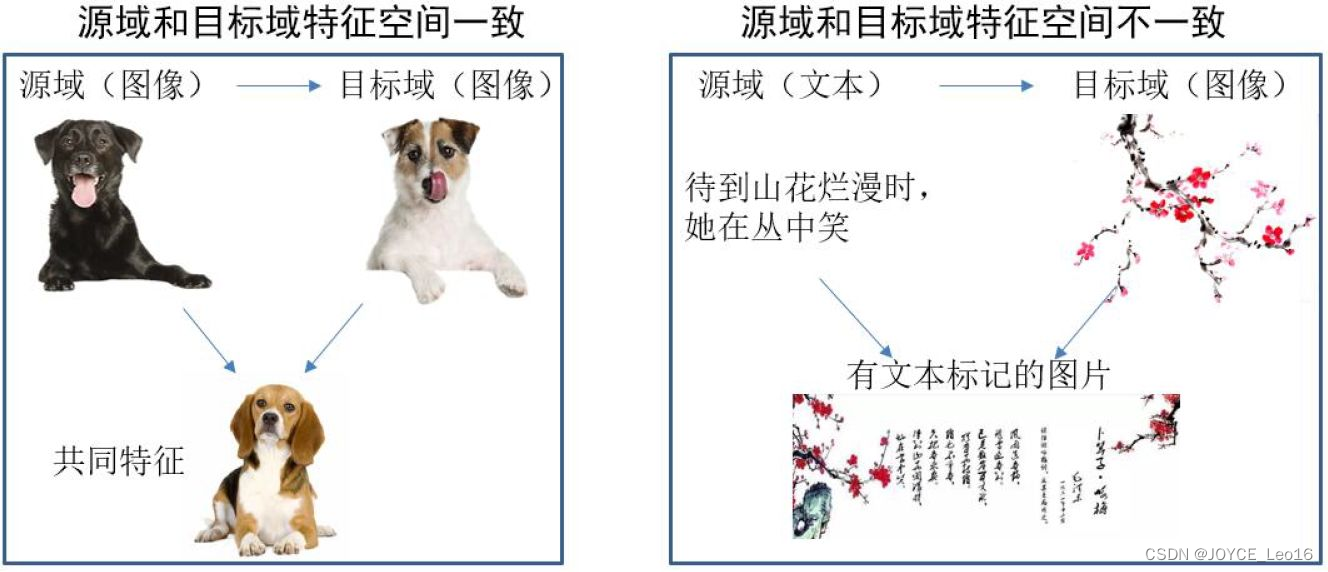
图15 基于特征的迁移学习方法示意图
基于特征的迁移学习方法是迁移学习领域中最热门的研究方法,这类方法通常假设源域和目标域之间有一些交叉的特征。香港科技大学的Pan等人[Pan et al.,2011] 提出的迁移成分分析方法(Transfer Component Analysis,TCA)是其中较为经典的一个方法。该方法的核心内容是以最大均值方差异(Maximum MeanDiscrepancy, MMD)[Borgwardt et al.,2006] 作为度量准则,将不同数据领域中的分布差异最小化。加州大学伯克利分校的Blitzer等人[Blitzer et al.,2006]提出了一种基于结构对应的学习方法(Structural Corresponding Learning,SCL),该算法可以通过映射将一个空间中独有的一些特征变换到其他所有空间中的轴特征上,然后在该特征上使用机器学习的算法进行分类预测。清华大学龙明盛等人[Long et al.,2014b] 提出在最小化分布距离的同时,加入实例选择的迁移联合匹配(Tran-fer Joint Matching, TJM) 方法,将实例和特征迁移学习方法进行了有机的结合。澳大利亚卧龙岗大学的 Jing Zhang 等人[Zhang et al.,2017a]提出对于源域和目标域各自训练不同 的变换矩阵,从而达到迁移学习的目标。
11.2.3 基于模型迁移
基于模型的迁移方法(Parameter/Model based Transfer Learning)是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是:源域中的数据与目标域中的数据可以共享一些模型的参数。其中代表性的工作主要有 [Zhang et al., 2010, Zhao et al.,2011, Pan et al.,2008b, Pan et al.,2008a]。图16形象地表示了基于模型的迁移学习方法的基本思想。
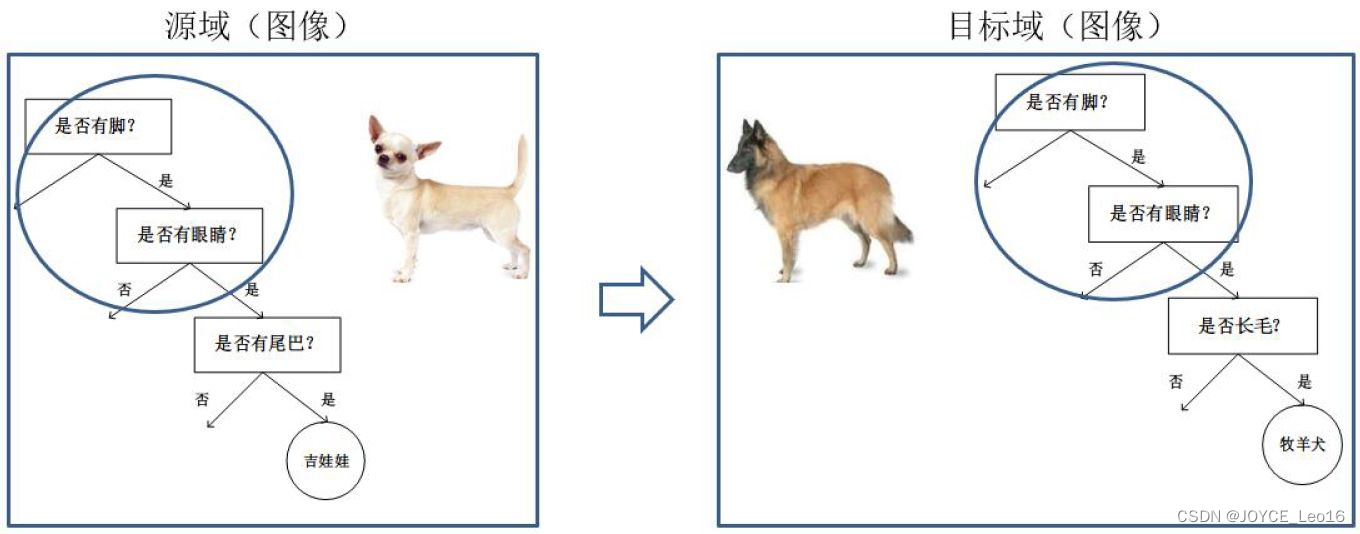
图16 基于模型的迁移学习方法示意图
其中,中科院计算所的Zhao等人[Zhao et al.,2011]提出了TransEMDT方法。该方法首先针对已有标记的数据,利用决策树构建鲁棒性的行为识别模型,然后针对无标定数据,利用K-Means聚类方法寻找最优化的标定参数。西安邮电大学的Deng等人[Deng et al.,2014]也用超限学习机做了类似的工作。香港科技大学的Pan等人[Pan et al.,2008a]利用HMM,针对Wifi室内定位在不同设备、不同时间和不同空间下动态变化的特点,进行不同分布下的室内定位研究。另一部分研究人员对支持向量机 SVM 进行了改进研究 [Nater et al.,2011, Li et al.,2012]。这些方法假定 SVM中的权重向量 w 可以分成两个部分: w = wo+v, 其中 w0代表源域和目标域的共享部分, v 代表了对于不同领域的特定处理。在最新的研究成果中,香港科技大学的 Wei 等人 [Wei et al.,2016b]将社交信息加入迁移学习方法的 正则项中,对方法进行了改进。清华大学龙明盛等人[Long et al.,2015a, Long et al.,2016, Long et al.,2017]改进了深度网络结构,通过在网络中加入概率分布适配层,进一步提高了深度迁移学习网络对于大数据的泛化能力。
11.2.4 基于关系迁移
基于关系的迁移学习方法(Relation Based Transfer Learning)与上述三种方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关系。图17形象地表示了不同领域之间相似的关系。
就目前来说,基于关系的迁移学习方法的相关研究工作非常少,仅有几篇连贯式的文章讨论:[Mihakova et al.,2007, Mihakova and Mooney,2008, Davis]。这些文章都借助于马尔科夫逻辑网络(Markov Logic Net)来挖掘不同领域之间的关系相似性。
我们将重点讨论基于特征和基于模型的迁移学习方法,这也是目前绝大多数研究工作的热点。

图17 基于关系的迁移学习方法示意图
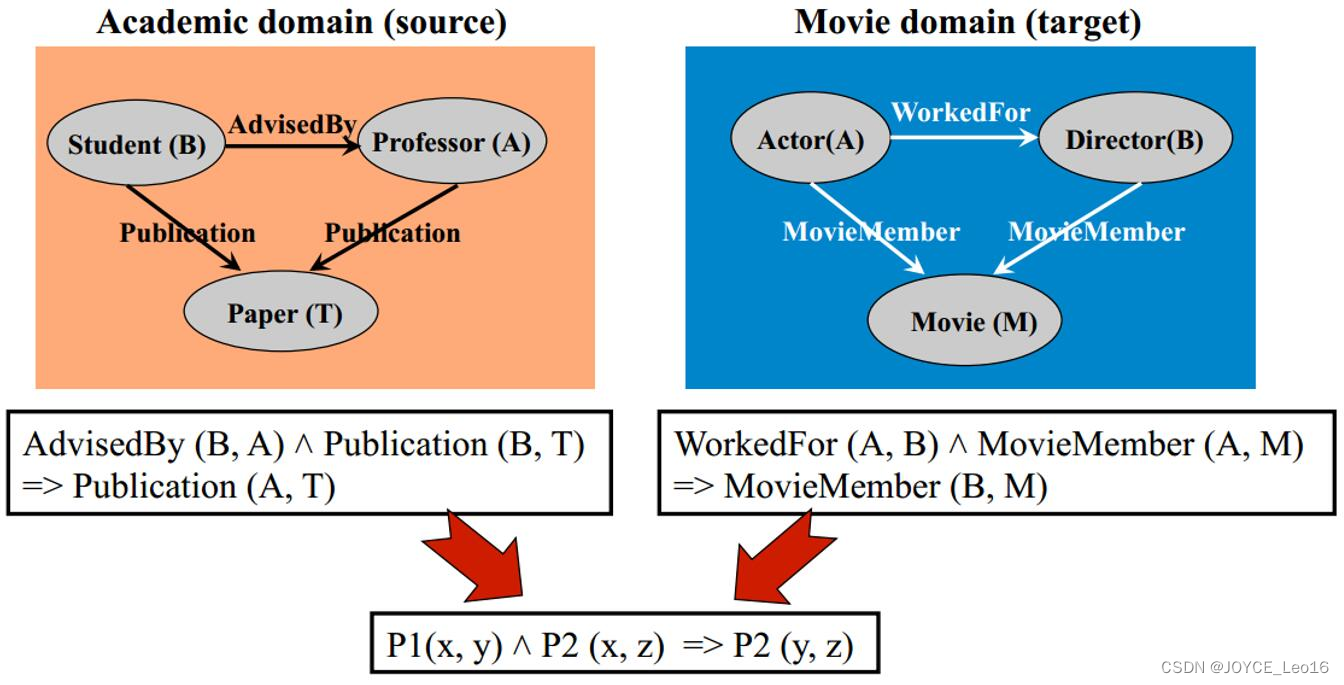
图18 基于马尔科夫逻辑网的关系迁移
















 7320
7320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











