









课程内容
什么是Seq2Seq
Seq2Seq应用场景
Seq2Seq结构及原理
Seq2Seq案例
Seq2Seq实战
什么是Seq2Seq
Seq2Seq技术,全称Sequence to Sequence,它被提出于2014年,最早由两篇文章独立地阐述了它主要思想,分别是Google Brain团队的《Sequence to Sequence Learning with Neural Networks》和Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。这两篇文章不谋而合地提出了相似的解决思路,Seq2Seq由此产生。
Encoder-Decoder 这种结构的,其中Encoder 是一个RNNCell(RNN ,GRU,LSTM 等)结构。每个timestep,我们向Encoder 中输入一个字/词(一般是表示这个字/词的一个实数向量),直到我们输入这个句子的最后一个字/词XT ,然后输出整个句子的语义向量c(一般情况下,c=hXT, XT 是最后一个输入)。因为RNN 的特点就是把前面每一步的输入信息都考虑进来了,所以理论上这个c 就能够把整个句子的信息都包含了,我们可以把c 当成这个句子的一个语义表示,也就是一个句向量。在Decoder 中,我们根据Encoder 得到的句向量c,一步一步地把蕴含在其中的信息分析出来。
在Encoder 中我们得到了一个涵盖了整个句子信息的实数向量c ,现在我们一步一步的从c 中抽取信息。首先给Decoder 输入一个启动信号y0(如特殊符号), 然后Decoder 根据h<0>,y0,c ,就能够计算出y1 的概率分布了,同理,根据h<1>,y1,c 可以计算y2 的概率分布…以此类推直到预测到结束的特殊标志,才结束预测。
中间语义c 不仅仅只作用于decoder 的第1 个时刻,而是每个时刻都有c 输入。
在机器翻译:输入(hello)-> 输出(你好)。输入是1个英文单词,输出为2个汉字。在对话机器中:我们提(输入)一个问题,机器会自动生成(输出)回答。在以往的很多模型中,我们一般都说输入特征矩阵,每个样本对应矩阵中的某一行。就是说,无论是第一个样本还是最后一个样本,他们都有一样的特征维度。
在Seq2Seq模型中采用了这种Encoder-Decoder架构,Encoder 最后输出的中间语义只作用于Decoder 的第一个时刻,这样子模型理解起来其实要比Encoder-Decoder 更容易一些。
下图展示的是一个邮件对话的应用场景,图中的Encoder 和Decoder 都只展示了一层的普通的LSTMCell。从上面的结构中,我们可以看到,整个模型结构还是非常简单的。EncoderCell最后一个时刻的状态[cXT,hXT] 就是上面说的中间语义向量c ,它将作为DecoderCell的初始状态。然后在DecoderCell中,每个时刻的输出将会作为下一个时刻的输入。以此类推,直到DecoderCell某个时刻预测输出特殊符号 结束。
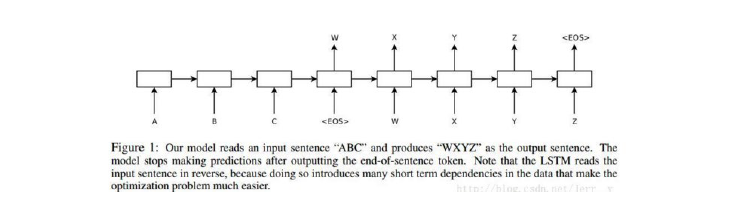
在原论文中,下面的Encoder 和Decoder 都是4 层的LSTM,但是原理其实和1 层LSTM 是一样的。原文有个小技巧,将源句子顺序颠倒后再输入Encoder 中,比如源句子为“A B C”,那么输入Encoder 的顺序为“C B A”,经过这样的处理后,取得了很大的提升,而且这样的处理使得模型能够很好地处理长句子。

















 3001
3001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











