









Seq2Seq with attention
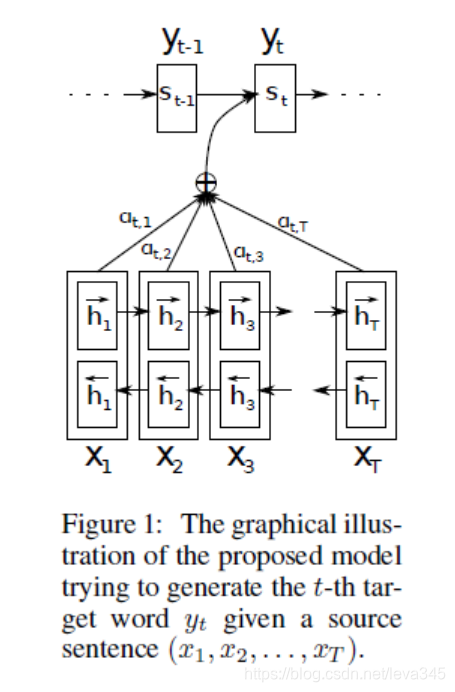
LSTM模型虽然具有记忆性,但是当Encoder阶段输入序列过长时,解码阶段的LSTM也无法很好地针对最早的输入序列解码。基于此,Attention注意力分配的机制被提出,就是为了解决这个问题。在Decoder阶段每一步解码,都能够有一个输入,对输入序列所有隐藏层的信息h_1,h_2,…h_Tx进行加权求和。打个比方就是每次在预测下一个词时都会把所有输入序列的隐藏层信息都看一遍,决定预测当前词时和输入序列的那些词最相关。
Attention机制代表了在解码Decoder阶段,每次都会输入一个Context上下文的向量Ci, 隐藏层的新状态Si根据上一步的状态Si-1, Yi, Ci 三者的一个非线性函数得出。
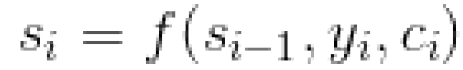
Context向量在解码的每一步都会重新计算,根据一个MLP模型计算出输出序列i对每个输入序列j的隐含层的对应权重aij,并对所有隐含层加权平均。文章中说的Alignment Model就是代表这种把输入序列位置j和输出序列位置i建立关系的模型。
Context向量在解码的每一步都会重新计算,根据一个MLP模型计算出输出序列i对每个输入序列j的隐含层的对应权重aij,并对所有隐含层加权平均。文章中说的Alignment Model就是代表这种把输入序列位置j和输出序列位置i建立关系的模型
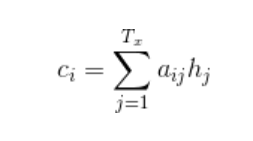
aij即可以理解为encoder编码输出序列的第i步,对输入序列第j步分配的注意力权重。
eij为一个简单的MLP模型激活的输出;aij的计算是对eij做softmax归一化后的结果。
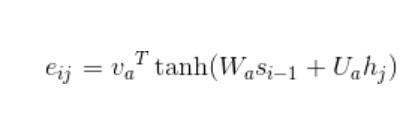
















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











