







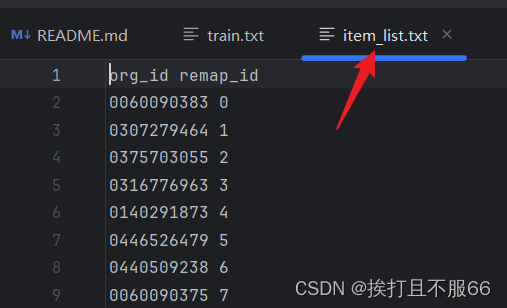
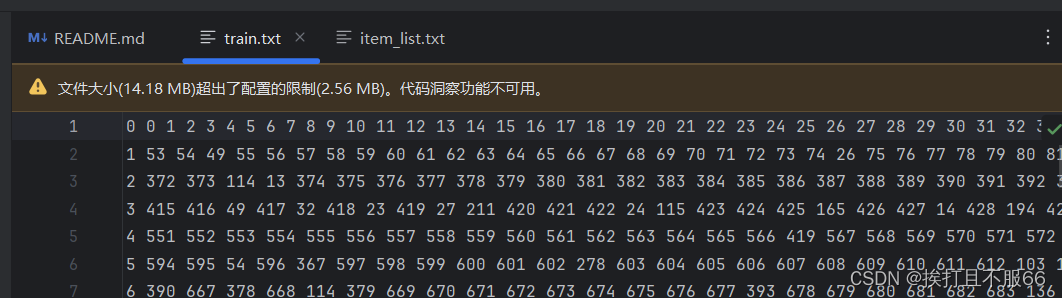
在推荐系统中,像Amazon-Book这样的数据集通常包含用户和物品的交互信息。为了训练模型,这些数据需要转换成适合模型输入的格式。在这种情况下,item_list和user_list需要转换成train.txt文件,通常包含用户ID和物品ID的交互记录。
以下是一个大致的步骤和原因:
-
数据预处理:
- 用户和物品ID映射: 将用户和物品ID转换为连续的数字ID。这是因为许多推荐系统模型(例如矩阵分解、嵌入模型)要求输入是连续的整数ID。这样可以更高效地进行矩阵操作和内存管理。
- 去重和过滤: 去除重复的交互记录和过滤掉低频用户或物品,以减少噪音和提高训练效果。
-
生成交互记录:
- 构建用户-物品对: 遍历用户和他们的交互记录,生成用户-物品对,每一行代表一个用户与一个物品的交互。
-
写入train.txt文件:
- 格式化输出: 将用户ID和物品ID按照一定的格式写入
train.txt文件。通常每一行代表一个用户及其交互的物品列表,格式如下:
例如:user_id item_id_1 item_id_2 ... item_id_n1 10 23 45 67 2 12 34 3 45 67 89
- 格式化输出: 将用户ID和物品ID按照一定的格式写入
为什么train.txt中的ID是连续数字且后边长短不一:
- 连续数字ID: 使用连续数字ID的原因是这些ID可以直接用于矩阵索引,提高计算效率并减少存储开销。
- 长短不一的数字列表: 每个用户与不同数量的物品有交互,因此在文件中每个用户后面对应的物品ID数量不一。这种格式可以灵活地表示每个用户的交互记录,而不需要预先定义固定的长度。
示例代码:
以下是一个简单的Python示例代码,将user_list和item_list转换为train.txt:
import pandas as pd
# 示例数据
user_list = [1, 2, 3]
item_list = [[10, 23, 45, 67], [12, 34], [45, 67, 89]]
# 创建用户-物品对
data = {'user_id': user_list, 'item_list': item_list}
# 将数据转换为DataFrame
df = pd.DataFrame(data)
# 将DataFrame写入train.txt
with open('train.txt', 'w') as f:
for _, row in df.iterrows():
line = f"{row['user_id']} " + " ".join(map(str, row['item_list'])) + "\n"
f.write(line)
这段代码将用户和物品列表写入train.txt文件,每一行代表一个用户及其交互的物品列表。


















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









