







MapReduce工作流程的经典流程如图所示
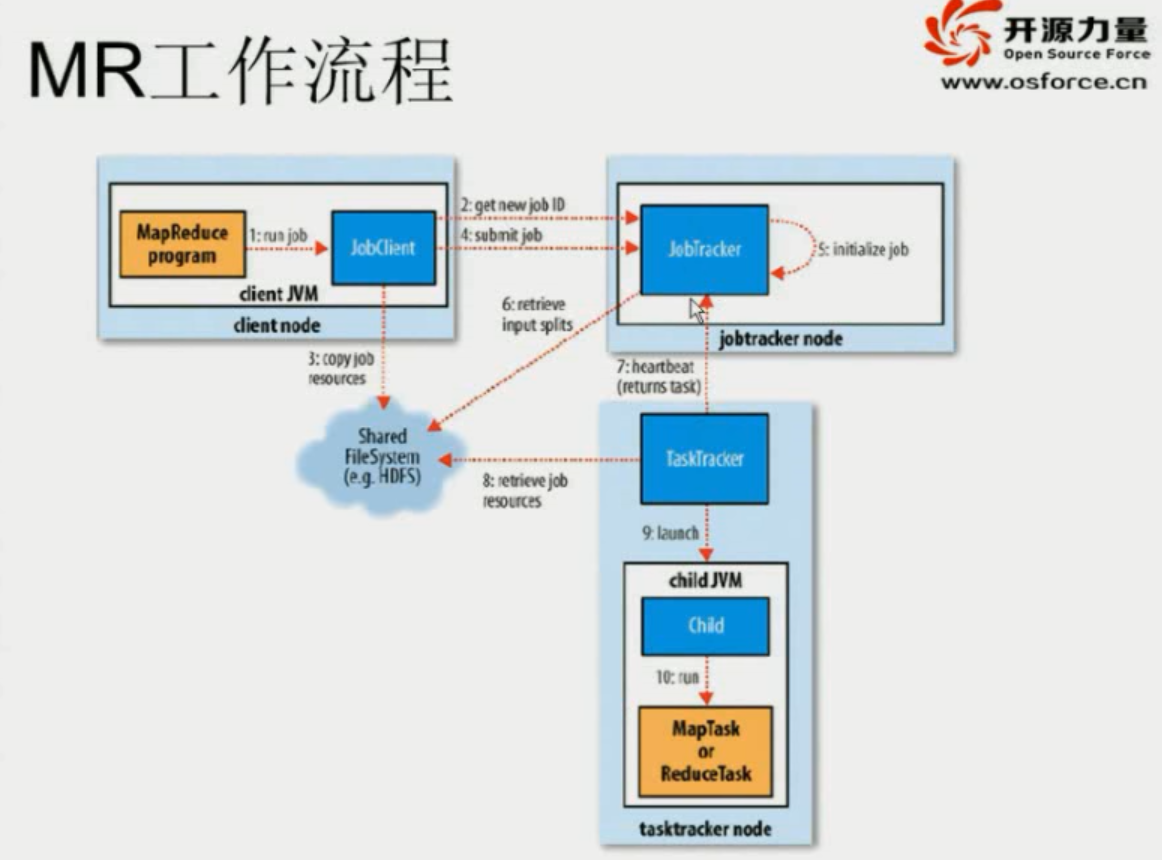
1)作业配置
当用户程序写下如下代码时
Job job = new Job(conf,"word count") ;
System.exit(job.waitForCompletion(true)?0:1) ;job.waitForCompletion(true)是调用org.apache.hadoop.mapreduce.Job.java中的waitForCompletion方法
/**
* Submit the job to the cluster and wait for it to finish.
* @param verbose print the progress to the user
* @return true if the job succeeded
* @throws IOException thrown if the communication with the
* <code>JobTracker</code> is lost
*/
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) {
jobClient.monitorAndPrintJob(conf, info);
} else {
info.waitForCompletion();
}
return isSuccessful();
}调用org.apache.hadoop.mapreduce.Job.java中的submit方法
/**
* Submit the job to the cluster and return immediately.
* @throws IOException
*/
public void submit() throws IOException, InterruptedException,
ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
// Connect to the JobTracker and submit the job
connect();
info = jobClient.submitJobInternal(conf);
super.setJobID(info.getID());
state = JobState.RUNNING;
}然后调用了jobClient.submitJobInternal(conf);对作业进行提交。。。submitJobInternal是在JobTracker中实现的。。。
2)提交作业
在org.apache.hadoop.mapred.JobClient.java的submitJobInternal方法中
1、向jobtracker请求,getNewJobId
JobID jobId = jobSubmitClient.getNewJobId();//JobTracker中实现了getNewJobId()2、检查job的相关输出路径,提交job以及相关的jar到jobtracker,相关的libjars是通过distributedCache方式传递到jobtracker
copyAndConfigureFiles(jobCopy, submitJobDir);通常而言,对于一个典型的Java MapReduce作业,可能包含以下资源。
a)程序jar包:用户用Java编写的MapReduce应用程序jar包
b)作业配置文件:描述MapReduce应用程序的配置信息(根据JobConf对象生成的xml文件)。
c)依赖的第三方jar包:应用程序依赖的第三方jar包,提交作业时用参数“-libjars”指定
d)依赖的归档文件:应用程序中用到多个文件,可直接打包成归档文件(通常为一些压缩文件),提交作业时用参数“-archives”指定。
e)依赖的普通文件:应用程序中可能用到普通文件,比如文本格式的字典文件,提交作业时用参数“-files”指定。
3、jobClient计算输入分片,把splitMetaInfo写入JobSplit
int maps = writeSplits(context, submitJobDir);writeSplits调用writeNewSplits,writeNewSplits调用getSplit方法生成InputSplit信息
List<InputSplit> splits = input.getSplits(job);writeNewSplits调用createSplitFiles将InputSplit信息写入文件中。
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);4、把job.xml配置文件发送到JobTracker
jobCopy.writeXml(out);5、调用JobSubmissionProtocol的submitJob方法真正去提交作业
status = jobSubmitClient.submitJob(
jobId, submitJobDir.toString(), jobCopy.getCredentials());//调用的是JobTracker中的submitJob方法3)作业初始化
1、创建一个代表正在运行作业的对象JobInprogress
2、JobTracker接收到Client的submitJob()方法调用后,会把调用放到内部队列中,交由TaskScheduler调度,由调度器按照一定的策略对作业进行初始化。
我们首先来分析JobTracker如何将“提交新作业”这一事件通知TaskScheduler,JobTracker采用的是观察者设计模式(也称为发布-订阅模式)
org.apache.hadoop.mapred.JobTracker.java中首先启动JobTracker
/**
* Start the JobTracker process. This is used only for debugging. As a rule,
* JobTracker should be run as part of the DFS Namenode process.
*/
public static void main(String argv[]
) throws IOException, InterruptedException {
StringUtils.startupShutdownMessage(JobTracker.class, argv, LOG);
try {
if(argv.length == 0) {
JobTracker tracker = startTracker(new JobConf());
tracker.offerService();
}
else {
if ("-dumpConfiguration".equals(argv[0]) && argv.length == 1) {
dumpConfiguration(new PrintWriter(System.out));
}
else {
System.out.println("usage: JobTracker [-dumpConfiguration]");
System.exit(-1);
}
}
} catch (Throwable e) {
LOG.fatal(StringUtils.stringifyException(e));
System.exit(-1);
}
}调用了startTracker方法。。。
public static JobTracker startTracker(JobConf conf, String identifier, boolean initialize)
throws IOException, InterruptedException {
DefaultMetricsSystem.initialize("JobTracker");
JobTracker result = null;
while (true) {
try {
result = new JobTracker(conf, identifier);
result.taskScheduler.setTaskTrackerManager(result);
break;
} catch (VersionMismatch e) {
throw e;
} catch (BindException e) {
throw e;
} catch (UnknownHostException e) {
throw e;
} catch (AccessControlException ace) {
// in case of jobtracker not having right access
// bail out
throw ace;
} catch (IOException e) {
LOG.warn("Error starting tracker: " +
StringUtils.stringifyException(e));
}
Thread.sleep(1000);
}
if (result != null) {
JobEndNotifier.startNotifier();
MBeans.register("JobTracker", "JobTrackerInfo", result);
if(initialize == true) {
result.setSafeModeInternal(SafeModeAction.SAFEMODE_ENTER);
result.initializeFilesystem();
result.setSafeModeInternal(SafeModeAction.SAFEMODE_LEAVE);
result.initialize();
}
}
return result;
}大家注意这一句代码
result.taskScheduler.setTaskTrackerManager(result);这个setTaskTrackerManage是继承自org.apache.hadoop.mapred.TaskScheduler.java中的setTaskTrackerManage,这个方法将JobTrack对象与TaskTrackerManager对象画上了等号,也就是说taskTrackerManager实际上就是JobTracker对象。
public synchronized void setTaskTrackerManager(
TaskTrackerManager taskTrackerManager) {
this.taskTrackerManager = taskTrackerManager;
}在该发布-订阅模式中,JobTracker是被观察对象,而JobInProgressListener是观察者
在上面的org.apache.hadoop.mapred.JobTracker.java的main方法中有这么一段代码
tracker.offerService();在offerService中调用org.apache.hadoop.mapred.TaskScheduler.java中的start()方法。。。
在start方法中,调度器会向JobTracker注册JobInProgressListener对象以监听作业的添加、删除、更新等事件。以默认调度器JobQueueTaskScheduler为例,它的start方法如下:
@Override
public synchronized void start() throws IOException {
super.start();
//此处的taskTrackerManager实际上就是JobTracker对象,向JobTracker注册一个JobQueueJobInProgressListener
taskTrackerManager.addJobInProgressListener(jobQueueJobInProgressListener);
eagerTaskInitializationListener.setTaskTrackerManager(taskTrackerManager);
eagerTaskInitializationListener.start();
//向JobTracker注册EagerTaskInitializationListener
taskTrackerManager.addJobInProgressListener(
eagerTaskInitializationListener);
}3、TaskScheduler初始化作业,JobInProgress的initTasks()方法初始化工作:
a)读取作业的分片信息,每一个输入分片对应一个Map Task
b)创建Map任务与Reduce任务,为每一个Map Task和Reduce Task生成TaskInProgress对象,
c)reduce的数量由mapred.reduce.tasks属性决定,而map的数量是由输入分片的个数决定的
4)任务分配
a)JobTracker与TaskTracker之间的通信与任务分配是通过心跳机制完成的
b)TaskTracker会主动向JobTracker询问是否有作业,如果自己有空闲的slot,就可以在心跳阶段得到JobTracker发送过来的Map任务或Reduce任务
c)TaskTracker->transmitHeartBeat
在org.apache.hadoop.mapred.TaskTracker.java中的transmitHeartBeat方法
/**
* Build and transmit the heart beat to the JobTracker
* @param now current time
* @return false if the tracker was unknown
* @throws IOException
*/
HeartbeatResponse transmitHeartBeat(long now) throws IOException {
// Send Counters in the status once every COUNTER_UPDATE_INTERVAL
boolean sendCounters;
if (now > (previousUpdate + COUNTER_UPDATE_INTERVAL)) {
sendCounters = true;
previousUpdate = now;
}
else {
sendCounters = false;
}
//
// Check if the last heartbeat got through...
// if so then build the heartbeat information for the JobTracker;
// else resend the previous status information.
//
if (status == null) {
synchronized (this) {
status = new TaskTrackerStatus(taskTrackerName, localHostname,
httpPort,
cloneAndResetRunningTaskStatuses(
sendCounters),
taskFailures,
localStorage.numFailures(),
maxMapSlots,
maxReduceSlots);
}
} else {
LOG.info("Resending 'status' to '" + jobTrackAddr.getHostName() +
"' with reponseId '" + heartbeatResponseId);
}
//
// Check if we should ask for a new Task
//
boolean askForNewTask;
long localMinSpaceStart;
synchronized (this) {
askForNewTask =
((status.countOccupiedMapSlots() < maxMapSlots ||
status.countOccupiedReduceSlots() < maxReduceSlots) &&
acceptNewTasks);
localMinSpaceStart = minSpaceStart;
}
if (askForNewTask) {
askForNewTask = enoughFreeSpace(localMinSpaceStart);
long freeDiskSpace = getFreeSpace();
long totVmem = getTotalVirtualMemoryOnTT();
long totPmem = getTotalPhysicalMemoryOnTT();
long availableVmem = getAvailableVirtualMemoryOnTT();
long availablePmem = getAvailablePhysicalMemoryOnTT();
long cumuCpuTime = getCumulativeCpuTimeOnTT();
long cpuFreq = getCpuFrequencyOnTT();
int numCpu = getNumProcessorsOnTT();
float cpuUsage = getCpuUsageOnTT();
status.getResourceStatus().setAvailableSpace(freeDiskSpace);
status.getResourceStatus().setTotalVirtualMemory(totVmem);
status.getResourceStatus().setTotalPhysicalMemory(totPmem);
status.getResourceStatus().setMapSlotMemorySizeOnTT(
mapSlotMemorySizeOnTT);
status.getResourceStatus().setReduceSlotMemorySizeOnTT(
reduceSlotSizeMemoryOnTT);
status.getResourceStatus().setAvailableVirtualMemory(availableVmem);
status.getResourceStatus().setAvailablePhysicalMemory(availablePmem);
status.getResourceStatus().setCumulativeCpuTime(cumuCpuTime);
status.getResourceStatus().setCpuFrequency(cpuFreq);
status.getResourceStatus().setNumProcessors(numCpu);
status.getResourceStatus().setCpuUsage(cpuUsage);
}
//add node health information
TaskTrackerHealthStatus healthStatus = status.getHealthStatus();
synchronized (this) {
if (healthChecker != null) {
healthChecker.setHealthStatus(healthStatus);
} else {
healthStatus.setNodeHealthy(true);
healthStatus.setLastReported(0L);
healthStatus.setHealthReport("");
}
}
//
// Xmit the heartbeat
//
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(status,
justStarted,
justInited,
askForNewTask,
heartbeatResponseId);
//
// The heartbeat got through successfully!
//
heartbeatResponseId = heartbeatResponse.getResponseId();
synchronized (this) {
for (TaskStatus taskStatus : status.getTaskReports()) {
if (taskStatus.getRunState() != TaskStatus.State.RUNNING &&
taskStatus.getRunState() != TaskStatus.State.UNASSIGNED &&
taskStatus.getRunState() != TaskStatus.State.COMMIT_PENDING &&
!taskStatus.inTaskCleanupPhase()) {
if (taskStatus.getIsMap()) {
mapTotal--;
} else {
reduceTotal--;
}
myInstrumentation.completeTask(taskStatus.getTaskID());
runningTasks.remove(taskStatus.getTaskID());
}
}
// Clear transient status information which should only
// be sent once to the JobTracker
for (TaskInProgress tip: runningTasks.values()) {
tip.getStatus().clearStatus();
}
}
// Force a rebuild of 'status' on the next iteration
status = null;
return heartbeatResponse;
}注意这一句代码
HeartbeatResponse heartbeatResponse = jobClient.heartbeat(status,
justStarted,
justInited,
askForNewTask,
heartbeatResponseId);tasktracker在一系列检查之后,会调用jobTracker的heartbeat方法。
org.apache.hadoop.mapred.JobTracker.java中的heartbeat方法如下所示
/**
* The periodic heartbeat mechanism between the {@link TaskTracker} and
* the {@link JobTracker}.
*
* The {@link JobTracker} processes the status information sent by the
* {@link TaskTracker} and responds with instructions to start/stop
* tasks or jobs, and also 'reset' instructions during contingencies.
*/
public synchronized HeartbeatResponse heartbeat(TaskTrackerStatus status,
boolean restarted,
boolean initialContact,
boolean acceptNewTasks,
short responseId)
throws IOException {
if (LOG.isDebugEnabled()) {
LOG.debug("Got heartbeat from: " + status.getTrackerName() +
" (restarted: " + restarted +
" initialContact: " + initialContact +
" acceptNewTasks: " + acceptNewTasks + ")" +
" with responseId: " + responseId);
}
// Make sure heartbeat is from a tasktracker allowed by the jobtracker.
if (!acceptTaskTracker(status)) {
throw new DisallowedTaskTrackerException(status);
}
// First check if the last heartbeat response got through
String trackerName = status.getTrackerName();
long now = clock.getTime();
if (restarted) {
faultyTrackers.markTrackerHealthy(status.getHost());
} else {
faultyTrackers.checkTrackerFaultTimeout(status.getHost(), now);
}
HeartbeatResponse prevHeartbeatResponse =
trackerToHeartbeatResponseMap.get(trackerName);
boolean addRestartInfo = false;
if (initialContact != true) {
// If this isn't the 'initial contact' from the tasktracker,
// there is something seriously wrong if the JobTracker has
// no record of the 'previous heartbeat'; if so, ask the
// tasktracker to re-initialize itself.
if (prevHeartbeatResponse == null) {
// This is the first heartbeat from the old tracker to the newly
// started JobTracker
if (hasRestarted()) {
addRestartInfo = true;
// inform the recovery manager about this tracker joining back
recoveryManager.unMarkTracker(trackerName);
} else {
// Jobtracker might have restarted but no recovery is needed
// otherwise this code should not be reached
LOG.warn("Serious problem, cannot find record of 'previous' " +
"heartbeat for '" + trackerName +
"'; reinitializing the tasktracker");
return new HeartbeatResponse(responseId,
new TaskTrackerAction[] {new ReinitTrackerAction()});
}
} else {
// It is completely safe to not process a 'duplicate' heartbeat from a
// {@link TaskTracker} since it resends the heartbeat when rpcs are
// lost see {@link TaskTracker.transmitHeartbeat()};
// acknowledge it by re-sending the previous response to let the
// {@link TaskTracker} go forward.
if (prevHeartbeatResponse.getResponseId() != responseId) {
LOG.info("Ignoring 'duplicate' heartbeat from '" +
trackerName + "'; resending the previous 'lost' response");
return prevHeartbeatResponse;
}
}
}
// Process this heartbeat
short newResponseId = (short)(responseId + 1);
status.setLastSeen(now);
if (!processHeartbeat(status, initialContact, now)) {
if (prevHeartbeatResponse != null) {
trackerToHeartbeatResponseMap.remove(trackerName);
}
return new HeartbeatResponse(newResponseId,
new TaskTrackerAction[] {new ReinitTrackerAction()});
}
// Initialize the response to be sent for the heartbeat
HeartbeatResponse response = new HeartbeatResponse(newResponseId, null);
List<TaskTrackerAction> actions = new ArrayList<TaskTrackerAction>();
boolean isBlacklisted = faultyTrackers.isBlacklisted(status.getHost());
// Check for new tasks to be executed on the tasktracker
if (recoveryManager.shouldSchedule() && acceptNewTasks && !isBlacklisted) {
TaskTrackerStatus taskTrackerStatus = getTaskTrackerStatus(trackerName);
if (taskTrackerStatus == null) {
LOG.warn("Unknown task tracker polling; ignoring: " + trackerName);
} else {
List<Task> tasks = getSetupAndCleanupTasks(taskTrackerStatus);
if (tasks == null ) {
tasks = taskScheduler.assignTasks(taskTrackers.get(trackerName));
}
if (tasks != null) {
for (Task task : tasks) {
expireLaunchingTasks.addNewTask(task.getTaskID());
if(LOG.isDebugEnabled()) {
LOG.debug(trackerName + " -> LaunchTask: " + task.getTaskID());
}
actions.add(new LaunchTaskAction(task));
}
}
}
}
// Check for tasks to be killed
List<TaskTrackerAction> killTasksList = getTasksToKill(trackerName);
if (killTasksList != null) {
actions.addAll(killTasksList);
}
// Check for jobs to be killed/cleanedup
List<TaskTrackerAction> killJobsList = getJobsForCleanup(trackerName);
if (killJobsList != null) {
actions.addAll(killJobsList);
}
// Check for tasks whose outputs can be saved
List<TaskTrackerAction> commitTasksList = getTasksToSave(status);
if (commitTasksList != null) {
actions.addAll(commitTasksList);
}
// calculate next heartbeat interval and put in heartbeat response
int nextInterval = getNextHeartbeatInterval();
response.setHeartbeatInterval(nextInterval);
response.setActions(
actions.toArray(new TaskTrackerAction[actions.size()]));
// check if the restart info is req
if (addRestartInfo) {
response.setRecoveredJobs(recoveryManager.getJobsToRecover());
}
// Update the trackerToHeartbeatResponseMap
trackerToHeartbeatResponseMap.put(trackerName, response);
// Done processing the hearbeat, now remove 'marked' tasks
removeMarkedTasks(trackerName);
return response;
}status:该参数封装了TaskTracker上的各种状态信息,包括
String trackerName;//TaskTracker名称,形式如tracker_mymachine:localhost。localdomain/127.0.0.1:34196
String host;//TaskTracker主机名
int httpPort;//TaskTracker对外的HTTP端口号
int taskFailures;//该TaskTracker上已经失败的任务总数
List<TaskStatus> taskReports;//正在运行的各个任务运行状态
volatile long lastSeen;//上次汇报心跳的时间
private int maxMapTasks;//Map slot总数,即允许同时运行的Map Task总数,由参数mapred.tasktracker.map.tasks.maximum设定
private int maxReduceTasks;//Reduce slot总数
private TaskTrackerHealthStatus healthStatus;//TaskTracker健康状态
private ResourceStatus resStatus;//TaskTracker资源(内存,CPU等)信息restarted:表示TaskTracker是否刚刚重新启动。
initialContact:表示TaskTracker是否初次连接JobTracker
acceptNewTasks:表示TaskTracker是否可以接收新任务,这通常取决于slot是否有剩余和节点健康状况等
responseId:表示心跳响应编号,用于防止重复发送心跳。每接收一次心跳后,该值加1
该函数的返回值为一个HeartbeatResponse对象,该对象主要封装了JobTracker向TaskTracker下达的命令。
class HeartbeatResponse implements Writable, Configurable {
short responseId;//心跳响应编号
int heartbeatInterval;//下次心跳的发送间隔
TaskTrackerAction[] actions;//来自JobTracker的命令,可能包括杀死作业、杀死任务、提交任务、运行任务等。
Set<JobID> recoveredJobs = new HashSet<JobID>();//恢复完成的作业列表。JobTracker将下达给TaskTracker的命令封装成TaskTrackerAction类,主要包括ReinitTrackerAction(重新初始化)、LaunchTaskAction(运行新任务)、KillTaskAction(杀死任务)、KillJobAction(杀死作业)和CommitTaskAction(提交任务)五种。
在org.apache.hadoop.mapred.TaskTrackerAction.java
abstract class TaskTrackerAction implements Writable {
/**
* Ennumeration of various 'actions' that the {@link JobTracker}
* directs the {@link TaskTracker} to perform periodically.
*
*/
public static enum ActionType {
/** Launch a new task. */
LAUNCH_TASK,
/** Kill a task. */
KILL_TASK,
/** Kill any tasks of this job and cleanup. */
KILL_JOB,
/** Reinitialize the tasktracker. */
REINIT_TRACKER,
/** Ask a task to save its output. */
COMMIT_TASK
};
/**
* A factory-method to create objects of given {@link ActionType}.
* @param actionType the {@link ActionType} of object to create.
* @return an object of {@link ActionType}.
*/
public static TaskTrackerAction createAction(ActionType actionType) {
TaskTrackerAction action = null;
switch (actionType) {
case LAUNCH_TASK:
{
action = new LaunchTaskAction();
}
break;
case KILL_TASK:
{
action = new KillTaskAction();
}
break;
case KILL_JOB:
{
action = new KillJobAction();
}
break;
case REINIT_TRACKER:
{
action = new ReinitTrackerAction();
}
break;
case COMMIT_TASK:
{
action = new CommitTaskAction();
}
break;
}
return action;
}
private ActionType actionType;
protected TaskTrackerAction(ActionType actionType) {
this.actionType = actionType;
}
/**
* Return the {@link ActionType}.
* @return the {@link ActionType}.
*/
ActionType getActionId() {
return actionType;
}
public void write(DataOutput out) throws IOException {
WritableUtils.writeEnum(out, actionType);
}
public void readFields(DataInput in) throws IOException {
actionType = WritableUtils.readEnum(in, ActionType.class);
}
}d)拷贝所有信息到本地(代码,配置信息,数据分片)
5)任务执行
申请到任务后,tasktracker需要做如下事情:
a)拷贝代码到本地
b)拷贝任务信息到本地
b)启动JVM运行任务
A.代码可以查看TaskTracker->startNewTask->localizeJob,然后调用launchTaskForJob启动taskrunner去执行task
B.TaskRunner分为Map TaskRunner和Reduce TaskRunner
6)进度和状态更新
a)Task在运行过程中,把自己的状态发送给TaskTracker,由TaskTracker再汇报给JobTracker
b)任务进度是通过计数器实现的
7)作业完成
a)JobTracker在接收到最后一个任务完成后,才会将任务标志成成功状态
b)同时会执行把中间结果后删除等操作















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









