






选择案例
在给出的课程实践选题中选择猫狗识别项目:

下载相应数据集

项目实施
1.环境搭建
A.选择项目工具
将jupyter作为本项目的实施工具。
B.安装pytorch框架和所需的第三方库
项目所用库
import os
import sys
import time
import argparse
import itertools
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import intel_extension_for_pytorch as ipex
import pandas as pd
from torch import nn
from torch import optim
from torch.autograd import Variable
from torchvision import models
from matplotlib.patches import Rectangle
from sklearn.metrics import confusion_matrix, accuracy_score, balanced_accuracy_score
from torchvision import transforms
from PIL import Image
from torch.utils.data import Dataset, DataLoader, SubsetRandomSampler
from torchvision import transforms
from sklearn.model_selection import train_test_split, StratifiedKFold
from torch.utils.data import DataLoader
from sklearn.metrics import f1_score
C.配置cuda环境
由于模型在GPU上训练更快,所以需要nvidia的GPU和cuda环境。
打开cmd,输入nvidia-smi查看显卡支持的最大cuda版本
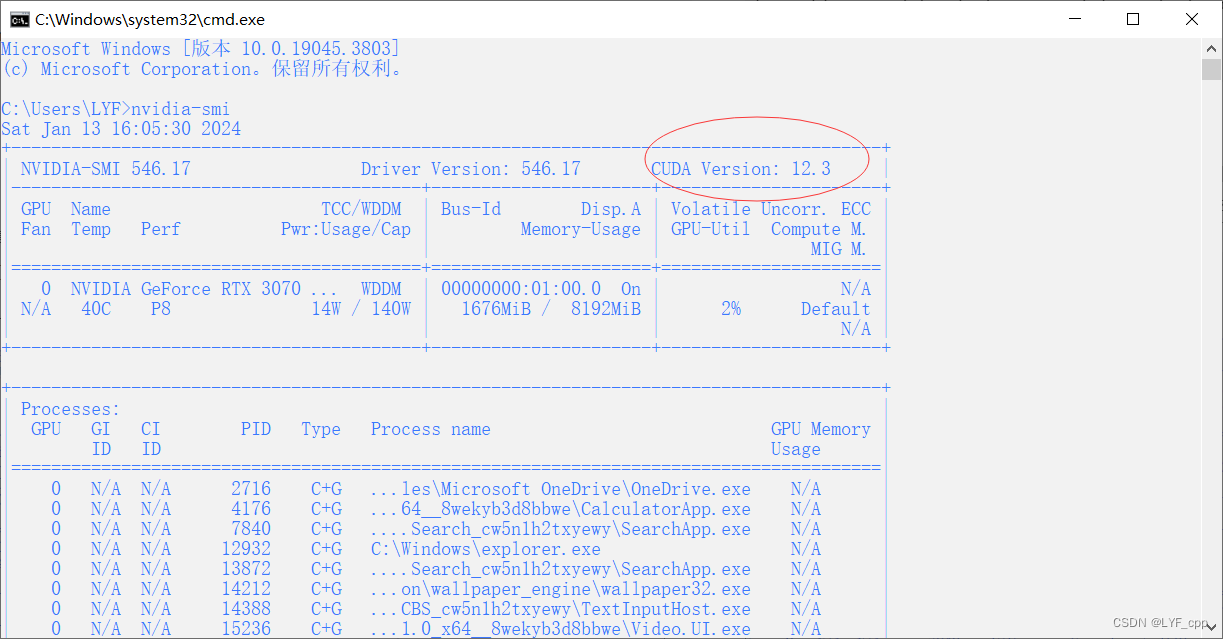
然后去网络上选择合适版本的cuda已经配套的cudnn进行安装
本项目选择cuda11.8

安装完cuda后对cudnn文件进行配置并设置好对应的4个环境变量
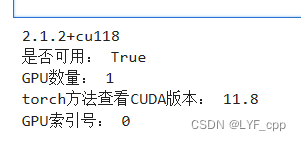
打开jupyterlab,运行以下代码
import torch
print(torch.__version__)
print("是否可用:", torch.cuda.is_available()) # 查看GPU是否可用
print("GPU数量:", torch.cuda.device_count()) # 查看GPU数量
print("torch方法查看CUDA版本:", torch.version.cuda) # torch方法查看CUDA版本
print("GPU索引号:", torch.cuda.current_device()) # 查看GPU索引号
结果:
2.数据集划分
#数据分类,选择猫和狗各13000张作训练集,各100张作测试集
import os
import shutil
root_path = ''
animal = ['cat','dog']
style = ['train','test']
train_data_path = os.path.join(root_path,'train_data')
if not os.path.exists(train_data_path):
os.makedirs(train_data_path)
for f in style:
folder_path = os.path.join(train_data_path,f)
if not os.path.exists(folder_path):
os.makedirs(folder_path)
for name in animal:
under_path = os.path.join(folder_path,name)
if not os.path.exists(under_path):
os.makedirs(under_path)
for filename in os.listdir('train'):
file_path = os.path.join('train',filename)
if os.path.isfile(file_path):
if filename.startswith(name):
contents = filename.split('.')
num = int(contents[1])
if f == 'test' and num >12399:
shutil.copy(file_path,under_path)
elif f == 'train' and num < 13000:#数据集是按顺序排列的所以可以使用这种方法
shutil.copy(file_path,under_path)
3.数据处理
#数据处理
transform = transforms.Compose([
transforms.RandomResizedCrop((224,224)),
transforms.RandomRotation(20),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor()
])#对图片进行变换和数据增强
root = 'train_data'
#添加数据和标签
def addData(path):#添加数据的函数
data = []
animal = ['cat','dog']
for name in animal:
newp = os.path.join(path,name)
if not os.path.exists(newp):
break
if name == 'cat':
label = 0
if name == 'dog':
label = 1
for f in os.listdir(newp):
file_path = os.path.join(newp,f)
data.append([file_path,label])
for f in os.listdir(path):#这个for是为了处理验证集,由于所给的验证集并未按dog和cat的文件夹分开存储,划分数据集如果处理好可以不用,这里我为了省事
if data == None :
break
if f.startswith('dog'):
label = 1
else:
label = 0
file_path = os.path.join(path,f)
data.append([file_path,label])
return data
path1 = os.path.join(root,'train')
path2 = os.path.join(root,'test')
train_data = addData(path1)
test_data = addData(path2)
val = addData('猫狗大战_test')
#重写Dataset类
class MyDataset(Dataset):
def __init__(self,data,transform):
self.data = data
self.transform = transform
def __getitem__(self,item):
img,label = self.data[item]
img = Image.open(img).convert('RGB')
img = self.transform(img)
return img,label
def __len__(self):
return len(self.data)
np.random.shuffle(train_data)
np.random.shuffle(test_data)
train_data_r = MyDataset(train_data,transform = transform)
test_data_r = MyDataset(test_data,transform = transform)
val_r = MyDataset(val,transform = transform)
Trd = DataLoader(dataset=train_data_r, batch_size=64, shuffle=True,num_workers = 0)
Ted = DataLoader(dataset=test_data_r, batch_size=64, shuffle=False,num_workers = 0)
Val = DataLoader(dataset=val_r,batch_size=64,shuffle = False,num_workers=0)
4.选择并构建网络模型
基于对自身水平的考量,选 择了较为简单和常见的CNN网络来进行项目模型的训练

class CNN(nn.Module):#基于参考构建的CNN模型
def __init__(self):
super(CNN, self).__init__()
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=3,
stride=2,
),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
#
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16,
out_channels=32,
kernel_size=3,
stride=2,
),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
#
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=32,
out_channels=64,
kernel_size=3,
stride=2,
),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.fc1 = nn.Linear(3 * 3 * 64, 64)
self.fc2 = nn.Linear(64, 10)
self.out = nn.Linear(10, 2)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.shape[0], -1)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.out(x)
return x
5.训练模型
#选择损失函数和优化器等
from torch.optim.lr_scheduler import StepLR
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
cnn_model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn_model.parameters(), lr=0.001)
scheduler = StepLR(optimizer, step_size=5, gamma=0.1)
#训练
num_epochs = 10#训练次数
for epoch in range(num_epochs):
cnn_model.train()
for images, labels in Trd:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = cnn_model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 学习率调度
scheduler.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
#保存模型
torch.save(vgg_model.state_dict(), 'model/cnn_model.pth')
PS:如果自己的电脑跑得太慢,可以选择如kaggle、谷歌云之类的云平台,将数据集上传后同线下操作同样
在这里我选择了使用kaggle来训练模型

只需要将训练好的模型下载下来即可
6.对训练的模型进行测试,查看推理时间和f1分数
将模型置于intel云平台上进行cpu上的推理测试
https://devcloud.intel.com/oneapi/get_started/
import time
from sklearn.metrics import f1_score
import torch.nn as nn
cnn_model = CNN()
cnn_model.load_state_dict(torch.load('model/cnn_model.pth', map_location=torch.device('cpu')))
cnn_model.eval()
# 测试集性能评估
start_time = time.time()
predictions_list = []
labels_list = []
with torch.no_grad():
for images, labels in Val:
images, labels = images, labels
outputs = cnn_model(images)
_, predictions = torch.max(outputs, 1)
predictions_list.extend(predictions.cpu().numpy())
labels_list.extend(labels.cpu().numpy())
end_time = time.time()
# 计算F1分数
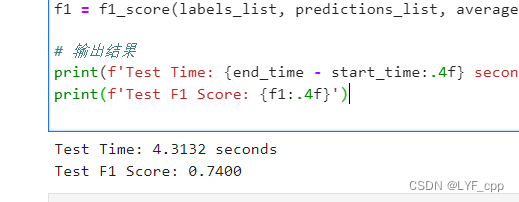
f1 = f1_score(labels_list, predictions_list, average='weighted')
# 输出结果
print(f'Test Time: {end_time - start_time:.4f} seconds')
print(f'Test F1 Score: {f1:.4f}')
结果如下:
7.使用intel oneAPI组件进行模型优化
在云平台上输入以下代码:
cnn_model = CNN()
cnn_model.load_state_dict(torch.load('model/cnn_model.pth', map_location=torch.device('cpu')))
# 重新构建优化器
optimizer = optim.Adam(cnn_model.parameters(), lr=0.001, weight_decay=1e-4)
# 使用Intel Extension for PyTorch进行优化
cnn_model, optimizer = ipex.optimize(model=cnn_model, optimizer=optimizer, dtype=torch.float32)
# 保存模型
torch.save(cnn_model.state_dict(), 'model/cnn_model_intel.pth')
再次进行推理测试:
import time
from sklearn.metrics import f1_score
cnn_model = CNN()
cnn_model.load_state_dict(torch.load('model/cnn_model_intel.pth', map_location=torch.device('cpu')))
cnn_model.eval()
# 测试集性能评估
start_time = time.time()
predictions_list = []
labels_list = []
with torch.no_grad():
for images, labels in Val:
images, labels = images, labels
outputs = cnn_model(images)
_, predictions = torch.max(outputs, 1)
predictions_list.extend(predictions.cpu().numpy())
labels_list.extend(labels.cpu().numpy())
end_time = time.time()
# 计算F1分数
f1 = f1_score(labels_list, predictions_list, average='weighted')
# 输出结果
print(f'Test Time: {end_time - start_time:.4f} seconds')
print(f'Test F1 Score: {f1:.4f}')
结果如下:
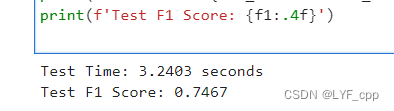
可以发现经过oneAPI组件优化后模型的推理时间有减少,f1分数也有一定的提高
8.使用intel oneAPI组件进行模型量化
在intel平台输入以下代码,将优化后的模型进行量化:
import torch
from neural_compressor.config import PostTrainingQuantConfig, AccuracyCriterion
from neural_compressor import quantization
import os
# 加载模型
model = CNN()
model.load_state_dict(torch.load('model/cnn_model_intel.pth'))
model.to('cpu') # 将模型移动到 CPU
model.eval()
# 定义评估函数
def eval_func(model):
with torch.no_grad():
y_true = []
y_pred = []
for inputs, labels in Val:
inputs = inputs.to('cpu')
labels = labels.to('cpu')
preds_probs = model(inputs)
preds_class = torch.argmax(preds_probs, dim=-1)
y_true.extend(labels.numpy())
y_pred.extend(preds_class.numpy())
return accuracy_score(y_true, y_pred)
# 配置量化参数
conf = PostTrainingQuantConfig(backend='ipex', # 使用 PyTorch 后端
accuracy_criterion=AccuracyCriterion(higher_is_better=True,
criterion='relative',
tolerable_loss=0.01))
# 执行量化
q_model = quantization.fit(model,
conf,
calib_dataloader=Trd,
eval_func=eval_func)
# 保存量化模型
quantized_model_path = 'model/cnn_model_intel_quantized'
if not os.path.exists(quantized_model_path):
os.makedirs(quantized_model_path)
# 保存量化模型
q_model.save(quantized_model_path)
量化前模型大小为:

量化后为:

可以发现量化后模型大小减少了很多
再次进行测试推理:

对比前后变化,量化操作虽然减小了模型大小,但推理时间有一定的变长,f1分数基本维持不变。
项目总结
本次项目实现了基于pytorch框架的CNN网络猫狗识别案例,并使用了intel oneAPI组件进行优化训练所得的模型。
在本次项目实现中,可以学习到很多同机器学习相关的知识,同时动手实现也锻炼了编程能力,配置环境和实现过程中的问题可以很好的培养在网络上搜索和解决问题的能力。
在模型的优化时,也对oneAPI的组件有了一定的了解,使用时可以体会到oneAPI是一个强大的组件,可以在很大程度上优化训练出来的模型,使模型的F1分数提高,推理时间也能得到明显的减少,而量化也能在模型性能不受太大影响的前提下,将原本体积较大的模型,缩小许多倍,但推理时间或许有变长,可以按实际需求选择。
总的来说,此次项目的实现让人收获颇多,期待在吸收所得知识和经验后再学习路上走得更远。















 9087
9087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









