










目录
在大数据时代,“数据仓库”和“数据湖”常被同时提及,甚至被误认为是同一类技术方案。然而,二者在架构设计、数据处理方式、应用场景等方面存在显著差异。
本文将从多个维度对比数据仓库与数据湖,帮助你厘清概念,选型不再困惑。
一、概念对比:结构化 vs 全类型数据
| 维度 | 数据仓库(Data Warehouse) | 数据湖(Data Lake) |
|---|---|---|
| 数据类型 | 结构化数据为主(如关系型数据库) | 支持结构化、半结构化、非结构化数据 |
| 存储成本 | 高(通常用于高价值数据) | 低(支持原始数据大规模存储) |
| 数据处理 | ETL(Extract-Transform-Load) | ELT(Extract-Load-Transform) |
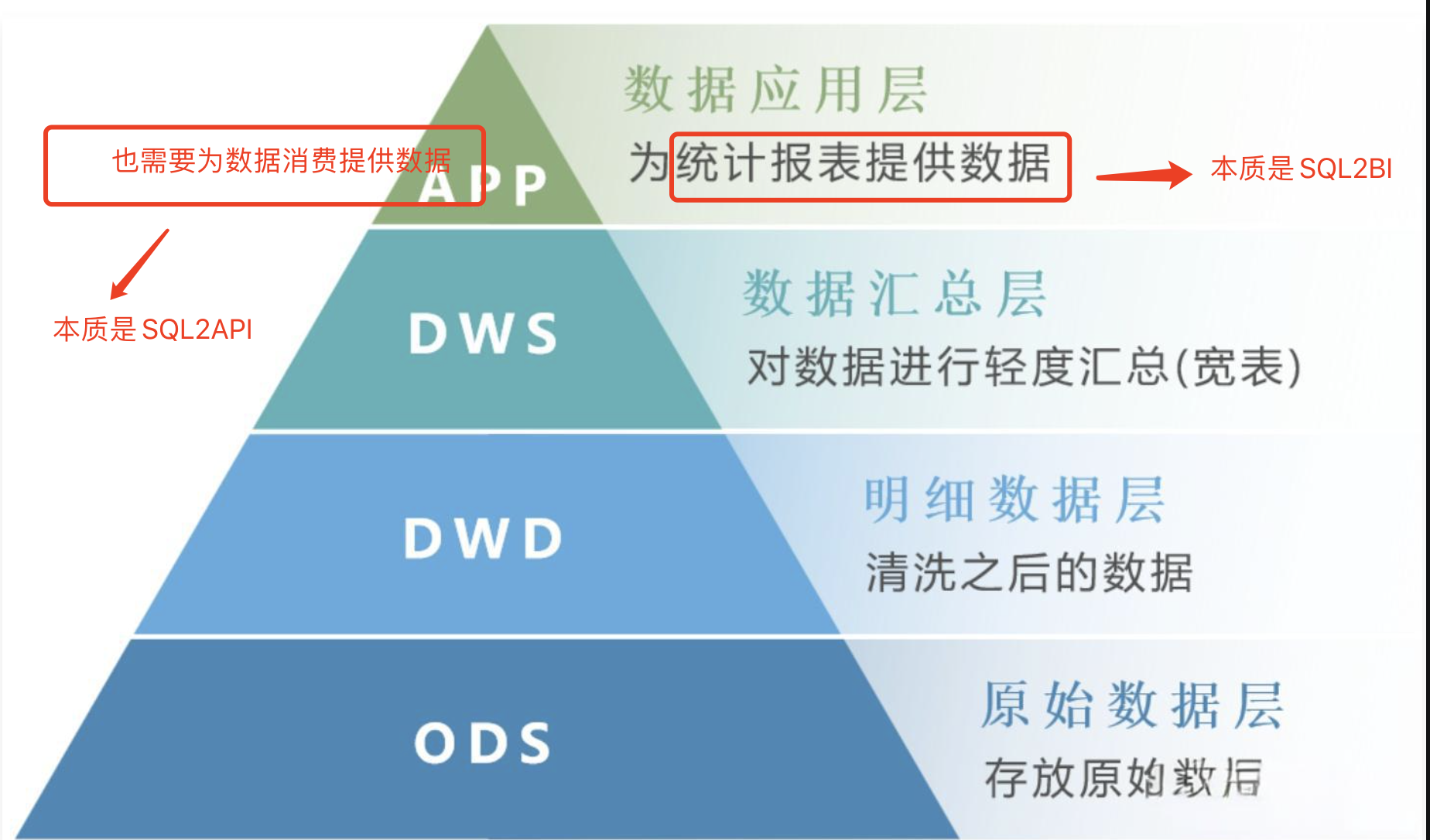
| 查询方式 | SQL、OLAP、SQL2API 等 | 多样(SQL、SQL2API、机器学习、流处理等) |
| 用户对象 | 分析师、报表用户 | 数据科学家、开发者 |
总结:数据仓库更关注数据质量、标准化与一致性,而数据湖更关注数据量、原始性与灵活性。
二、技术架构对比
1. 数据仓库架构特点
-
强模式(Schema-on-Write):数据写入前需定义清晰的数据模型。
-
高性能查询:支持多维分析与聚合计算。
-
数据生命周期受控:从接入到清洗到建模全流程精细管理。
常见实现:Oracle、Teradata、Amazon Redshift、Google BigQuery、Snowflake 等。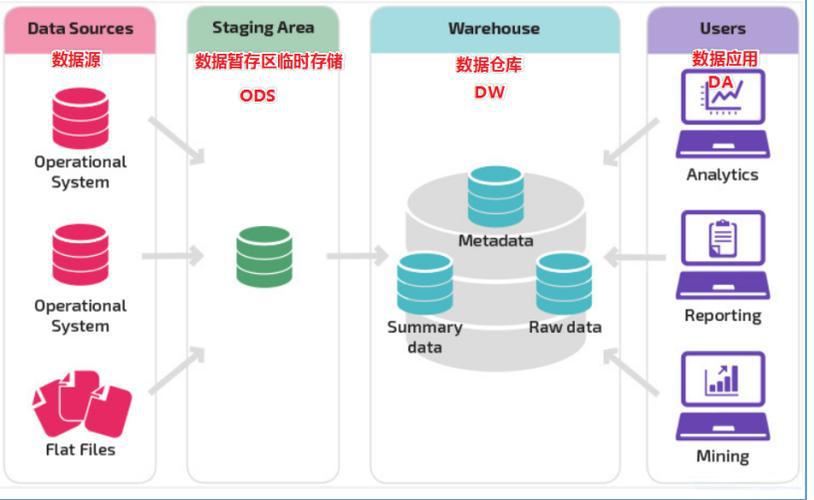
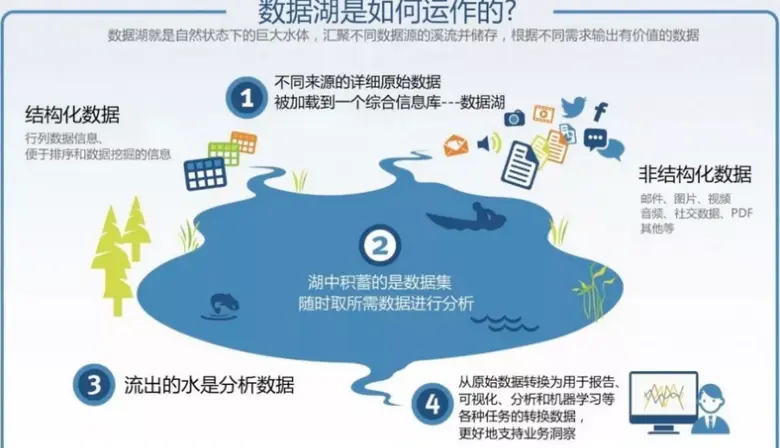
2. 数据湖架构特点
-
弱模式(Schema-on-Read):数据存储前不强制清洗,查询时再解析。
-
支持大规模数据并发处理:适合处理日志、传感器数据、多媒体等。
-
与大数据生态兼容良好:Hadoop、Spark、Presto、Hive、Iceberg 等工具均可构建数据湖。
三、典型应用场景
数据仓库适合:
-
企业 BI 报表分析和SQL2API数据共享服务
-
财务/销售等结构化数据的多维分析
-
高一致性需求的审计系统
数据湖适合:
-
数据科学与机器学习建模
-
IoT、日志、视频等海量原始数据存储
-
企业数据中台构建的数据集市、标签库
四、数据湖仓一体:趋势还是折中?
随着企业数据需求的不断扩展,数据湖与数据仓库的边界正在变得模糊。越来越多的厂商提出“Lakehouse(湖仓一体)”的概念,希望将两者的优势结合在一起:既保留数据湖的灵活性与扩展性,又具备数据仓库的高性能与治理能力。
例如:
-
Databricks Lakehouse:在数据湖之上构建类仓库的功能
-
Apache Iceberg / Delta Lake / Hudi:让数据湖具备事务、版本控制、元数据管理等能力
五、总结:如何选型?
| 目标 | 建议方案 |
|---|---|
| 快速上线 BI 报表系统和SQL2API数据共享 | 数据仓库 |
| 构建数据中台,沉淀原始数据资产 | 数据湖 |
| 同时支持分析、挖掘、建模和数据共享SQL2API | 数据湖仓一体架构(Lakehouse) |
技术选型没有银弹。理解业务场景、数据特点与团队能力,是决定采用数据仓库、数据湖还是湖仓一体的关键。
结语
数据仓库和数据湖并非对立关系,而是应对不同数据需求的工具。从“数据即资产”的角度出发,如何在治理和灵活性之间找到平衡,才是企业数字化转型成功的关键。
如果你在搭建企业数据架构的过程中有相关经验或困惑,欢迎留言交流,一起探讨大数据时代的数据管理之道!


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











