






点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
新智元报道
来源:arXiv 编辑:LRS
【新智元导读】有了AI技术的加持以后,普通人借助各种辅助工具可以很容易地进行艺术创作!这次有一个AI公司带来了一个让手绘图动起来的app,现在已经开放测试体验,还发表了一篇论文来介绍具体使用的技术,相比以往的研究,准确率提升超10个点!
手绘动画已经存在了超过100多年,即使在电子产品时代也是十分流行,可以使用绘图平板电脑或者数字软件进行手绘。
电子产品将手绘动画的制作过程也大大简化了,但仍然需要大量的手工操作,需要对每一帧进行绘制和编辑。
这些任务处于重复劳动和完全艺术创作的中间地带,也是AI辅助工具最擅长的领域:缓解重复劳动,辅助人类进行艺术创作。
目前商业的手绘辅助工具大多使用启发式算法,但效果十分有限,而且这些工具通常要求创作者以矢量格式进行绘制或使用复杂、特定的流程工作,这些限制可能会对最终生成作品的手绘感有所影响。

而深度学习方法比较适用于这种场景,神经网络模型可以很自然地把原始像素作为模型输入,但它的泛化性要弱一些,例如训练好的模型对于输入图像的size有要求,无法直接扩展到更高分辨率的情况,也无法利用到手绘图像的结构信息,特别是那些矢量信息。
针对这个问题,Cadmium公司最近在arxiv上传了一篇论文,介绍了一下他们的解决方法。研究人员主要关注学习光栅动画线条图(raster animation line drawings)序列之间的视觉对应(visual corresponding)关系。

论文地址:https://arxiv.org/abs/2109.0261
视觉对应是构建手绘动画辅助工具的基本模块,主要用于着色、中间处理和纹理等任务,这些任务也是创作动画流程中的主要非创造性工作。目前大量工作都在关注如何在像素层次上学习视觉对应,而很少去考虑线条层次的是视觉对应学习。
通过视觉对应信息,动画师可以对序列中的几帧进行着色或处理纹理,并在其余图像中复制相同的颜色,而无需重复上色。并且使用对应信息的相邻帧,可以自动生成新的中间帧,能够减少生成平滑运动所需的线条数量。
深度学习模型是一个数据驱动的问题解决方案,但由于模型设计上比较有难度,并且缺乏可用的带标签数据集,所以目前这方面还没有吸引太多人研究。
这个预期的模型应当具备5个能力:
1)能够在光栅(raster)输入上操作,并缩放至1920×1080及以上分辨率
2)在segment层面上产生视觉对应关系;
3)能够处理复杂的真实世界动画;
4)能够使用彩色图像作为数据进行有监督训练;
5)要做成交互式应用程序,速度要足够快。
这篇文章就提出了一个模型Animation Transformer (AnT)来解决这些问题。
与基于像素的视频跟踪方法需要大量注意力计算不同,AnT在线条图像中的线条封闭段上进行操作,并使用基于Transformer的架构来学习线条之间的空间和视觉关系。
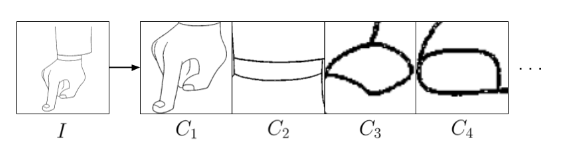
通过对这种表示进行操作,AnT不需要直接处理整张图片,也就很容易提高计算效率和内存利用率。并且这种方法可以扩展到4K图像甚至更高,使用前向匹配损失和循环一致性损失对AnT进行优化,使其能够在真实世界的动画数据集上进行训练,而无需完整的真实标签。
AnT模型的主要架构由三个模块组成:
1、CNN主干网络用于提取每个segment的视觉特征
2、边界框编码器(bounding box encoder)用于提取每个segment的位置embedding
3、一个多路复用转换器(multiplex transformer)用于学习segment和帧的全局结构并预测最终匹配矩阵
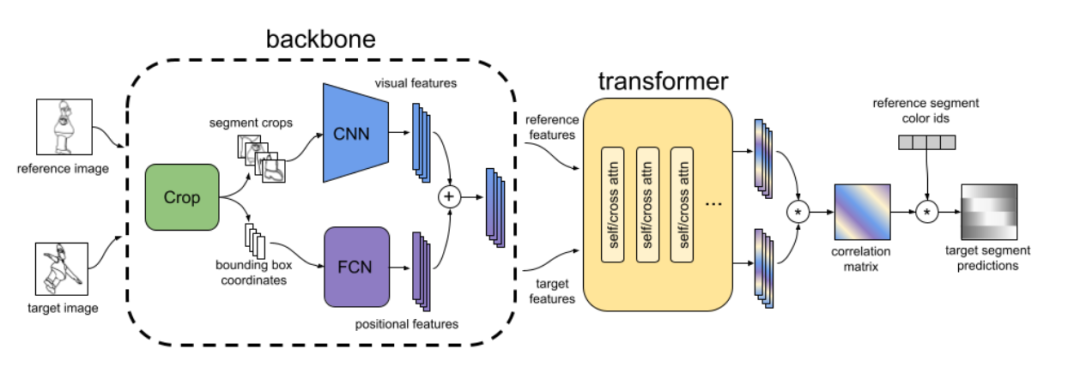
虽然位置和视觉特征是估计线段对应关系的基础,但经常出现的视觉特性不能仅通过局部特征来解决。
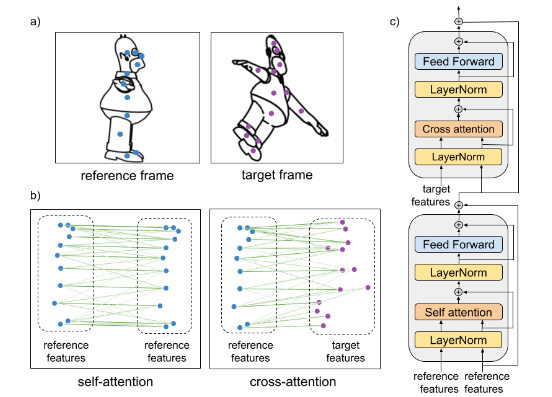
例如遮挡或变形会破坏单个片段的形状,或者可能存在多个片段相同的片段,例如眼睛,如果单独查看每个部分则无法区分。
并且一组动画线条通常包含属于同一语义部分的相邻线段组,但需要被分割为多个线段,因为前景中包含一个对象,但这些线段的轮廓线有可能和后面的对象相交(例如两个打架的小人)。

为了能够从对应标签和颜色标签中学习,AnT使用了两个损失函数,既可以单独使用,也可以根据标签来源取平均。
1、前向匹配损失(Forward match loss):为了促进模型直接使用视觉对应或颜色标签信息,研究人员使用数据集中预测的目标标签和真实目标标签之间的分类交叉熵损失。
在存在视觉对应标签的情况下,作为加权平均计算输入的目标标签和参考标签都是唯一的,所以模型可以直接将不正确的视觉对应最小化。
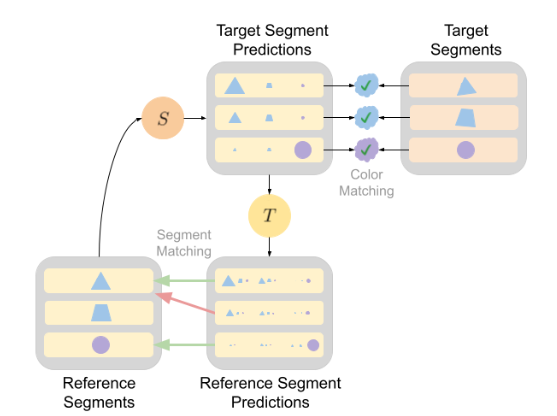
但是,在有颜色标签的情况下,目标标签和参考标签可能是不唯一的,并且该模型仅最小化错误的颜色指定。这将导致模型学习到捷径并找到匹配项,这些匹配项将产生正确的颜色分配,但可能导致不正确的视觉对应。
2、周期一致损失(cycle consistency loss):为了解决前向损失产生不正确视觉对应的问题,当存在有不唯一颜色标签的情况下,周期一致损失将阻止模型学习捷径匹配。并且不使用数据集中的参考标签,而是给唯一片段ID初始化一个随机向量,使用它们代替目标标签进行加权标签聚合。
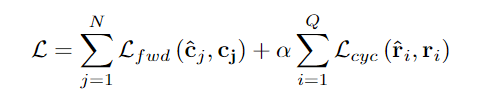
由于缺少公开可用的数据集,论文中使用了两个自用数据:
1、合成数据集(Synthetic Dataset):为了训练AmT的分段对应标签,研究人员使用免费的3D模型在Cinema4D数据集中生成一个合成数据集。使用卡通着色器渲染线条图像,并通过为单个网格指定唯一ID来生成线段对应标签。角色通过不同的运动、变形和旋转来模拟实际动画。使用TurboSquid的11个3D角色模型,以1500x1500像素的分辨率为每个角色生成1000帧,总共生成11000帧。
2、真实数据集(Real Dataset):由于动画师不局限于3D程序的限制,所以手绘动画比3D动画更具多样性和表现力,并且手绘动画包含更广泛的动画样式和角色设计。但对于视觉对应模型来说,它们并不能从3D程序的合成数据中训练。
为了解决这个问题,研究人员从17个不同的真实动画作品中收集了一个高分辨率手绘动画数据集,总共3578帧。每部作品的动画风格差异很大,但风格更接近美国和欧洲动画,数据集极其多样化,有数百个不同的人物。真实数据集没有唯一的对应标签,所以使用彩色图像中的段颜色来提取标签。与合成数据集相比,这个操作会产生非唯一的数字分段标签。
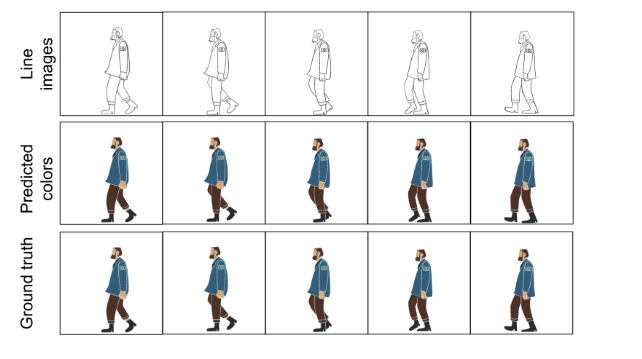
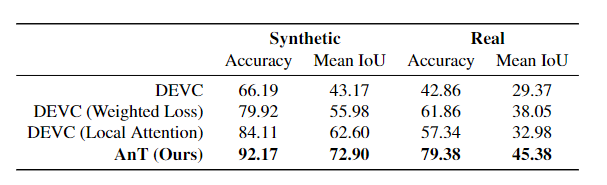
通过量化结果可以看出AnT的准确率提升了近10个点,比以往的模型都有较大提升。
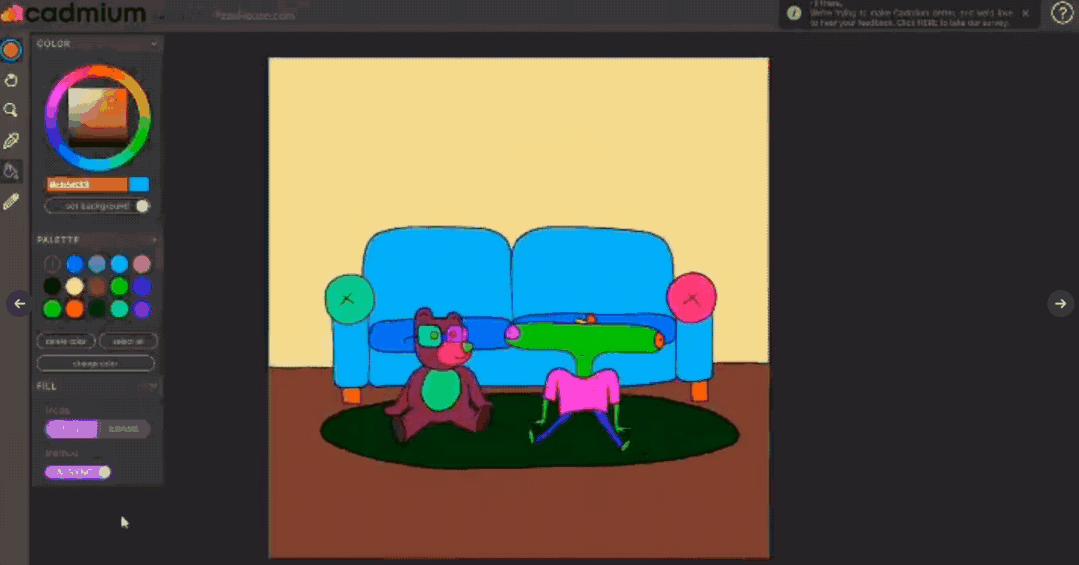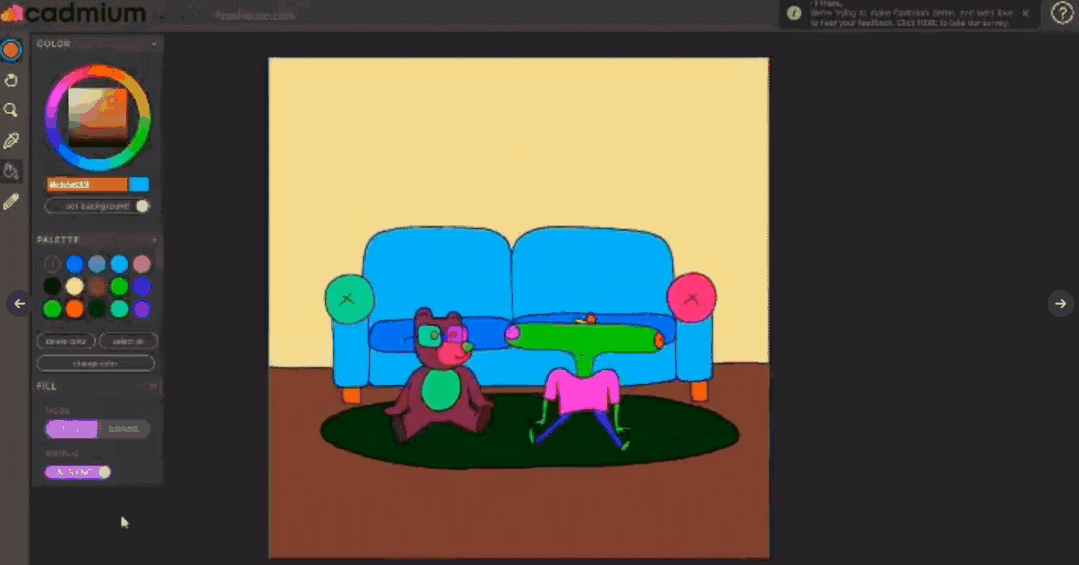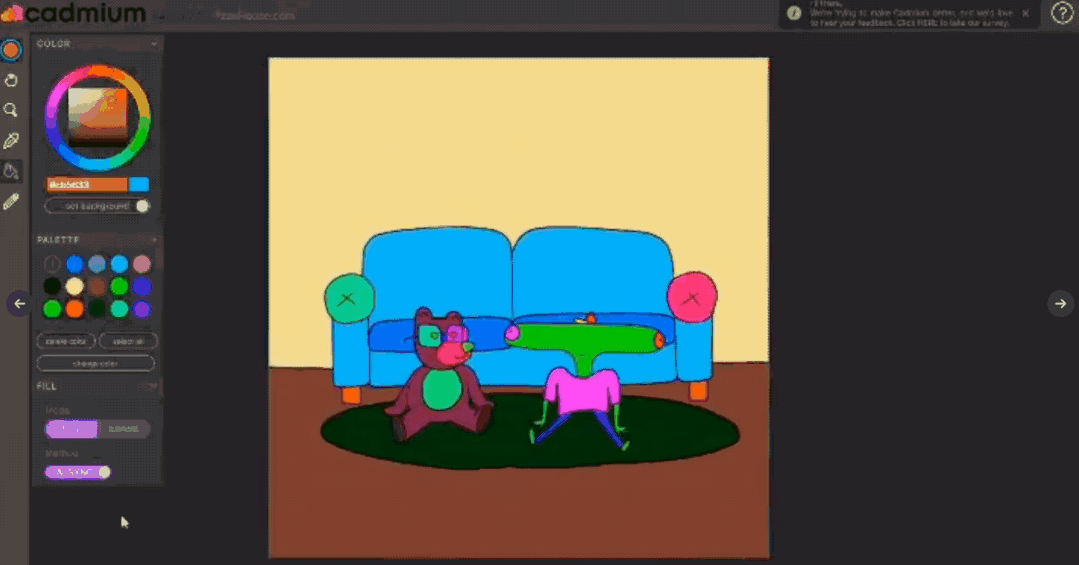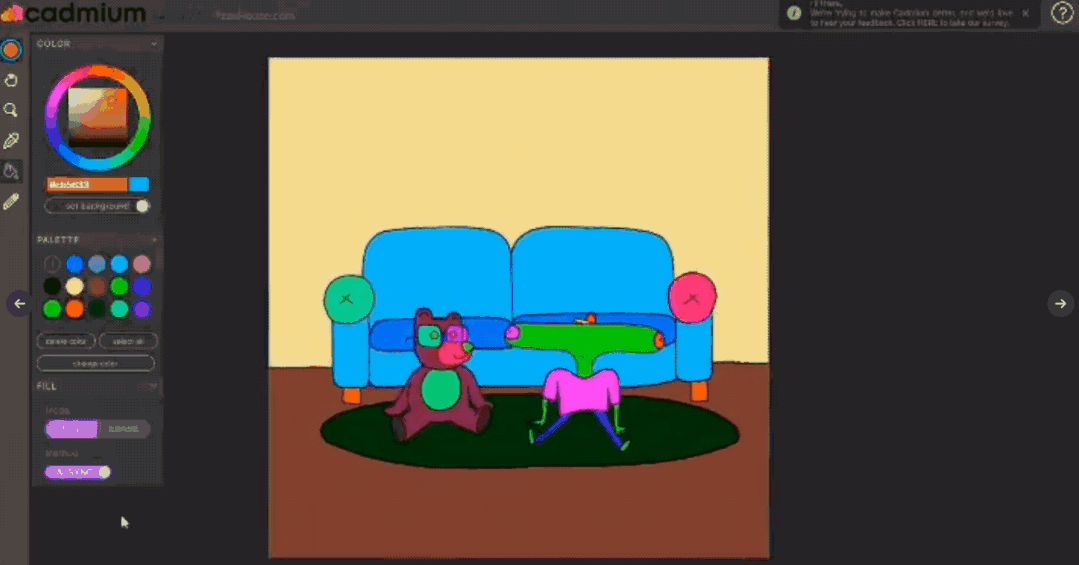
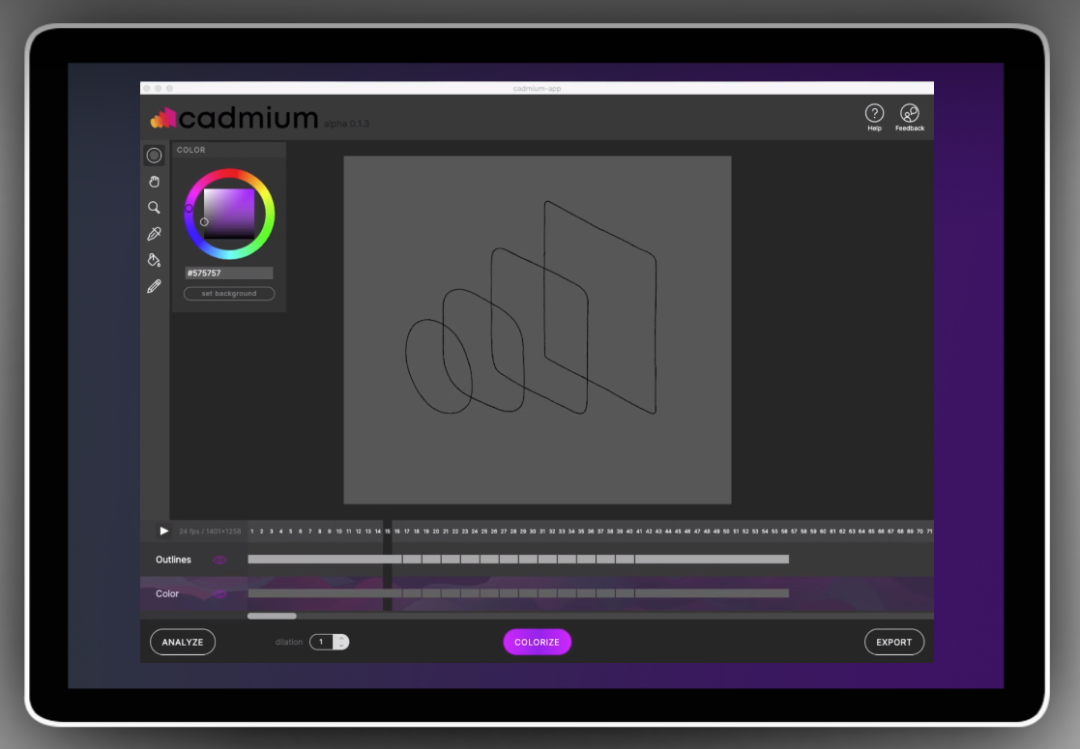
目前这项技术已经落地成产品,目前处于beta测试版,可以访问Cadmium的官网https://cadmium.app/申请体验。
参考资料:
https://arxiv.org/abs/2109.0261
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
















 6620
6620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









