







图像编辑系列之(2)基于StyleGAN(3)GAN逆映射(4)人脸 (5)语义生成 | ICCV2021生成对抗GAN梳理汇总
图像恢复系列之(6)超分(7)反光去除(8)光斑去除 (9)阴影去除(10)水下图像失真去除 | ICCV2021生成对抗GAN
十八、文字生成图像
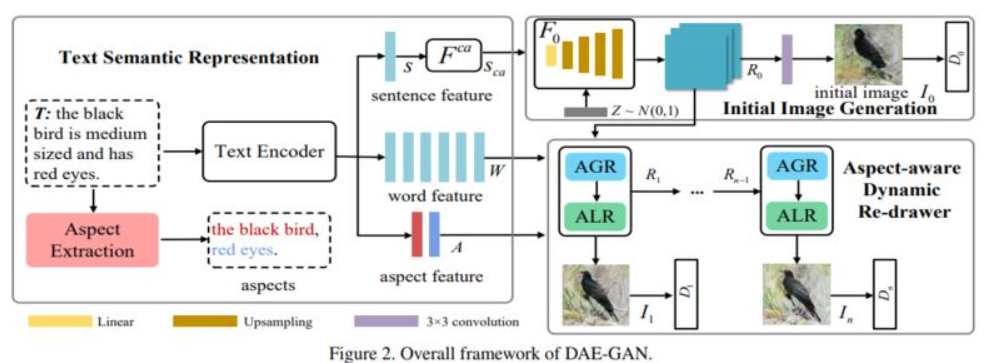
55、 DAE-GAN: Dynamic Aspect-aware GAN for Text-to-Image Synthesis
文本转换生成图像是指,从给定的文本描述中生成图像,保持照片真实性和语义一致性。此前方法通常使用句子特征嵌入去生成初始图像,然后用细粒度的词特征嵌入对初始效果进行细化。
文本中包含的“aspect”信息(例如,红色的眼)往往连带几个词,这对合成图像细节信息至关重要。如何更好地利用文本到图像合成中的aspect信息仍是一个未解决的挑战。本文提出一种动态 Aspect-awarE GAN (DAE-GAN),从多个粒度(包括句子级、词级和aspect级)全面地表示文本信息。
此外,受人类学习行为的启发,开发一种用于图像细化的新型 Aspectaware Dynamic Re-drawer (ADR)。最后设计相应的匹配损失函数来保证不同层次的文本图像语义一致性。在CUB-200 和 COCO上的实验证明了方法的优越性和合理性。
十九、说话人生成
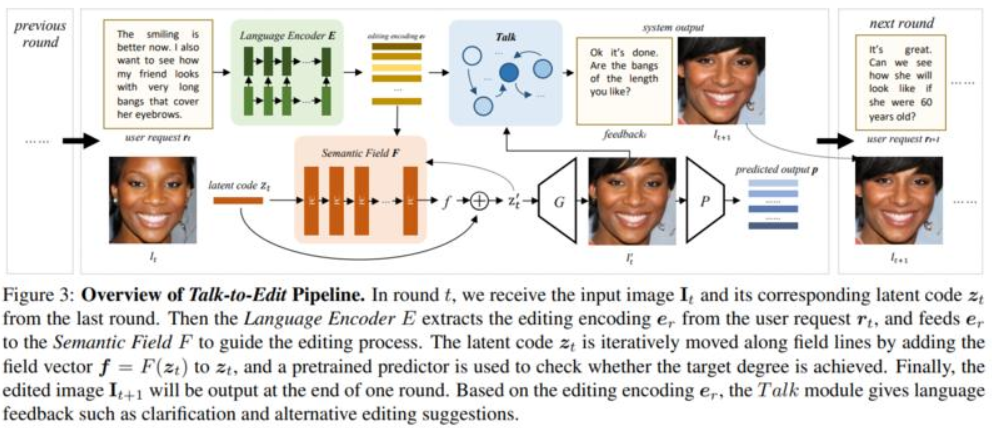
56、 Talk-to-Edit: Fine-Grained Facial Editing via Dialog
人脸编辑是视觉和图形中的重要任务。现有方法无法提供与用户自然交互的连续且细粒度的编辑模式(例如,将微微笑脸编辑为大笑脸)。
这项工作提出Talk-to-Edit,一个交互式编辑框架,通过用户和系统之间的对话执行细粒度的属性操作。主要想法是在 GAN 潜在空间中模拟一个连续的“语义场”。1)与以往的作品将编辑视为在潜在空间中遍历直线不同,这里的细粒度编辑被表述为在语义场上找到尊重细粒度属性景观的弯曲轨迹。2)每一步的“曲率”是位置特定的,由输入图像以及用户的语言请求决定。3)为了让用户参与有意义的对话,系统通过考虑用户请求和语义场的当前状态来生成语言反馈。还贡献了 CelebA-Dialog,一个视觉语言人脸编辑数据集,以促进大规模研究。具体来说,每张图像都有手动注释的细粒度属性注释以及自然语言中基于模板的文本描述。广泛的定量和定性实验证明了框架在以下方面的优越性:1)细粒度编辑的平滑度,2)身份/属性保存,3)视觉真实感和对话流畅度。
https://www.mmlab-ntu.com/project/talkit/
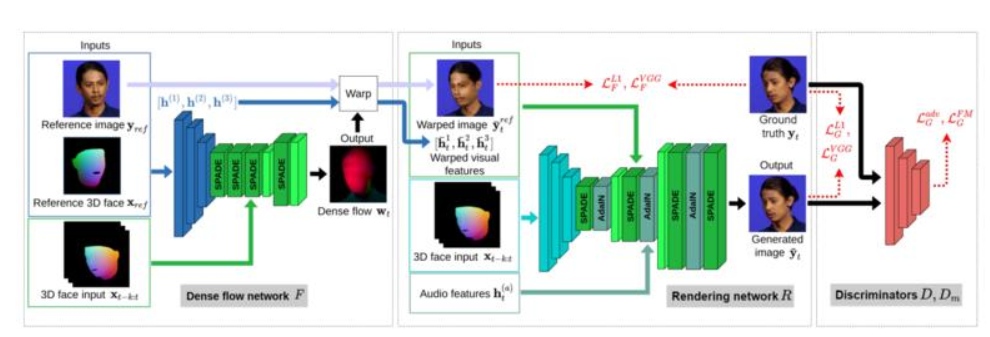
57、 HeadGAN: One-shot Neural Head Synthesis and Editing
近来,基于单张参考图像来完成人脸重现任务的研究已有一定进展。但在照片逼真度方面仍表现不佳,或者无法较好保留身份ID信息,或者没有完全迁移驱动的姿势和表情。
本文提出HeadGAN,根据 3D 人脸表征进行合成,可以从任何驱动视频中提取并适应参考图像的脸部几何形状,将身份与表情分离。通过利用音频特征作为补充输入来进一步改进嘴部动作。
https://michaildoukas.github.io/HeadGAN/
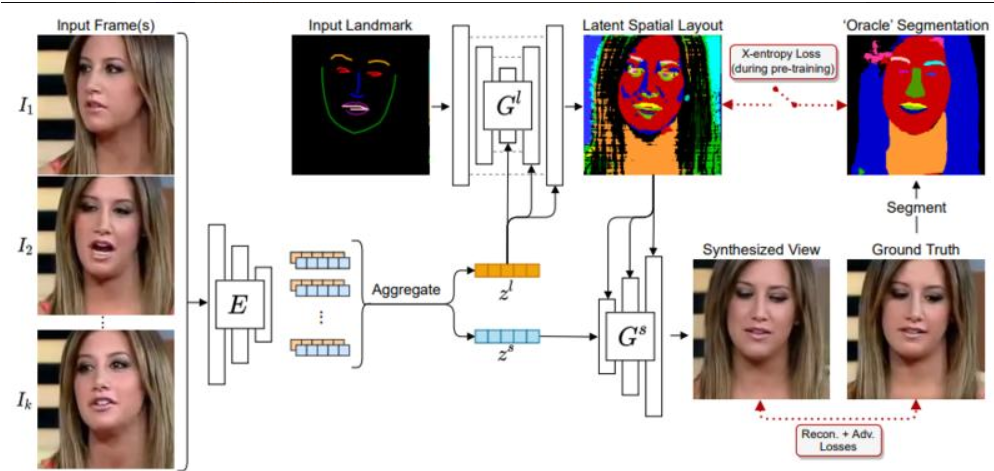
58、Learned Spatial Representations for Few-shot Talking-Head Synthesis
提出了一种新的方法来进行少样本说话人生成。虽然最近相关工作已有一定进展,但产生的效果里无法保留源图像中主体身份ID信息。
本文假设这是每个个体人在单潜码中的纠缠表示所导致,提出将其分别解耦为其空间和风格细节方面。
59、 MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement
本文提出一种从语音生成3D全脸驱动的方法。现有音频驱动的人脸驱动方法无法产生准确和合理的协同发音,或者有依赖于特定于人的局限。
为此提出一种通用音频驱动的人脸驱动方法,可以为整个人脸实现高度逼真的运动合成结果。方法核心是解耦潜在空间,它基于一种新颖的跨模态损失来解开音频相关和音频不相关的信息,确保了高度准确的嘴唇运动,同时还合成了与音频信号无关的面部部分的合理动画,例如眨眼和眉毛运动。
https://github.com/facebookresearch/meshtalk
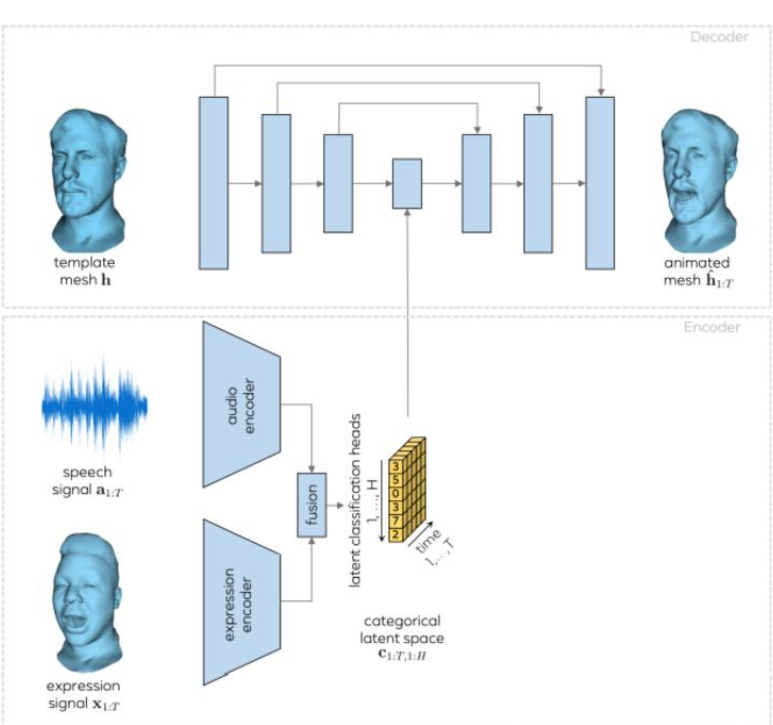
60、 FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning
本文提出一种说话人生成方法,以音频信号为输入,以目标短视频剪辑为参考,合成具有自然嘴形运动、头部姿势和眨眼与目标人脸般的视频。
注意到,生成人脸属性不仅包括与语音高度相关的显式属性,例如唇部动作,还包括与输入音频相关性较弱的隐式属性,例如头部姿势和眨眼。为了对不同人脸属性与输入音频之间的这种复杂关系进行建模,提出了一种人脸隐式属性学习生成对抗网络(FACIAL-GAN),它集成了语音感知、上下文感知和身份感知信息来合成 3D 面部动画和嘴唇、头部姿势和眨眼的逼真动作。然后, Rendering-toVideo 网络将渲染的人脸图像和眨眼的注意力图作为输入,以生成逼真的输出视频帧。

猜您喜欢:

附下载 |《TensorFlow 2.0 深度学习算法实战》
















 2583
2583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









