







论文随记|Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis学习动态面部辐射场实现few-shot说话人头合成
任务类型:音频、图像驱动图像
本文发表在ECCV2022
目录
引文
提出了一个基于面部辐射场的模型DFRF,通过对少量的训练数据进行训练迭代,可以取得较好的视觉效果。
贡献
- 提出了一个以 3D 感知参考图像特征为条件的动态面部辐射场。面部领域可以快速泛化到新的身份,只需 15 秒的剪辑进行微调;
- 为了更好地建模说话头部的面部动态,我们学习以每个参考图像的音频信号为条件 的3D逐点面部变形模块,以将其变形到查询空间;
- 所提出的 DFRF 可以仅使用少量训练数据和有限的迭代来生成生动自然的头部说话视频,这远远超过了相同设置下其他基于 NeRF 的方法。
相关工作
Neural Radiance Fields
神经辐射场 (NeRF)使用全连接网络以体素网格的形式存储 3D 几何和外观信息。NeRF的核心思想是使用神经网络来表示场景中每个点的辐射亮度(radiance)。与传统的图像生成模型不同,NeRF 不仅仅生成颜色值,还生成了与场景中每个点的方向相关的辐射亮度。这允许生成高质量、高分辨率的三维重建,尤其在虚拟现实(VR)和计算机图形学领域具有潜在应用。
关于其详细的介绍和应用,可以参考博客:https://blog.csdn.net/minstyrain/article/details/123858806
方法
问题描述
针对talking-head生成任务,本文专注于一个更具挑战性的设置。对于一个任意的人,只有一个短的训练视频剪辑可用,一个个性化音频驱动的人像动画模型与高质量的合成结果应该只需要几次迭代的微调。这种设置的三个核心特点可以概括为:有限的训练数据,快速收敛和出色的生成效果。
本文提出了一个动态面部辐射场(DFRF)的fewshot说话头合成。图像特征被引入作为一个条件,以建立从参考图像到相应的面部辐射场的快速映射。为了快速收敛,首先在不同身份之间训练基础模型,以捕获头部的结构信息并建立从音频到嘴唇运动的通用映射。执行有效的微调以快速泛化到新的目标身份。
动态面部辐射场
新提出的NeRFs为 3D 场景表示提供了一个强大而优雅的框架。它使用 MLP Fθ 将场景编码到 3D 体积空间中。然后通过沿着相机光线整合颜色和密度来将 3D 体积渲染成图像 。具体来说,使用 P 作为体素空间中所有 3D 点的集合,以 3D 查询点 p = ( x , y , z ) ∈ P p = (x, y, z) ∈ P p=(x,y,z)∈P 和 2D 视图方向 d = ( θ , ϕ ) d = (θ, \phi) d=(θ,ϕ)作为输入,该 MLP 推断对应的RGB颜色c和密度σ,可以表示为 ( c , σ ) = F θ ( p , d ) (c, σ) = Fθ (p, d) (c,σ)=Fθ(p,d)。
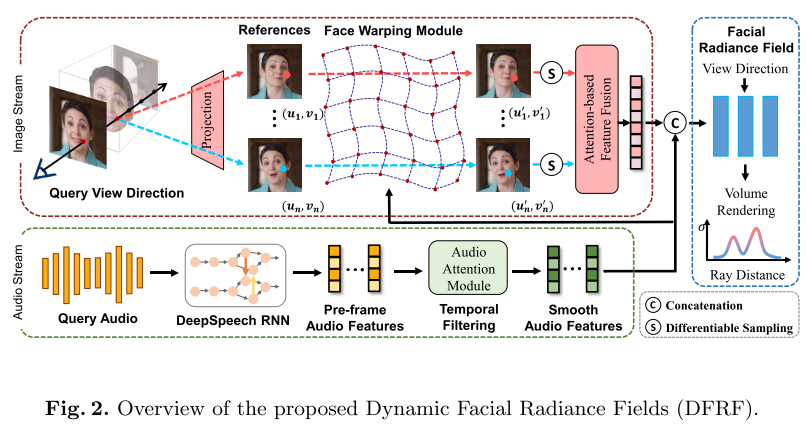
这项工作采用 NeRF 作为 3D 感知talking-head建模的backbone。talking-head任务重点关注音频驱动的面部动画。然而,最初的 NeRF 只针对静态场景而设计。因此,我们通过引入音频条件来提供缺失的变形通道,如图 2 的音频流所示。我们首先使用预训练的基于 RNN 的 DeepSpeech模块来提取每帧音频特征。为了实现帧间一致性,进一步引入时间滤波模块来计算平滑音频特征A,其可以表示为其相邻音频特征的基于自注意力的融合。以这些音频特征序列A为条件,我们可以学习音频-唇形映射。该音频驱动的面部辐射场可表示为 ( c , σ ) = F θ ( p , d , A ) (c, σ) = Fθ (p, d,A) (c,σ)=Fθ(p,d,A)。
原有模型的问题: 身份信息被隐式编码到面部辐射场中,并且在渲染时没有提供显式的身份特征,因此该面部辐射场是特定于个人的。对于每个新身份,都需要在大型数据集上从头开始优化。这导致昂贵的计算成本并且需要很长的训练视频。
引入参考机制: 本文设计了一种参考机制,使预训练的基础模型能够快速泛化到新的人物。基于参考的架构的概述如图 2 所示。具体来说,采用 N 个参考图像 M = { M n ∈ R H × W ∣ 1 ≤ n ≤ N } M = \{Mn ∈ R^{H×W}|1 ≤ n ≤ N \} M={Mn∈RH×W∣1≤n≤N}及其相应的相机位置 { T n } \{Tn\} {Tn} 作为输入,一个两层卷积网络用于计算它们的像素对齐图像特征 F = { F n ∈ R H × W × D ∣ 1 ≤ n ≤ N } F = \{Fn ∈ R^{H×W×D}|1 ≤ n ≤ N\} F={Fn∈RH×W×D∣1≤n≤N} 而不进行下采样。本文中特征维度D设置为128,H、W分别表示图像的高度和宽度。对于 3D 查询点 p = ( x , y , z ) ∈ P p = (x, y, z) ∈ P p=(x,y,z)∈P,我们使用内在函数 { K n } \{Kn\} {Kn} 和相机位姿 { R n , T n } \{Rn, Tn\} {Rn,Tn} 将其投影回基于参考的 2D 图像空间,并获得相应的 2D 坐标。使用 p n r e f = ( u n , v n ) p^{ref}_{n} = (un, vn) pnref=(un,vn) 表示第 n 个参考图像中的 2D 坐标,该投影可以表示为:

其中M是world to image的映射。然后对来自N个参考的像素级特征 { F n ( u n , v n ) } ∈ R N × D \{Fn(un, vn)\} ∈ R^{N×D} {Fn(un,vn)}∈RN×D在舍入操作后采样,与基于注意力的模块融合。最终得到 F ~ = A g g r e g a t i o n ( { F n ( u n , v n ) } ) ∈ R D \widetilde{F}=Aggregation(\{ Fn(un, vn)\}) ∈ R^{D} F =Aggregation({Fn(un,vn)})∈RD。这些特征网格包含有关身份和外观的丰富信息。使用其作为面部辐射场的额外条件,可以在只有几个帧的条件下泛化到新的面部。辐射的公式如下:

- 小结:基于NeRF的基础模型,引入了一个多个参考图像的的机制,进行特征提取。获取多个图像的特征后,基于注意力模块,获取到了最终需要的特征。最后将3D点投影回2D空间。
Differentiable(可微分) Face Warping
存在问题: NeRF中基于3D到2D的投影方法,是一种较为严格的空间映射关系,适用于刚性场景。但说话的人脸合成是动态的,面部可能会变形。因此应用公式(1)直接在面部可能会导致关键点不匹配。(例如说话时嘴唇的变形,嘴角附近的3D点被映射回参考图像,可能会偏离正确的口型)。这种不正确的映射导致参考图像有误,影响对嘴部变形的预测。
引入面部变形模块Dη :提出了一个音频调节的3D逐点变形模块Dη。对变形下每个投影点 p r e f p^{ref} pref的偏移量 Δ o = ( Δ u , Δ v ) Δo = (Δu,Δv) Δo=(Δu,Δv)进行回归。Dη是一个三层的MLP变形场,η是一个可学习参数。为了回归偏移 Δo,需要利用查询图像和参考图像之间的动态差异。将反映了面部动态变化的音频特征A,和包含参考图像的变形特征的 F n {Fn} Fn,以及被查询的坐标点p,一起输入变形模块Dη,预测偏移量:

随后将预测的偏移量和原预测点相加,得到变形后的预测点:

其中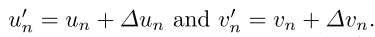
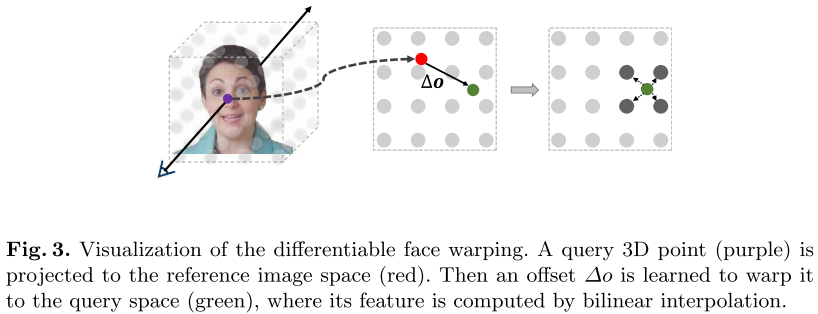
由于硬索引运算 F n ( u n ′ , v n ′ ) F_{n}(u_{n} ', v_{n} ') Fn(un′,vn′) 不可微分,因此梯度无法反向传播到该扭曲模块。因此,我们引入了软索引函数来实现可微的扭曲,其中每个像素的特征是通过双线性采样对其周围点进行特征插值来获得的。这样,形变场 D η Dη Dη和面部辐射场 F θ F_{θ} Fθ就可以端到端地联合优化。这种软索引操作的可视化如图 3 所示。对于绿点,其像素特征是通过双线性插值通过其四个最近邻的特征计算的。为了更好地约束这个扭曲模块的训练过程,我们引入了正则化项Lr来将预测偏移的值限制在合理的范围内以防止扭曲:

其中 P 是空间中所有 3D 点的集合,N 是参考图像的数量。本文认为低密度点更有可能是具有低变形偏移的背景区域。在这些地区,应该施加更严格的规范化约束。为了更合理的约束,我们将上面的Lr改为:

其中 σ 表示这些点的密度。动态面部辐射场最终可以表述为:

其中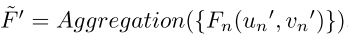
- 小结:通过引入一个变形模块 D η Dη Dη,可以估计查询图像和参考图像之间的变形偏移。再通过此模块将参考图像转换到查询空间,更好的建模变形的面部。
Volume Rendering
此模块用于积分公式(7)中的颜色和密度,转化为人脸图像。将背景、躯干和颈部一起作为渲染“背景”,并从原始视频中逐帧还原。我们将每条射线最后一个点的颜色设置为相应的背景像素,以渲染包括躯干部分的自然背景。按照原始NeRF的设置,引入音频和图像特征 F ~ ′ \widetilde{F}' F ′的情况下,相机光线r的积累颜色C为:

其中 θ 和 η 分别是面部辐射场 Fθ 和面部扭曲模块 Dη 的可学习参数。 R 是旋转矩阵,T 是平移向量。按照 NeRF 将 MSE 损失设计为 L M S E = ∥ C − I ∥ 2 L_{MSE} = ∥C − I∥^{2} LMSE=∥C−I∥2,其中 I 是groundtruth颜色。与公式(6)相加,总体损失函数可表示为:

实现细节
只训练一个从粗到细不同身份的基础辐射场。粗训练阶段,面部辐射场 F θ Fθ Fθ在LMSE监督下训练,学习头部结构并建立从音频到嘴唇运动的映射。然后将变形模块按照公式(7)加入训练,与公式(9)的损失函数联合端到端训练偏移回归网络Dη和 F θ Fθ Fθ。
对于一个任意的未见过的身份,只需要一个简短的训练片段,只需要他/她的几十秒的讲话视频,基于预训练的基础模型进行微调。经过微调,可以学习到个性化的嘴部发音模式,渲染图像质量将得到极大提高。微调后的模型可以直接用于推理。
实验
实验设置
-
数据集:从 YouTube 上收集了 11 个身份的 12 个公开视频,平均长度为 3 分钟。将所有视频重新采样为 25 FPS,并将分辨率设置为 512×512。
-
头部姿势:基于 Face2Face 估计头部姿势。为进一步平滑姿势,使用bundle adjustment作为过滤器。相机姿态 { R n , T n } \{Rn,Tn\} {Rn,Tn}是头部姿态的逆,其中R是旋转矩阵,T是平移向量。
-
评价指标:学习感知图像块相似性(LPIPS↓)、SyncNet(偏移量↓/置信度↑)
消融实验
参考图像的数量: 通过实验定量分析,统一使用了4个。

训练数据长度的影响: 用10秒、15秒和20秒的训练视频对所提出的DFRF进行微调,以进行50 k次迭代。
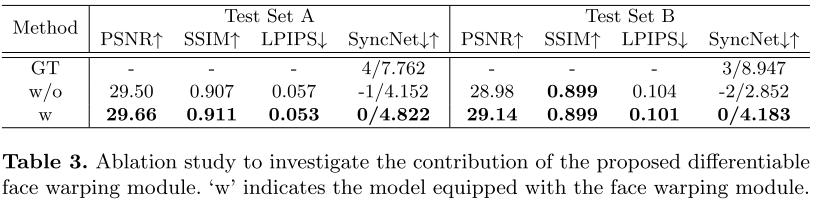
Differentiable(可微分) Face Warping的效果:
所有模型都在15秒的视频上进行了微调,以进行50k次迭代。如果没有这个模块,查询3D点不能精确映射到参考图像中的对应点,特别是在一些动态丰富的区域。因此,说话的嘴的动态在一定程度上受到影响,这反映在视听同步(SyncNet得分)上。相比之下,配备变形场的模型可以显著提高SyncNet置信度,视觉质量也略有改善。

方法对比
与Few-shot方法对比: 表4中的定量结果表明,本文提出的方法在感知图像质量度量LPIPS上远远超过NERF和AD-NERF。
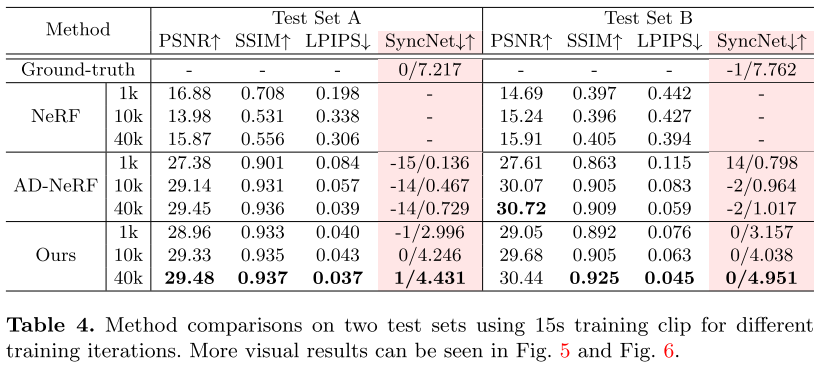
图5可视化了三种方法的生成帧。在相同的1k训练迭代次数下,我们的方法的视觉质量远远优于其他方法。

图6中经过40k次迭代的15s训练片段的AD-Nerf。与真实情况相比,我们的方法显示出比AD-Nerf更准确的音唇同步。
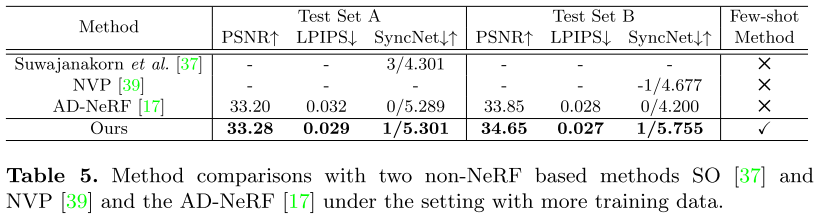
与更多训练数据的方法比较: 在few-shot条件下,本文发方法表现更优。因为所提出的面部扭曲模块更好地模拟说话的面部动态。
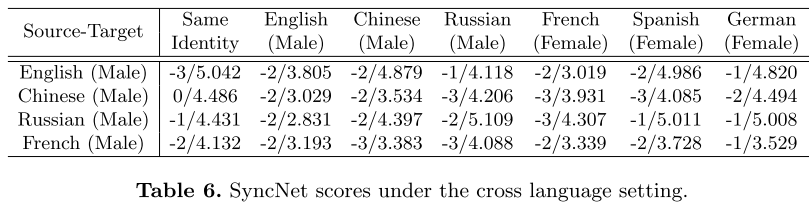
跨语言的结果: 进一步验证了我们的方法的性能由不同语言和性别的音频驱动。选择四个模型,使用来自不同语言的15秒训练片段(源)进行训练,然后使用跨六种语言和不同性别的驱动音频。分数表明,我们的方法在这种跨语言设置中产生了合理的唇音频同步
结论
本文提出了一个动态的面部辐射场的few-shot说话头部合成。采用音频信号与3D感知图像特征相结合,作为快速推广到新身份的条件。为了更好地模拟说话头部的嘴部运动,进一步学习了音频调节的面部变形模块,以将所有参考图像变形到查询空间。大量的实验表明,本文方法在有限的训练数据和迭代下,生成的自然说话视频具有优越性。


















 2157
2157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









