







本文作者 牛超超
根据文本生成高质量的复杂图像是一项具有挑战性的任务。基于大规模预训练,自回归和扩散模型可以合成逼真的图像。尽管这些大型模型取得了显著进步,但仍存在三个不足:
1)这些模型需要大量的训练数据和参数才能获得良好的效果。
2) 需要通过多步生成,严重降低了图像生成速度。
3)生成的视觉特征难以控制,需要精心设计提示。
为了同时实现生成质量高、训练高效、生成速度快,以及内容更可控的文本到图像生成模型,作者提出了 Generative Adversarial CLIPs,即 GALIP。如图1所示,GALIP 在判别器和生成器中都利用了强大的预训练 CLIP 模型。
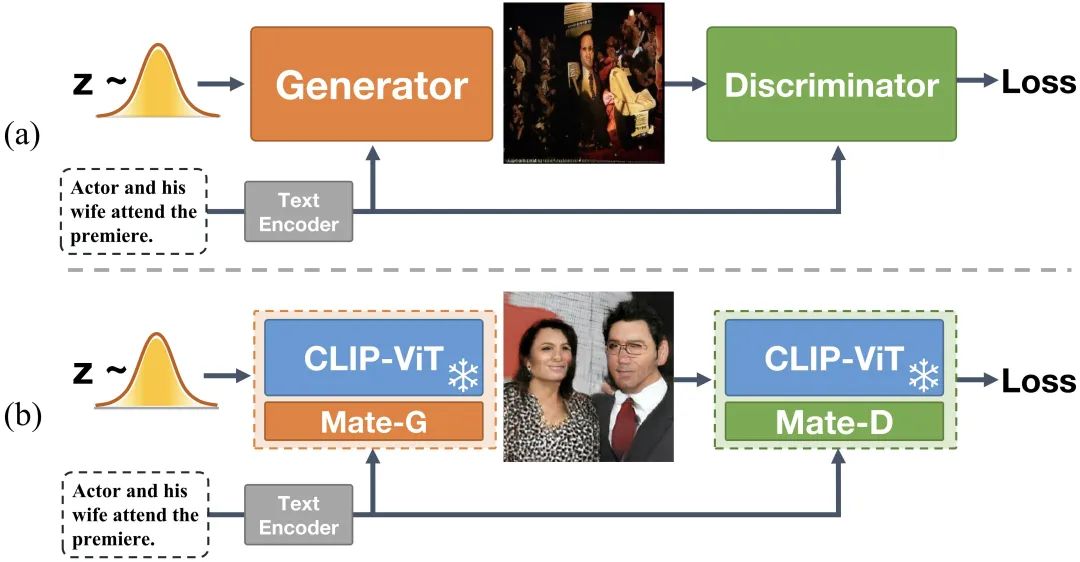
图 1.(a)以前的文本到图像生成对抗网络。(b).基于预训练CLIP的生成对抗网络。
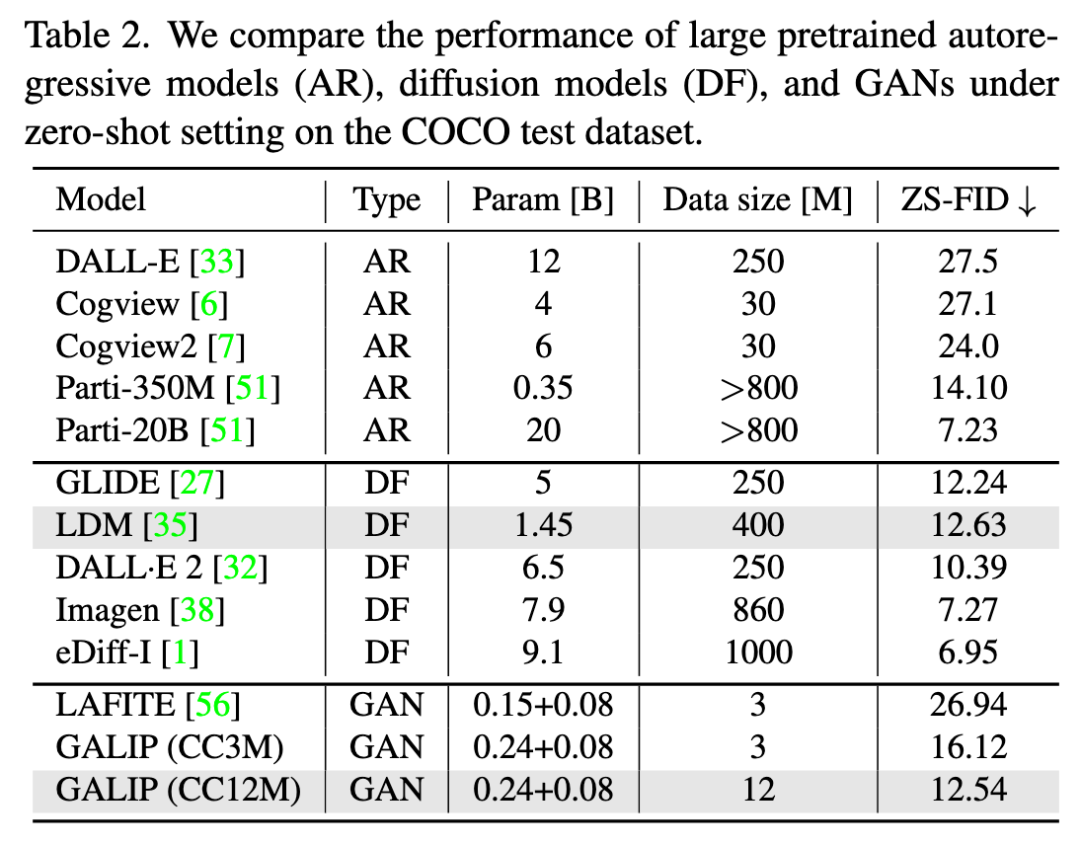
具体来说,GALIP首先提出了一个基于 CLIP 的判别器。CLIP 的复杂场景理解能力使判别器能够更加准确地评估复杂图像的质量。此外,还提出了一个 CLIP 增强的生成器,它通过Bridge Feature和Prompts从 CLIP 中抽取有用的视觉概念。集成 CLIP 的生成器和判别器提高了对抗学习效率,使得GALIP只需要大约 3% 的训练数据和 6% 的可学习参数(如图2所示),仅用8张3090显卡训练3天时间,取得了与大规模预训练的自回归和扩散模型相当的结果。同时,GALIP的生成速度也快了120倍,且继承了 GAN 更加可控的平滑隐空间。广泛的实验结果证明了 GALIP 的卓越性能。目前代码已开源到GitHub上 (https://github.com/tobran/GALIP)。

图 2 相比于Latent Diffusion Model (LDM),GALIP在取得相当的性能的同时,只需要极少的训练数据,并且生成图片的速度快近120倍
模型框架:

图 3. GALIP的具体结构。
GALIP的框架如图3所示,GALIP在判别器和生成器中都集成了CLIP模型。包括基于CLIP的判别器和CLIP增强的生成器。基于CLIP的判别器继承了CLIP的复杂场景理解能力。它由一个冻结的基于ViT的CLIP图像编码器 (CLIP-ViT) 和一个可学习的协同判别器 (Mate-D) 组成。Mate-D与CLIP-ViT一起配合进行对抗训练。为了在CLIP-ViT中保留复杂场景理解的知识,冻结 CLIP-ViT 的权重并从不同层收集预测的CLIP图像特征。然后,Mate-D 从收集的CLIP特征中进一步提取有效的视觉特征,以区分合成图像和真实图像。
此外,GALIP还提出了CLIP增强的生成器,它发挥了CLIP的泛化能力。普通的生成器很难直接合成复杂的图像。一些工作使用草图和布局作为中间域来减轻难度。然而,这样的设计需要额外的标记数据。与这些工作不同的是,CLIP出色的泛化能力促使我们认为CLIP-ViT可能存在一个隐含的中间域,相比复杂图片,它更容易合成,且能够将中间域的特征转换为有用的视觉概念。因此,作者设计了CLIP增强的生成器。它由一个冻结的CLIP-ViT和一个可学习的协同生成器 (Mate-G) 组成。Mate-G 首先从文本和噪声中预测隐式中间特征(Bridge Feature)。然后CLIP-ViT将Bridge Feature映射到有用的视觉概念。此外,GALIP向CLIP-ViT添加了一些根据文本预测的Prompt以进行任务适应。预测的视觉概念缩小了文本特征和目标图像之间的差距,增强了复杂图像的合成能力。
实验结果:
作者在CUB,COCO,CC3M,CC12M数据集上进行了验证,使用FID和CLIP-SIM(CS)恒量图像的真实性和与文本的匹配度。在常规的文本到图像实验的对比上,GALIP取得了最优的的结果(如Table1所示)。
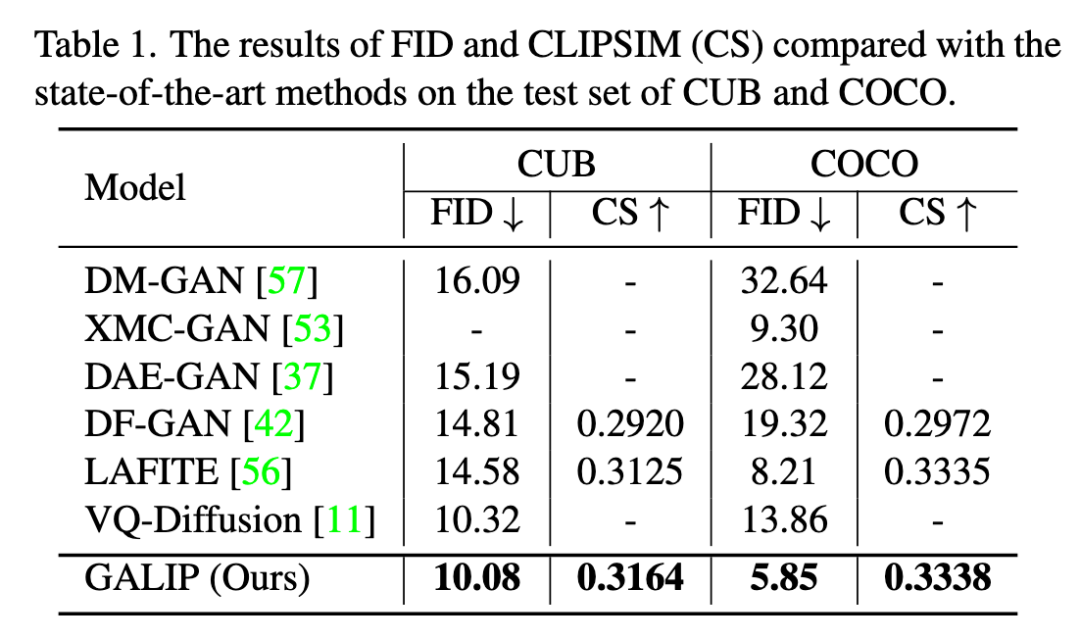
同时,与预训练大模型在Zero-shot场景下进行对比(如Table2所示),GALIP取得了和大规模预训练模型相当的结果,且显著降低了训练所需的数据和参数。
对比GALIP和当前流行的Latent Diffusion Model生成的图片,如图4所示,可以看到GALIP能够更好,更准确的生成复杂图片,而Latent Diffusion Model有时会生成错误的对象。

图 4. GALIP和Latent Diffusion Model生成图片的对比
同时,GALIP继承了GAN平滑的隐空间,这使得模型可以通过在不同的latent vector之间插值,从而生成平滑变化的图像(如图5所示)。

图 5. 通过在不同文本向量之间插值,GALIP能够生成平滑变化的图像。
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
欢迎加入 GAN/扩散模型 —交流微信群 !
扫描下面二维码,添加运营小妹好友,拉你进群。发送申请时,请备注,格式为:研究方向+地区+学校/公司+姓名。如 扩散模型+北京+北航+吴彦祖

请备注格式:研究方向+地区+学校/公司+姓名
点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!














 2701
2701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









