






本文转载自 机器之心
本文作者来自字节跳动智能创作数字人团队,介绍了名为「INFP」的交互式人像生成技术。利用该技术生成的智能体能像真人一样在多轮对话中实现自由的听说行为以及无缝的状态切换。
在大语言模型和 AIGC 的热潮下,科研人员对构建「视觉对话智能体」(Visual Chat Agent)展现出极大兴趣。其中,可实时交互的人像生成技术(Audio-Driven Real-Time Interactive Head Generation)是实现链路中极为关键的一环。它确保了在与用户的多轮对话过程中,智能体形象能够像真人一样提供自然、逼真的行为和视觉反馈,令用户获得沉浸式的交互体验。
之前的人像生成 / 驱动技术大多面向的是对话场景中的「单一方向交互」,如:说话人像生成(Talking Head Generation)或倾听人像生成(Listening Head Generation),因此无法直接应用于智能体的构建。近期陆续有一些工作开始关注研究交互式的人像生成,但它们都需要显式地指定「说话」或「倾听」的状态,且无法像真人一样在多轮对话中实现自由的听说行为以及无缝的状态切换。
近日,字节跳动提出了一套面向二元对话场景的交互式人像生成技术 INFP,该方案仅需输入一段双轨对话音频(分别来自智能体本身和对话伙伴的说话内容),即可实时驱动单张肖像照片生成相应的对话视频,且能够在多轮对话中生成自然的人物行为和反馈,例如表情、眼神、口型、姿态变化以及流畅的说话 - 倾听状态切换。

论文链接:https://arxiv.org/pdf/2412.04037
项目网页:https://grisoon.github.io/INFP
技术方案
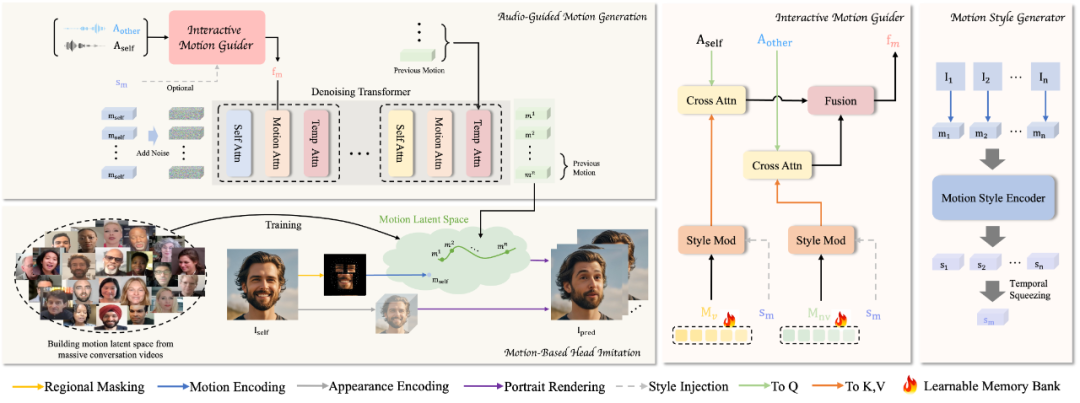
INFP 包含 2 个阶段:
1. Motion-Based Head Imitation:在第一阶段,模型从大量对话视频中学习如何提取对话时的交互和运动行为,包括非语言动作(non-verbal motion)和语言动作(verbal motion),并将其映射到运动隐空间(motion latent space)。映射后的运动编码(motion latent code)可以用来驱动肖像照片,生成相应的视频。一个好的运动隐空间应该具备高度的解耦性,即头部姿势、面部表情和情绪应该与外观完全解耦。为此,文章提出对输入图像进行面部结构离散化和面部像素遮罩处理。
2. Audio-Guided Motion Generation:在第二阶段,模型将双轨对话音频输入映射到第一阶段预训练的运动隐空间,以获得相应的运动潜码。该部分由一个交互运动引导模型(Interactive Motion Guider)和一个条件扩散模型(Conditional Ddiffusion Transformer)组成。前者将来自智能体及其对话伙伴的音频作为输入,从可学习的记忆库(Learnable Memory Bank)中检索语言和非语言动作,以构建交互式动作特征。后者利用交互式运动特征作为条件,与其他信号一起通过去噪生成运动潜码。
实验结果
在实验章节中,文中从多个方面详细对比了 INFP 和其它市面上 SOTA 方案,以此来证明该方法的有效性。
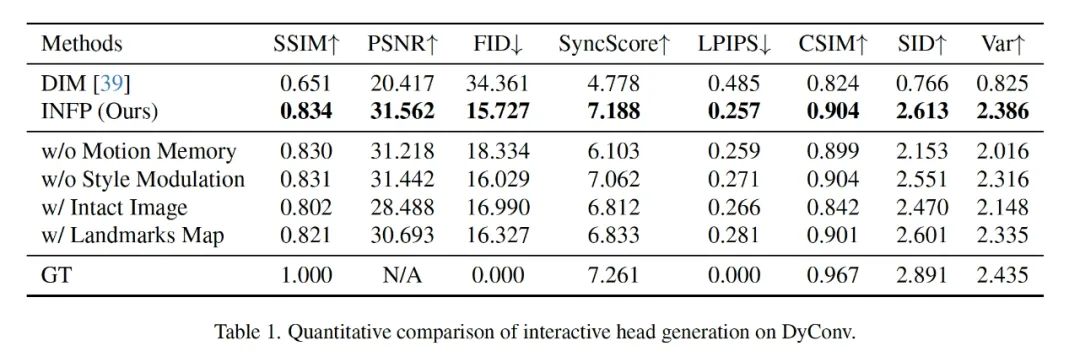
此外,文中页分别对比了 INFP 和 Talking Head Generation 以及 Listening Head Generation 方法,以此证明该方法在「单一交互」场景中的生成效果依然可以做到 SOTA。
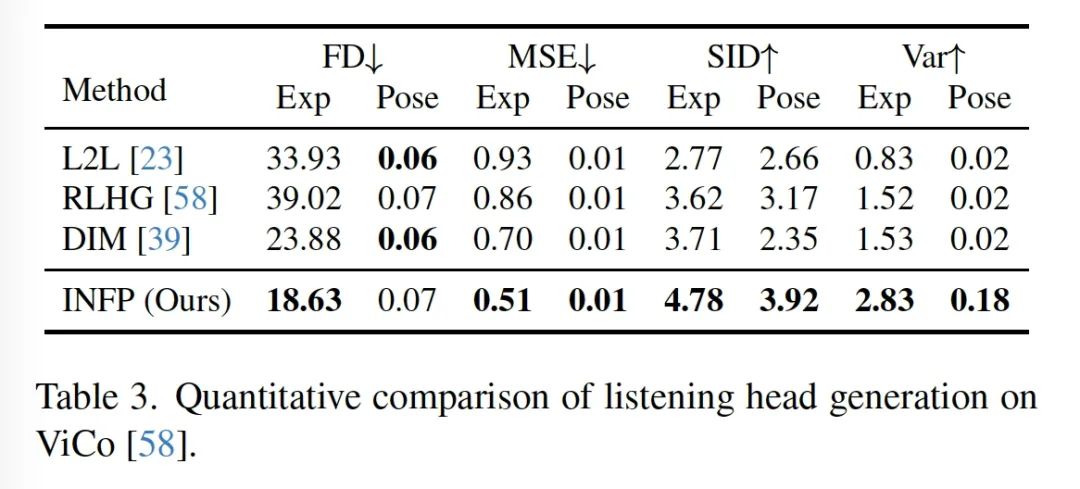
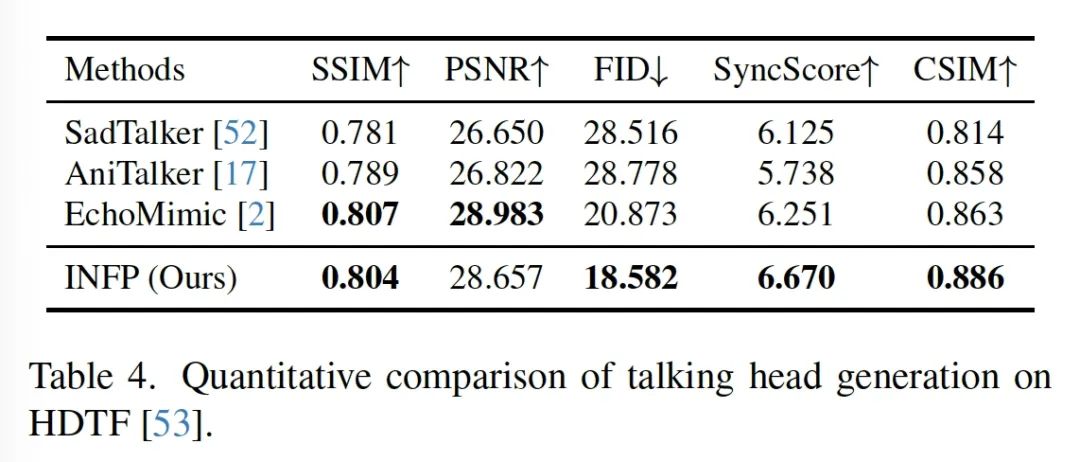
效果展示
动作多样性效果展示
非真人效果展示
即时交互 demo 效果展示
安全说明
此工作仅以学术研究为目的,会严格限制模型的对外开放和使用权限,防止未经授权的恶意利用。
团队介绍
字节跳动智能创作数字人团队,智能创作是字节跳动 AI & 多媒体技术团队,覆盖了计算机视觉、音视频编辑、特效处理等技术领域,借助公司丰富的业务场景、基础设施资源和技术协作氛围,实现了前沿算法 - 工程系统 - 产品全链路的闭环,旨在以多种形式为公司内部各业务提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。其中数字人方向专注于建设行业领先的数字人生成和驱动技术,丰富智能创作内容生态。
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
CVPR 2024 | diffusion扩散模型梳理!100+论文、40+方向!
ICCV 2023 | diffusion扩散模型方向!百篇论文
CVPR 2023 | 30个方向130篇!最全 AIGC 论文一口读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击跟进 AIGC+CV视觉 前沿技术,真香!,加入 AI生成创作与计算机视觉 知识星球!

















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









