






概要
本文只是记录了自己的一些理解
本文参考了文章如下:
LLM高效参数微调方法:从Prefix Tuning、Prompt Tuning、P-TuningV1/V2到LoRA、QLoRA(含对模型量化的解释)
苏剑林. (Apr. 03, 2021). 《P-tuning:自动构建模版,释放语言模型潜能 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8295
Adapter Tuning
- 如果为了每一个下游任务都重新训练一遍模型(对模型的参数进行全部微调),就会产生一种结果:效率非常低
- 如果只训练模型接近下游任务的一些层,效果不会很好
- 本文为了解决上述问题,提出了一种adapter结构,这种结构只需要训练很少的参数(3.6%),与全参数微调相比,只会有(0.4%)的误差。
模型结构
下图来自原始论文《Parameter-Efficient Transfer Learning for NLP》
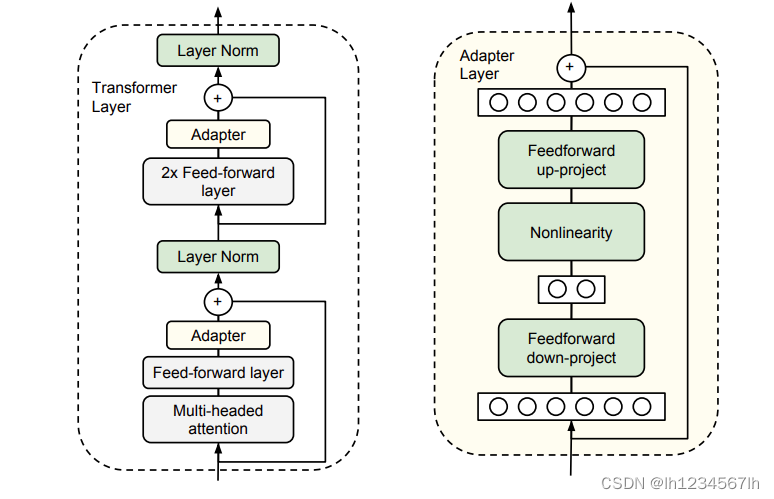
- 从图中可以看出,Adapter结构加在了前馈神经网络和LN层之间。在训练时,固定住原预训练模型的参数,只对Adapter结构和LN层以及下游的分类层进行参数调整。
- Adapter结构实际上是一个先降维再升维的过程(这一点和LORA相似,但LORA一般对LM中的注意力参数进行调整)。
Pattern-Exploiting Training(人工构建Prompt)
- Pattern-Exploiting Training 在本质上是将下游任务变成了一个完形填空的任务。
- 对于BERT而言,可以将下游任务进行如下构造:
- 对于一个情感分析任务而言:
原文:这家餐厅的菜非常可口。
改写:[MASK]满意。这家餐厅的菜非常可口。
直接预测[MASK]处的词即可。MASK={很,不} - 对于主题分类任务而言:
原文:在今天的比赛中,巴西队的内马尔再一次的受伤了。
改写:接下来报道一篇[MASK]新闻。在今天的比赛中,巴西队的内马尔再一次的受伤了。
直接预测[MASK]处的词即可。MASK={体育,娱乐,政治}
3.对于像GPT这种自回归的语言模型,也可以利用这种方法,只不过在构造的时候,只能把预测的部分放在句子末尾。
- 对于一个情感分析任务而言:
Prefix Tuning
- 如果为了每一个下游任务都重新训练一遍模型(对模型的参数进行全部微调),就会产生一种结果:效率非常低
- 不需要人工构建prompt,因为人工构建prompt的质量,会对下游任务造成很大的影响
- 使用连续的虚拟的token(virtual token)替代离散的自然语言,并对这些虚拟的token对应的embedding进行训练
模型结构
下图来自原始论文《Prefix-Tuning:Optimizing Continuous Prompts for Generation》
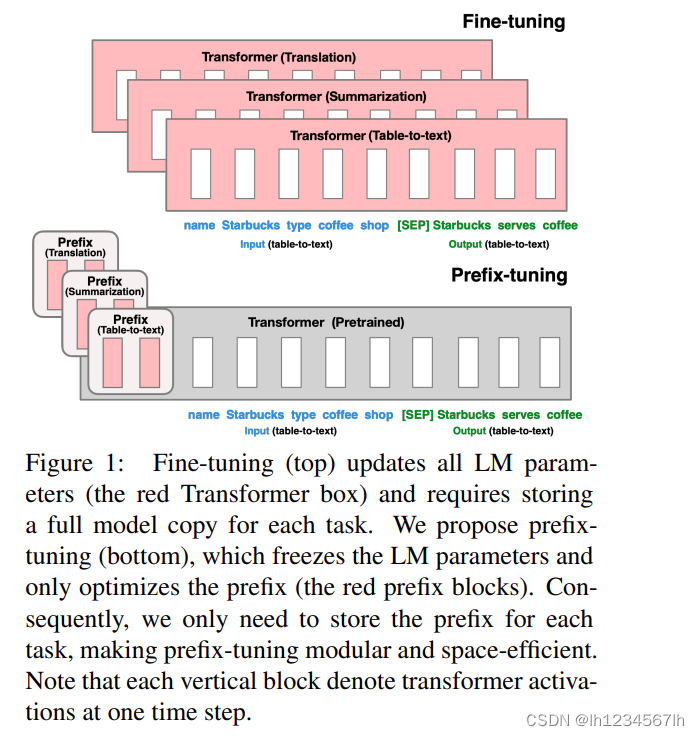
- 从图中可以看出,Prefix结构实际上是一些连续的虚拟token,这些token是与下游任务高度相关的。
- 在训练的时候,LM中原始的参数固定,只训练Prefix部分的参数。(transformer中每一层Prefix对应位置的参数都会参加训练)
- 在实际训练过程中,Prefix的参数经过了MLP层(实际上是一个低维的Prefix经过MLP升维,变成了最终我们需要的Prefix)
- 与Adapter Tuning比较,Prefix Tuning并没有改变transformer本身的结构,而Adapter Tuning 在transformer中加了两层 Adapter。
Prompt Tuning
模型结构
下图来自原始论文《The Power of Scale for Parameter-Efficient Prompt Tuning》
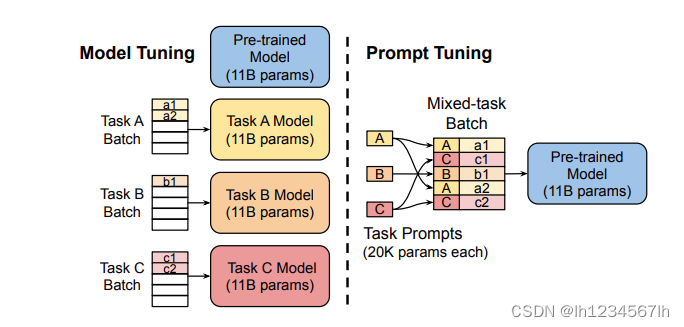
- 与Prefix Tuning相同的是,同样都是在输入的文本前面加上了虚拟的tokens。
- 与Prefix Tuning不同的是,Prompt Tuning在训练的时候,只调整了输入层的参数,而Prefix Tuning会调整Transformer中每一层虚拟tokens对应位置的参数。并且,Prompt Tuning中虚拟的tokens并没有使用MLP这样的方法进行参数重参化
P-Tuning
模型结构
下图来自原始论文《GPT Understands, Too》
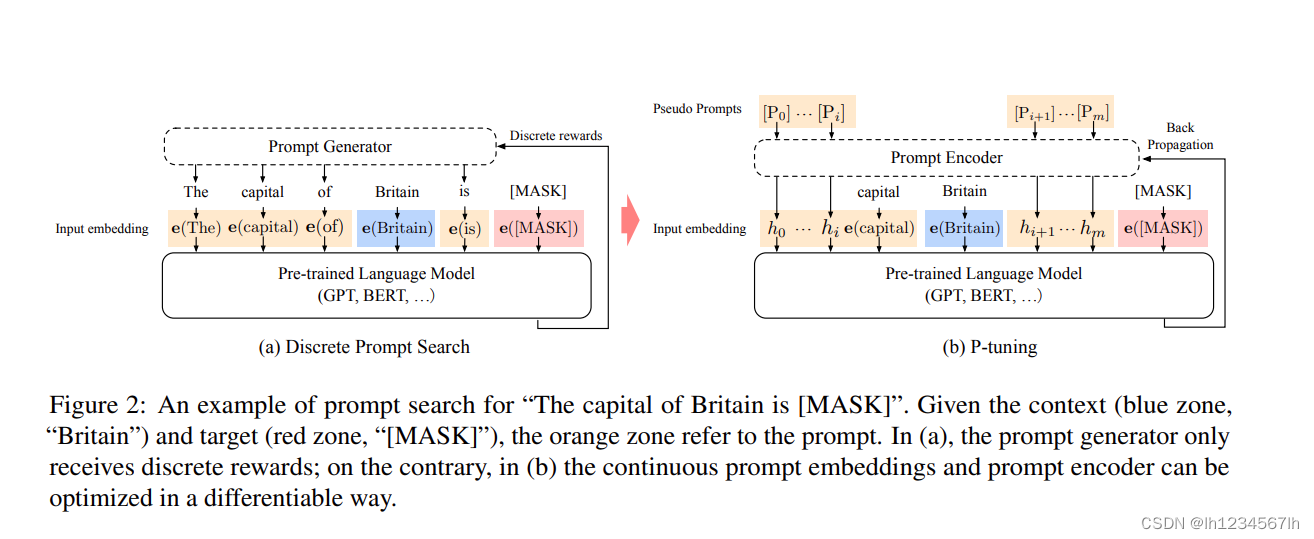
- 与Prefix Tuning相同的是,同样都是加上了虚拟的tokens。并且都使用了参数重参化的技巧(虚拟token先经过一个双向LSTM和MLP)
- 与Prefix Tuning不相同的是,只对输入层的参数进行调整(小规模样本时),(在大规模样本时,采用全参数微调),并且虚拟tokens的位置是可选的。
P-Tuning V2
模型结构
下图来自原始论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
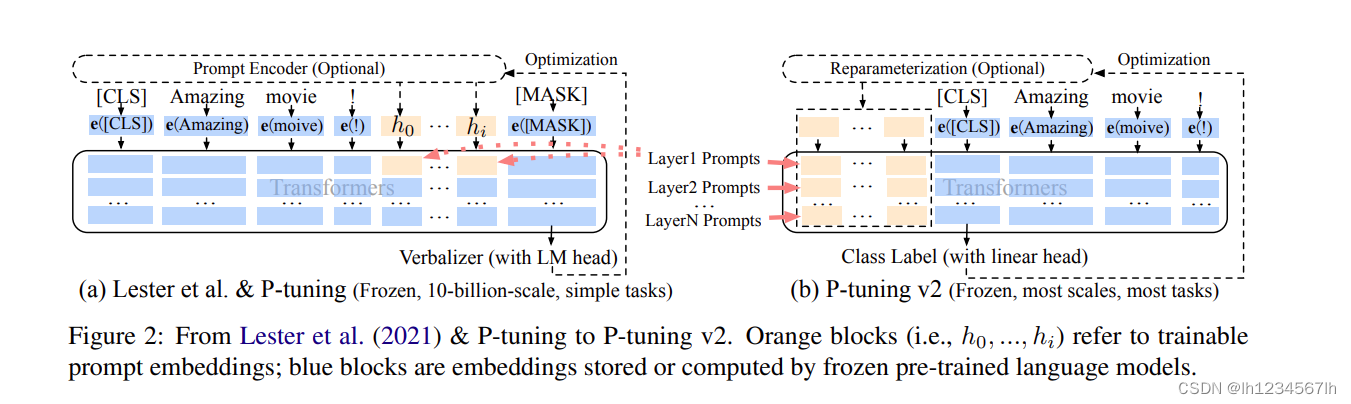
- 与P-Tuning不同的是,对Transformer所有层中虚拟token对应的位置参数进行微调(这与Prefix tuning保持一致)(不同层中的虚拟token加入到输入序列中,并独立于其他层间(而不是由之前的transformer层计算))
- 去掉了参数重参化这一步骤
- 多任务学习,可以提供一个较好的初始化
- 使用了[CLS]来预测sentence-level class
LORA
模型结构
下图来自原始论文《LoRA: Low-Rank Adaptation of Large Language Models》
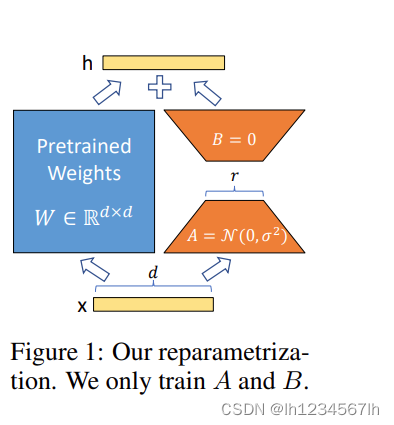
- 选定transformer中LORA需要微调的层(通常来说可以是任意一层,但一般微调attention层)
- 随机生成一个降维矩阵A和升维矩阵B,然后对A B矩阵进行微调,原始参数进行固定
- 在推理的时候,将AB矩阵进行相乘,然后将参数加在微调的目标层上
















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











