









目录
OpenAI CartPole-v0 模型例程实现对杆控制其不倒
目的
需要实现一个深度学习的动作控制,并图形展示出来,度娘查找OpenAI Gym比较适合,对OpenAI Gym例程进行实现。(争取在本篇文章实现持续更新)
更新日期:2021-03-21
OpenAI介绍:
由诸多硅谷、西雅图科技大亨联合建立的人工智能非营利组织。2015年马斯克与其他硅谷、西雅图科技大亨进行连续对话后,决定共同创建OpenAI,希望能够预防人工智能的灾难性影响,推动人工智能发挥积极作用。特斯拉电动汽车公司与美国太空技术探索公司SpaceX创始人马斯克、Y Combinator总裁阿尔特曼、天使投资人彼得·泰尔(Peter Thiel)以及其他硅谷巨头去年12月份承诺向OpenAI注资10亿美元。
OpenAI运行环境:
python 3.8
OpenAI Gym 0.18.0
tensorflow 2.4.1 已经集成了keras 让构建深度学习更便捷。
参考以下文章:
https://geektutu.com/post/tensorflow2-gym-nn.html
https://tensorflow.google.cn/api_docs/python/tf/keras/Model?hl=en
https://cloud.tencent.com/developer/article/1691852
OpenAI CartPole-v0 模型例程实现对杆控制其不倒
OpenAI Gym 自带有多个环境模型,所谓环境模型,就是OpenAI Gym对规定动作进行了封装,并设定各项参数和条件。
以 CartPole-v0 环境为例,目标是杆子能始终和小车垂直,根据官方 wiki[2],「观测状态」有四维:小车位置、小车速度、杆的角度和杆顶端的速度(初始状态每个值均在 ±0.05 区间内取随机值);「终止条件」有三条:杆的角度大于 ±12 度,小车的位置超过 ±2.4,以及迭代次数超过 200(v1 为 500);每个步骤的「奖励」均为 1(包括终止步)
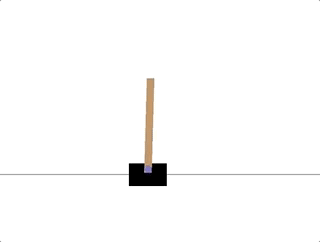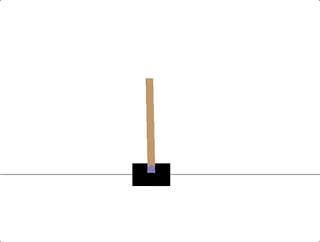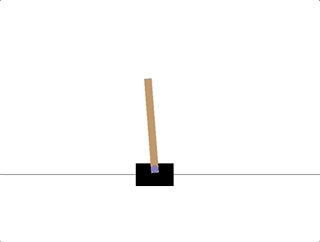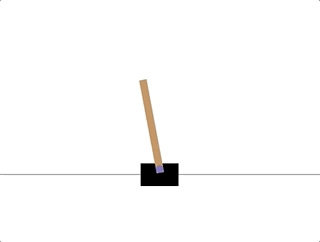
CartPole-v0 环境有四个参数
| 概念 | 解释 | 示例 |
|---|---|---|
| State | list:状态,[车位置, 车速度, 杆角度, 杆速度] | 0.02,0.95,-0.07,-1.53 |
| Action | int:动作(0向左/1向右) | 1 |
| Reward | float:奖励(每走一步得1分) | 1.0 |
| Done | bool:是否结束(True/False),上限200回合 | False |
创建一个可视环境,完全随机,如果达到了Done的条件,比如杆的角度大于 ±12 度,就重置,其中observation 是数组,代表[车位置, 车速度, 杆角度, 杆速度],
print(state) 后显示array([ 0.0015817 , -0.0183442 , 0.01170629, 0.01074688]) import gym
env = gym.make("CartPole-v1")
state = env.reset()
for _ in range(100):
env.render()
action = env.action_space.sample() # your agent here (this takes random actions)
state, reward, done, info = env.step(action)
if done:
state = env.reset()
env.close()构建整个训练程序:
import random
import gym
import numpy as np
from tensorflow.keras import models, layers
def generate_data_one_episode():
'''生成单次游戏的训练数据'''
x, y, score = [], [], 0 #X :#State list:状态,[车位置, 车速度, 杆角度, 杆速度]的四个参数 Y:Action的两个参数,左或右, reward的累加
state = env.reset()
while True:
action = random.randrange(0, 2)
x.append(state)
y.append([1, 0] if action == 0 else [0, 1]) # 记录数据 action=0,记录为数组[1,0],否则数组[ 0,1]
state, reward, done, _ = env.step(action) # 执行动作,奖励,坚持得越久得分越多。直到达到限定条件,比如循环200次,车位置超出界面等
score += reward
if done:
break
return x, y, score
def generate_training_data(expected_score=100):
'''# 生成N次游戏的训练数据,并进行筛选,选择 > 100 的数据作为训练集'''
data_X, data_Y, scores = [], [], []
for i in range(10000):
x, y, score = generate_data_one_episode()
if score > expected_score:
data_X += x
data_Y += y
scores.append(score)
print('dataset size: {}, max score: {}'.format(len(data_X), max(scores)))
return np.array(data_X), np.array(data_Y)
#主程序开始
env = gym.make("CartPole-v0") # 加载游戏环境
STATE_DIM, ACTION_DIM = 4, 2 # State 维度 4, Action 维度 2
model = models.Sequential([
layers.Dense(64, input_dim=STATE_DIM, activation='relu'),#输入层4,激活函数relu
layers.Dense(20, activation='relu'),
layers.Dense(ACTION_DIM, activation='linear')])
model.summary() # 打印神经网络信息
x, y, score = generate_data_one_episode()
print(x,y,score) #调试
#对神经网络进行编译和迭代,保持模型
data_X, data_Y = generate_training_data()
model.compile(loss='mse', optimizer='adam')
model.fit(data_X, data_Y,epochs=100)
model.save('CartPole-v0-nn.h5') # 保存模型其中generate_training_data()生成多个训练数据并放到 x, y,score 三个数组总 ,data_X包含了该环境的4个参数,data_Y为左右动作,score为对应data_X,data_Y,的数据集分数。
将以上训练结果矩阵化。使用tensorflow.keras models模块建立多层序列(Sequential)(参照tensorflow.keras说明,和keras不完全一样)建立一个输入为4个维度(参数),64个隐藏神经元(激活函数用relu),20个激活神经元,输出为2维度(参数)的深度学习框架,损失函数采用"mse" (均方误差),优化模式采用adam(使用动量和自适应学习率),进行收敛,epochs=100,表示重复训练100次。如果次数少,效果不好,得分偏低,多次训练更容易接近最优解。训练后在当前目录生成模型文件,两种文件格式.tf和.h5。
加载模型,效果展示,如果效果不好,需要在训练程序中在训练几次模型就可以了。
# predict.py
import time
import numpy as np
import gym
from tensorflow.keras import models
saved_model = models.load_model('CartPole-v0-nn.h5') # 加载模型
env = gym.make("CartPole-v0") # 加载游戏环境
for i in range(5):
state = env.reset()
score = 0
while True:
time.sleep(0.01)
env.render() # 显示画面
action = np.argmax(saved_model.predict(np.array([state]))[0]) # 预测动作
state, reward, done, _ = env.step(action) # 执行这个动作
score += reward # 每回合的得分
if done: # 游戏结束
print('using nn, score: ', score) # 打印分数
break
env.close()
运行后效果:

总体实现比较简单易于理解,这就是keras的优越性。
编译参数loptimizer=''的选择可以参照 tf.keras.optimizers

loss='',可以参照 tf.keras.losses

使用OpenAI Gym 增加了深度学习的趣味性和可视性,难度大大降低。
OpenAI 自定义环境模型:
进入安装目录,编辑 __init__.py文件
C:\Users\xxx\AppData\Local\Programs\Python\Python38\Lib\site-packages\gym\envs添加注册
register(
id='BallView-v0',
entry_point='gym.envs.classic_control:BallEnv',
max_episode_steps=200,
reward_threshold=195.0,
)并在目录下新建BallView-v0.py文件
C:\Users\xxx\AppData\Local\Programs\Python\Python38\Lib\site-packages\gym\envs\classic_control















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









