







Beautiful Soup介绍
- Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
- Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
- Beautiful Soup已成为和lxml、html5lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
模块安装
pip install beautifulsoup4模块引入
from bs4 import BeautifulSoup解析html
1、通过requests请求url,获取到html内容;
2、用BeautifulSoup解析html内容,生成文档树;
3、用BeautifulSoup的方法遍历文档树;
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup
url="https://www.baidu.com"
r=requests.get(url)
html = r.content.decode("utf-8")
# 或者用r.text
soup=BeautifulSoup(html,'html.parser')
# 剩下的工作就是通过soup去获取需要的节点soup=BeautifulSoup(html,'html.parser')
解析方式主要推荐使用:html.parser 或者 lxml
下面是常见解析器:
遍历文档树
1、使用.的方式按照层级查找
soup.html.head.title
如果同一层级下有多个同名节点,只能返回第一个
2、使用函数方式
contents: 查找节点的直接子节点,但是换行也会被当成是一个节点。
children:返回一个可迭代对象,内容和contents相同
descendants:返回一个可迭代对象,返回所有的子孙节点,换行也会被当成是一个节点
parent:获取直接上级父节点
parents:获取所有的父节点
next_subling, previous_sibling:前后兄弟节点,只遍历同一级别的节点
next_element, previous_element:前后节点,会遍历子孙节点
搜索文档树
find_all( name , attrs , recursive , text , **kwargs )
遍历文档树匹配符合规则的所有的标签列表,返回list
1、find_all(Tag)
Tag标签名查找,可以写字符串,可以写列表、正则。
soup.find_all("img") # 传入字符串,找对应的标签
find_all(["h1","h2"]) # 列表方式,找多个标签类型
find_all(re.compile("h[1-6]")) # 正则匹配
2、find_all(Tag,attrs={})
attrs属性查找。
find_all("div",attrs={"class":"txList"}) # 查找class属性包含txList的节点
find_all("div",attrs={"data-id":re.compile("\d")}) # 正则匹配,查找data-id的属性都是数字的标签
3、find_all(Tag,text="")
按照文本内容查找。
print(soup.find_all("a",text="新闻")) # 文本内容是“新闻”的所有a标签
find_all(text="文本测试")[0].parent # 没有带标签名,直接文本查找,默认是文本自己
find_all(text=re.compile('女')) #正则,匹配文本中包含女的 文本
4、limit=num
限定匹配次数
find_all(text=re.compile('女'),limit=3) 只查找3次
5、find()
只返回第一个结果,返回的是Tag
find("a",text="文本测试").parent 不需要[0]
结合节点操作
print(soup.find(id='head').div.div.next_sibling.next_sibling)
可以通过节点函数获取父节点、兄弟节点、前后节点
find_parents() 找到所有的父节点
find_parent() 找到直接上级父节点
find_next_siblings() 找到所有后面的兄弟节点,只找同级节点,包括换行符
find_next_sibling() 找到下一个兄弟节点
find_previous_siblings() 找到所有前面的兄弟节点,只找同级节点,包括换行符
find_previous_sibling() 找到前面一个兄弟节点
find_all_next() 找到所有后面的节点,包括子孙节点
find_next() 找到下一个节点
find_all_previous() 找到所有前面的节点,包括子孙节点
find_previous() 找到前面一个节点
例子:如果下面列表中,第二个dt ,<dt>《圣墟》正文卷</dt>,后面所有的dd内容呢?

# 找到第二个dt的所有后面的兄弟节点
dd_tags = soup.find_all("dt")[1].find_next_siblings()获取标签的属性和文本
1、取属性,attrs
# 获取标签对象的所有属性,返回一个字典dict
soup.find("h2").a.attrs
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup
url="https://www.baidu.com"
r=requests.get(url)
html = r.content.decode("utf-8")
soup=BeautifulSoup(html,'html.parser')
print(soup.find("input",attrs={"id":"su"}).attrs)
# 打印结果
# {'value': '百度一下', 'class': ['bg', 's_btn'], 'autofocus': '', 'type': 'submit', 'id': 'su'}
# 获取标签对象的href属性
soup.find("h2").a.attrs["hef"]
2、获取文本 text string
text 可以获取标签的所有文本,包含子孙节点的文本
string 只能获取当前标签的文本,无内容返回None
soup.find("h2").a.text
soup.find("h2").a.string
soup.find("div",attrs={"class":"subnav-1"}).text
CSS选择器,select的使用
select() 使用css选择器查找标签,返回列表
.点好代表查找class
#代表查找ID
soup.select("div.txList") #div标签中,class是txList的标签列表
soup.select("div#1002") #div标签中,ID是1002的标签列表
soup.select("div[data-id]") #div标签中,带有data-id属性的标签列表
soup.select("div[data-id=45]") #div标签中,data-id属性是45的标签列表
当然,select也可以和find函数一起使用
soup.select("div#u1")[0].find_all("a",attrs={"name":"tj_trhao123"})
其他函数
prettify() 格式美化代码输出
print(soup.prettify())
# 或者带formatter参数指定格式输出
print(soup.prettify(formatter="html"))
练习题:
爬取前程无忧的招聘职位信息。包括的信息有 职位名,职位url,公司名,工作地址,薪资,发布时间,保存到csv文件中。

看下html的结构,各个信息的位置:
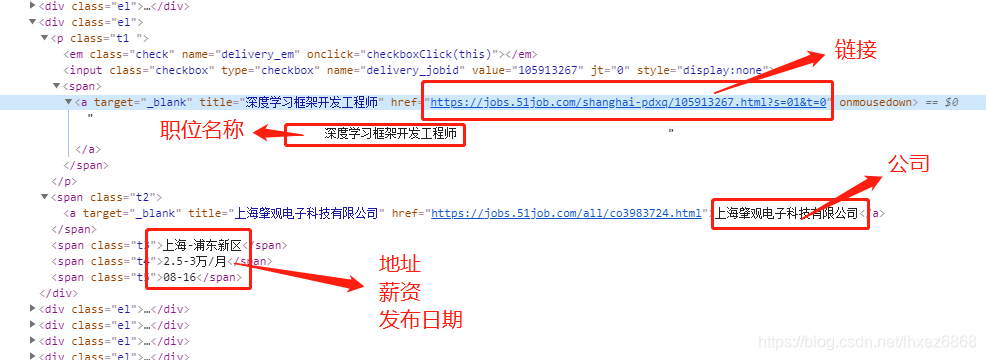
上手,直接贴代码
#-*- coding: UTF-8 -*-
import requests,time
from bs4 import BeautifulSoup
def get_jobs(keyword,page):
'''
爬取前程无忧上海地区的招聘信息,结果保存到csv文件中
keyword:职位搜索关键字
page:搜索多少页,到末尾了会自动停止
'''
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Referer":"https://search.51job.com/list/020000,000000,0000,00,9,99,python%25E5%25BC%2580%25E5%258F%2591,2,10.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
}
current_page=1
# 保存的文件名称
filename = keyword+",薪资" + str(int(time.time())) + ".csv"
while current_page<=page:
url = "https://search.51job.com/list/020000,000000,0000,00,9,99," + keyword + ",2," + str(current_page) + ".html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
r=requests.get(url,headers=headers)
html = r.content.decode("gbk")
soup=BeautifulSoup(html,"html.parser")
div_tags=soup.find("div",attrs={"id":"resultList"}).find_all("div",attrs={"class":"el"})[1:]
with open(filename,"a",encoding="utf-8") as file:
for once in div_tags:
name = once.p.span.a.text.strip()
url = once.p.span.a.attrs["href"]
company = once.find("span",attrs={"class":"t2"}).a.text
address = once.find("span",attrs={"class":"t3"}).text
sal = once.find("span",attrs={"class":"t4"}).text
if sal=='':
sal="薪资面议"
release_time = once.find("span",attrs={"class":"t5"}).text
# print(name,url,company,address,sal,release_time)
file.write("%s,%s,%s,%s,%s,%s\n"%(name,company,address,sal,release_time,url))
print("第%d页爬取完成"%(current_page))
current_page = current_page + 1
# 判断是否到最后一页了
next_page = soup.find("a",text="下一页")
if next_page==None:
print("已经爬取到最后一页了")
break
get_jobs("机器学习",50)














 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









