







最终目的:建立模型预测乘客是否生还
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 不用写plt.show()
%matplotlib inline
#路径根据自己的数据放置位置表示
titanic=pd.read_csv('H://data.csv')可视化数据
#查看pclass分布情况
sns.countplot(x="pclass",data=titanic,palette="Set2")
三等舱的居多,当然一等舱,二等舱的人也不少
#查看pclass与生存的关系
sns.countplot(x="pclass",hue="survived",data=titanic,palette="Set2")
可以看出一等舱的生存率很高,反观三等舱的情况不容乐观,死亡人数接近于生存人数的两倍,再看看生存率:
# pclass生存率
titanic[['pclass', 'survived']].groupby(by=['pclass'], as_index=False).mean().sort_values(by=['survived'], ascending=False)
看出船票等级越高,生存率也越高
#各舱位总量所占比
titanic.groupby('pclass').agg('size')/(len(titanic))
看出一,二等舱的人数接近,三等舱人数占总人数过半
#sex与生存之间的关系
sns.countplot(x="sex",hue="survived",data=titanic,palette="Set2")
男的感觉死的差不多了,女性生存人数有点多呢,估计是和西方lady first有关吧
# 按照Sex分类,生存率
titanic[['sex', 'survived']].groupby(by=['sex'], as_index=False).mean().sort_values(by=['survived'], ascending=False)
女性相比于男性生存率更高
# age存活率分布
a=sns.FacetGrid(titanic,hue='survived',aspect=6)
a.map(sns.kdeplot,'age',shade=True)
a.set(xlim=[0,titanic['age'].max()])
a.add_legend()

年龄居于20到30岁的人数占比最多,但同时也看得出在这个阶段的死亡率也比生存率要高,在处于15岁以下的这个阶段虽然人数占比较少,但生存率较高
#pclass,age的分布情况
sns.boxplot(x='pclass',y='age',data=titanic,palette="Set2")
一等舱主要集中于30-50岁,二等舱主要集中于25-35岁,也有部分集中于60-70岁之间的群体,三等舱主要集中于20-35岁,同样有部分集中于高年龄阶段
#sex,age与生存的关系
sns.violinplot(x='sex', y='age',hue='survived',data=titanic,split=True,palette={0: "r", 1: "b"});
女性处于14岁下的生存率相对较低,而在22岁左右的生存率较高,男性在15岁下的生存率较高,但在22岁左右的死亡率偏高
#fare与生存的关系
plt.figure(figsize=(10, 5))
plt.hist([titanic[titanic['survived'] == 1]['fare'],titanic[titanic['survived'] == 0]['fare']],
stacked=True,
color = ['b','r'],
bins = 50,
label = ['survived','dead'])
plt.xlabel('fare')
plt.ylabel('number of passengers')
plt.legend()
低票价的人数众多,但同时死亡人率也是相当之高的,票价越贵的 生存机率越高
#pclass,fare与生存的关系
sns.swarmplot(x='pclass',y='fare',hue='survived',data=titanic,palette='husl')
舱位越高级的平均票价越贵,同时生存率越高
#age,fare与生存的关系
plt.figure(figsize=(20, 10))
bt = plt.subplot()
bt.scatter(train[train['survived'] == 1]['age'], train[train['survived'] == 1]['fare'],
c='blue', s=train[train['survived'] == 1]['fare'])
bt.scatter(train[train['survived'] == 0]['age'], train[train['survived'] == 0]['fare'],
c='orange', s=train[train['survived'] == 0]['fare'])
这里也可以看出,票价低的除了低年龄段的生存率较大,其他年龄段基本都是处于dead的状态居多
#各舱位的平均票价
ax = plt.subplot()
ax.set_ylabel('average fare')
titanic.groupby('pclass').mean()['fare'].plot(kind='bar', ax = ax);
舱位越高级,平均票价越高
#embarked与生存的关系
sns.countplot(x="embarked",hue="survived",data=titanic)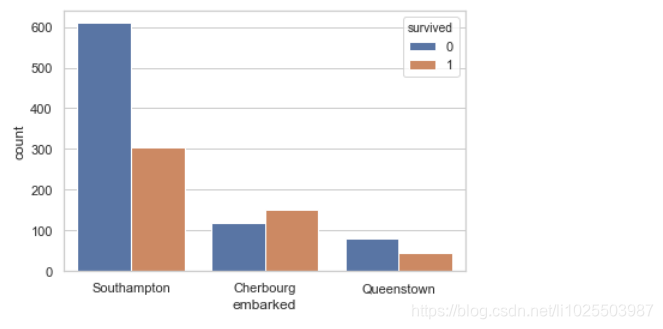
在C处港口上船的生存率偏高些
#embarked,fare与生存的关系
fig = plt.figure(figsize=(25, 7))
sns.violinplot(x='embarked', y='fare', hue='survived', data=titanic, split=True, palette={0: "r", 1: "b"});
在C港口上船的富人更多些,同时也是可以看出票价越高,生存率越大
#boat与生存的关系
fig = plt.figure(figsize=(25, 7))
sns.countplot(x='boat',data=titanic,hue='survived')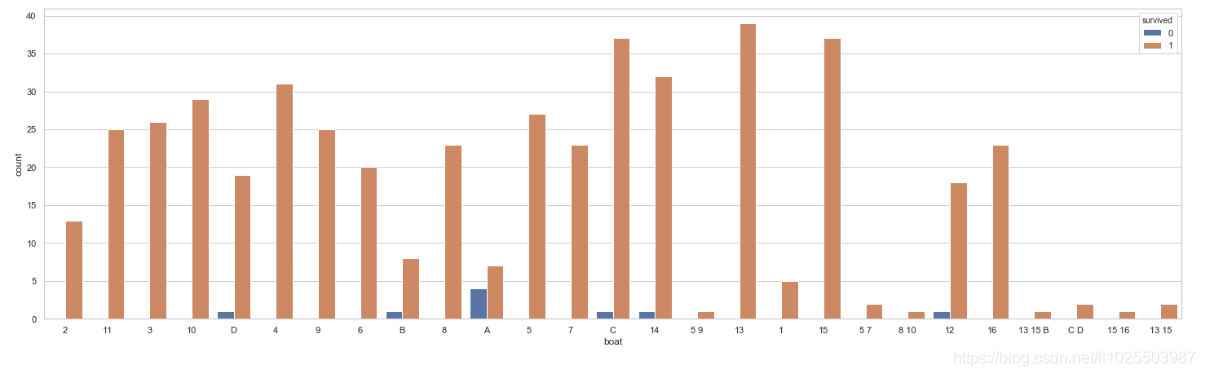
看得出上了救生船的人基本都活了下来
数据清洗处理
#查看各个变量缺失遗漏情况
print(titanic.isnull().sum())
#查看是否有重复
print(titanic.duplicated().value_counts())
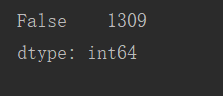
没用重复,若有重复,会出现true xxx(重复量),处理方法如下:(没有重复就可以不用了)
#用来删除重复
titanic=titanic.drop_duplicates()填充fare
#以中位数填充缺失fare
titanic["fare"].fillna(titanic.fare.median(),inplace=True)可以看出主要缺失的是age(年龄),cabin(房间号),boat(救生船号),body(尸体编号),home.dest(家乡),body,boat与生存与否带有强关联性对预测不起作用,cabin和home.dest缺失量太大,直接删除变量
titanic=titanic.drop(['cabin','home.dest','body','boat'], axis=1)现在就需要来处理年龄大量空缺的问题,在此之前先观察一下乘客身份,作出区分以便更好处理年龄
#查看乘客姓名,提取有用信息
identity = set()
for name in titanic['name']:
identity.add(name.split(',')[1].split('.')[0].strip())
print(identity)主要分为皇室,先生,太太,小姐,官员,主人(代指上流社会人士)
#用于转换姓名到身份的字典
Titanic_Dictionary = {
"Capt": "Officer",
"Col": "Officer",
"Don": "Royalty",
"Dona": "Royalty",
"Dr": "Officer",
"Jonkheer": "Royalty",
"Lady" : "Royalty",
"Major": "Officer",
"Master" : "Master",
"Miss" : "Miss",
"Mlle": "Miss",
"Mme": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Ms": "Mrs",
"Rev": "Officer",
"Sir" : "Royalty",
"the Countess":"Royalty"
}#添加新列title,用于存放身份
titanic['identity']='1'
def get_identity():
titanic['identity'] = titanic['name'].map(lambda name: name.split(',')[1].split('.')[0].strip())
titanic['identity'] = titanic.identity.map(Titanic_Dictionary)
return titanic
titanic = get_identity()
到此身份处理完成,在瞅一眼
titanic.head()
因为年龄对于生存率有一定关系,不可能直接删除这263个数据,简单处理年龄大量空缺的问题----用男女对应的平均年龄大小填进去(这样处理并不是最佳处理方案,因群体类别不同所导致的差异会不同,这也是为什么前面先处理身份,现在就好处理了)
#根据不同群体划分,得到对应的年龄中位值
grouped_try = titanic.groupby(['sex','pclass','identity'])
grouped_median_try = grouped_try.median()
grouped_median_try = grouped_median_try.reset_index()[['sex', 'pclass', 'identity', 'age']]
grouped_median_try.head()
接下来就是填充
def fill_age(row):
condition = (
(grouped_median_try['sex'] == row['sex']) &
(grouped_median_try['identity'] == row['identity']) &
(grouped_median_try['pclass'] == row['pclass'])
)
return grouped_median_try[condition]['age'].values[0]
def process_age():
global titanic
titanic['age'] = titanic.apply(lambda row: fill_age(row) if np.isnan(row['age']) else row['age'], axis=1)
return titanic
titanic=process_age()至此再看看还有空缺值没处理的没
titanic.isnull().sum()

缺失值已全部处理完成
特征提取以及属性处理
(1)、数据分类
查看数据类型,分为3种数据类型。并对类别数据处理:用数值代替类别,并进行One-hot编码。
1.数值类型:
年龄(Age),船票价格(Fare),同代直系亲属人数(SibSp),不同代直系亲属人数(Parch)
2.时间序列:无
3.分类数据:
1)有直接类别的
乘客性别(Sex):男性male,女性female
登船港口(Embarked):出发地点S=英国南安普顿Southampton,途径地点1:C=法国 瑟堡市Cherbourg,出发地点2:Q=爱尔兰 昆士敦Queenstown
客舱等级(Pclass):1=1等舱,2=2等舱,3=3等舱
2)字符串类型:可能从这里面提取出特征来,也归到分类数据中
乘客姓名(Name)
客舱号(Cabin)
船票编号(Ticket)
对家庭属性进行处理

对船票编号属性进行处理

分别用皮尔逊相关系数和随机森林分类器查看属性关联性
皮尔逊相关系数


![]()
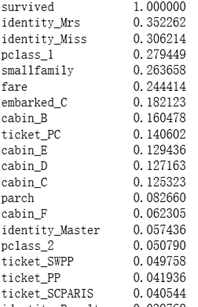
随机森林分类器


选取特征

训练模型
对逻辑回归模型训练
















 4507
4507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









