







 该博客通过Kaggle泰坦尼克号数据集进行可视化分析,探讨了乘客生存情况与性别、年龄、家庭人数、仓位等级、船票价格和登船港口等因素的关系。结果显示,女性和家庭人数少的乘客存活率较高,一等舱乘客存活比例显著高于其他仓位,Cherbourg港口登船的乘客存活率最高。
该博客通过Kaggle泰坦尼克号数据集进行可视化分析,探讨了乘客生存情况与性别、年龄、家庭人数、仓位等级、船票价格和登船港口等因素的关系。结果显示,女性和家庭人数少的乘客存活率较高,一等舱乘客存活比例显著高于其他仓位,Cherbourg港口登船的乘客存活率最高。
#设置ast_node_interactivity = "all"使得可以同时输出多条语句
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
#导入需要的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
df=pd.read_csv(r'E:\python\data\titanic\train.csv')
df.head()
针对每一个字段做一个简单的解释: PassengerId: 乘客ID;
Survived: 生存情况,0代表不幸遇难,1代表存活;
Pclass: 仓位等级,1为一等舱,2为二等舱,3为三等舱;
Name: 乘客姓名;
Sex: 性别;
Age: 年龄;
SibSp: 乘客在船上的兄妹姐妹数/配偶数(即同代直系亲属数)
;
Parch: 乘客在船上的父母数/子女数(即不同代直系亲属数);
Ticket: 船票编号;
Fare: 船票价格;
Cabin: 客舱号;
Embarked: 登船港口(S: Southampton; C: Cherbourg Q: Queenstown)
先看下数据的大小和基本信息
df.shape
df.info()
(891, 12)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB数据一共有891行,12列,进一步查看描述性统计
df.describe()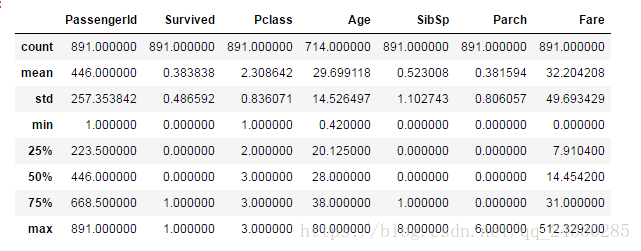
整体情况
看一下生存情况,即本次沉船事件中,有多少人生存下来
Survived=df['Survived'].value_counts()
Survived
#计算生存占比
survive_prod=Survived/Survived.sum()
survive_prod
0 549
1 342
Name: Survived, dtype: int64
0 0.616162
1 0.383838
Name: Survived, dtype: float64可以看到,超过60%的人遇难,我们将其绘制成饼图
plt.rc('font',family='SimHei',size=12)#正常显示中文,并设置字体大小
fig=plt.figure(figsize=(6,6))
ax1=fig.add_subplot(1,1,1)
labels=['遇难','存活']
colors=['#03A2FF','#64C8FF']
ax1.pie(survive_prod,labels=labels,colors=colors,startangle=90,autopct='%1.1f%%')
ax1.set_title('存活占比')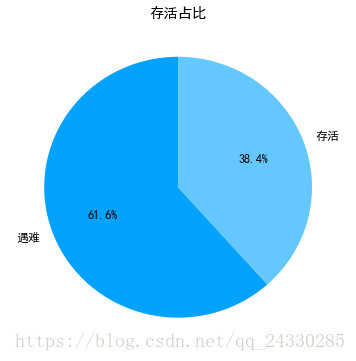
性别分布
#按生存情况和性别分组
sex_df=df.groupby(['Survived','Sex']).size()
sex_df
Survived Sex
0 female 81
male 468
1 female 233
male 109
dtype: int64#进一步将数据转化成DataFrame
sex_df=sex_df.unstack('Sex')
sex_df=sex_df.rename(index={
0:'遇难',1:'存活'})
sex_df
sex_prod=sex_df/sex_df.sum()
sex_prod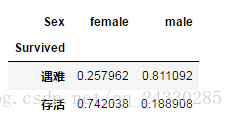
从统计结果看到女性81人遇难,占比约26%,男性468人遇难,占比约81%
plt.rc('font',family='SimHei',size=12)#正常显示中文,并设置字体大小
fig=plt.figure(figsize=(6,6))#设置画布大小
ax1=fig.add_subplot(1,1,1)#添加子图
x=range(2)
a=sex_prod.loc['遇难',:]
b=sex_prod.loc['存活',:]
ax1.bar(x,a,label='遇难',color='#03A2FF')
ax1.bar(x,b,bottom=a,label='存活',color='#64C8FF')#通过bottom参数绘制堆积柱状图
ax1.set_xticks(range(3))#设置x轴刻度,之所以设置为3,是为了让图例显示在空白处
ax1.set_xticklabels(['female','male'])#设置x轴刻度标签名称
ax1.set_yticks([])
ax1.legend(['遇难','存活'],loc='upper right')#设置图例名称及位置(upper/center/lower,left/center/right)
ax1.set_title('不同性别存活分布')#设置标题
#添加数据标签
for x,y,z in zip(range(2),a,b):
ax1.text(x,y/2,'{:.1%}'.format(y))
ax1.text(x,y+z/2,'{:.1%}'.format(z))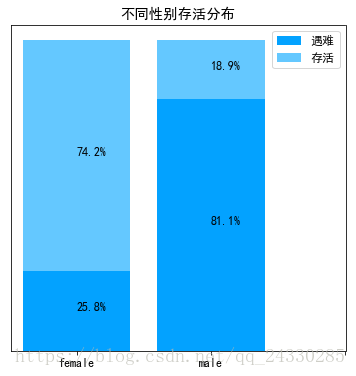
年龄分布
#提取需要的数据
age_df=df.loc[:,['Sur 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4793
4793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









