







第一篇博文选择PageRank算法以表达对Larry Page这种不断专心追求技术的人最崇高的敬意!
本文可能比较粗略,大牛看着就是小儿科了,这就是自己一个下午的成果,还没有完善,写的也比较零散,最近事情很多,就先不总结了。顺便推荐一个PageRank的神奇网站,当时看到这个网站的瞬间,就震撼了~https://googledrive.com/host/0B2GQktu-wcTiaWw5OFVqT1k3bDA/
Google所提供的快速搜索速度及高命中率搜索结果,都是基于其复杂文本匹配算法以及其搜索程序所使用的PageRank技术(网页级别技术)。
PageRank的原理其实很简单,可以理解成一种投票,只不过这里是用是否有链接链入页面A,来决定A的等级的。相当于有页面B链入页面A,那么给页面A投一票,再有页面C链入页面A,再给A投一票。只是这里的票数的计算方法,是有些不同的。
我们现在将用户点击链接的行为,视为一种不关心内容的随机行为。那么用户在当前页面跳转到下一个页面的概率,就完全由页面上链接数量决定了。也就是说,一个页面被到达的概率就等于所有链入它的页面上链接的被单击概率之和。而因为用户不可能无限制的单击链接,常常因为疲倦就直接跳入另一个页面了,所以我们引入阻尼系数d,d就可以表示用户一直单击下去的概率,1-d就是页面本身所具有的网页级别。(借鉴自随机冲浪模型(the random surfer model))
PageRank的算法1:
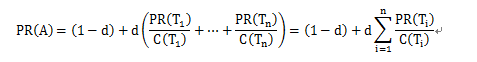
其中,PR(A)是页面A的级别,是页面的级别,页面链向页面A,是页面链出的链接数量,d是阻尼系数,取值为0~1之间。
由上面的公式,我们可以看出,页面的级别是由链向它的页面的级别决定的,但是每一个链入页面的贡献又是不同的。如果页面中Ti的链出越多,也就是c(Ti)值越大,那么对于当前页面A的级别计算的贡献就越小。这就相当于对于每一个链入页面赋以不同的权值,这个权值和链入页面的级别有关,也和链入页面的链出数量有关。
同时,页面A的链入页面的数量越多,其网页级别就有可能越高。
PageRank的改进,算法2:

其中N是互联网上所有网页的数量。
由此所有页面的网页级别形成的一个概率分布,所有页面的网页级别之和为1。
在实际使用PageRank时,Google采用一种迭代的方法计算网页级别,也就是先给出每一个网页的初始值,然后利用上面的公式,循环进行有限次数的运算得到近似的网页级别。根据Lawrence Page等的论文,实际中要迭代100次才能得到整个互联网中的一个满意的网页级别值。
在迭代的过程中,每个网页的网页级别的和就是收敛于整个网格的页面数。所以,每个页面的平均级别是1,实际上的值在d和(dN+(1-d))之间。
举个例子:

设阻尼系数d=0.5,页面链接如下图所示:
PR(A)=0.5+0.5PR(C)
PR(B)=0.5+0.5(PR(A)/2)
PR(C)=0.5+0.5(PR(A)/2+PR(B))
由此可得出PR(A),PR(B),PR(C)的概率,再以此为基础迭代。其中PR(A)+PR(B)+PR(C)=3。
PageRank除了应用于搜索结果的排序以外,还可以用于估算网络流量,向后链接的预测器,为用户导航等。
缺点:
PageRank对于链出的权值贡献都是平均的,也就是不考虑不同链接的重要性。但是web的链接却具有以下特征:
1. 一些链接是导航或者广告,他们是不具有权威性的;
2. 基于商业或者竞争因素考虑,在同一个竞争领域内的web网页,一般是不会有链接指向其业内的权威网页的;
3. 权威网页也不会有明显的标识,例如Google不会明确标注Web搜索引擎之类的。
由此可见,平均的分布权值不符合链接的实际情况。
Hits(HyperlinkInduced Topic Search)算法应这种需求产生了…
Hits中引入了另一种网页,成为Hub(中心,good source of link)网页。Hub网页时提供指向Authority(权威)网页链接集合的网页。也许Hub本身并不是很重要,但是他提供了一种指向某个主题最为重要的站点集合。一般来说,好的hub指向许多好的authority网页,而好的authority网页是有许多好的hub指向的网页B。这种hub与authority之间的相互加强的关系,可以用于authority的发现和web结构和资源的自动发现,这是authority/hub方法的基本思想。
算法:
1. 查询q返回若干的网页,从中取n个网页作为根集S,其中S满足:
1) S中网页数量相对较小
2) S中网页大多数是与查询q相关的网页
3) S中包含较多的authority网页
2. 向S中加入被S引用的网页和引用S的网页构成一个更大的集合T
3. T中的hub网页为顶点集V1,authority为顶点集V2,V1到V2的网页的超链接为边E,由此构成一个二分有向图SG=(V1,V2,E)。
h(V):网页v的hub值
a(u):网页的authority值
设初始h(v)=a(u)=1,
对u进行I操作,对v进行O操作,然后规范化。
如此不断的重复计算I,O,直到h(V),a(u)收敛。
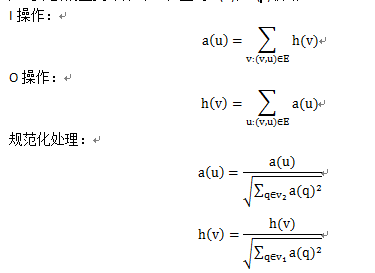
I操作反映了若一个网页有很多好的hub指向,则其权威值会增加。
O操作反映了若一个网页指向许多好的authority网页,则其hub值会增加。
HITS算法也有缺陷,这主要是因为HITS是纯粹的基于链接分析的算法,而没有结合文本内容,所以后续也是有很多基于HITS算法的改进算法。
本文如有错误,欢迎指出,谢谢~~















 3680
3680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









