







tensorflow多GPU并行计算
TensorFlow可以可以利用GPU加速深度学习模型的训练过程,在这里介绍一下利用多个GPU或者机器时,TensorFlow是如何进行多GPU并行计算的。
首先,TensorFlow并行计算分为:模型并行,数据并行。模型并行是指根据不同模型设计不同的并行方式,模型不同计算节点放在不同GPU或者机器上进行计算。数据并行是比较通用简便的实现大规模并行方式,同时使用多个硬件资源计算不同batch数据梯度,汇总梯度进行全局参数更新。
在这里我们主要介绍数据并行的多GPU并行方法。数据并行,多块GPU同时训练多个batch数据,运行在每块GPU上的模型基于同一神经网络,网络结构一样,共享模型参数。数据并行也分为两个部分,同步数据并行和异步数据并行。
在每一轮迭代中,前向传播算法会根据当前参数的取值,计算出在一小部分训练数据上的预测值,然后反向传播算法,根据loss function计算参数的梯度并且更新参数。而不同的数据并行模式的区别在于参数的更新方式不同。
1. 数据异步并行
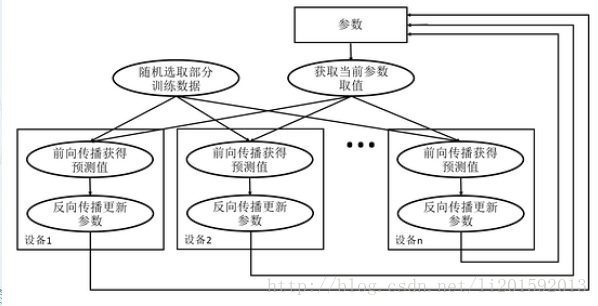
图一:数据异步并行模式流程图
从图一可以看出,在每一轮迭代时候,不同的设备会读取参数最新的取值。但是因为不同的设备,读取参数取值的时间不一样,得到的值也有可能不一样。
也就是说数据异步并行模式根据当前参数的取值和随机获取的一小部分数据数据在不同设备上各自运行,不等待所有GPU完成一次训练,哪个GPU完成训练,立即将梯度更新到共享模型参数。
2. 数据同步并行
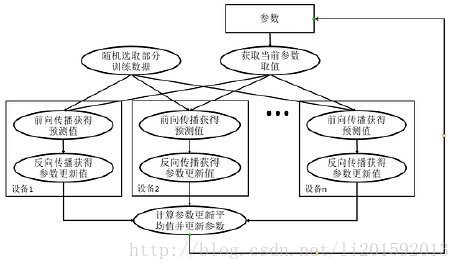
图二:数据同步并行模式流程图
与数据异步并行模式不同的是数据同步并行模式在所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值,最后在根据平均值对参数进行更新。
3. 比较
同步数据并行,所有GPU计算完batch数据梯度,统计将多个梯度合在一起,更新共享模型参数,类似使用较大batch。GPU型号、速度一致时,效率最高。
异步数据并行,不等待所有GPU完成一次训练,哪个GPU完成训练,立即将梯度更新到共享模型参数。
同步数据并行比异步收敛速度更快,模型精度更高。
4. 代码实例
TensorFlow多GPU并行计算实例—MNIST














 2463
2463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









