







tensorFlow中主要包括了三种不同的并行策略,其分别是数据并行、模型并行、模型计算流水线并行,具体参考Tenssorflow白皮书,在接下来分别简单介绍三种并行策略的原理。
数据并行
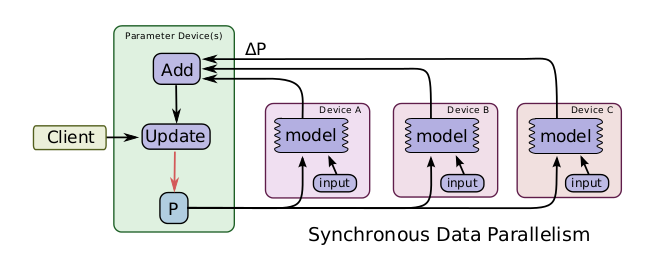
一个简单的加速训练的技术是并行地计算梯度,然后更新相应的参数。数据并行又可以根据其更新参数的方式分为同步数据并行和异步数据并行,同步的数据并行方式如图所示,tensorflow图有着很多的部分图模型计算副本,单一的客户端线程驱动整个训练图,来自不同的设备的数据需要进行同步更新。这种方式在实现时,主要的限制就是每一次更新都是同步的,其整体计算时间取决于性能最差的那个设备。
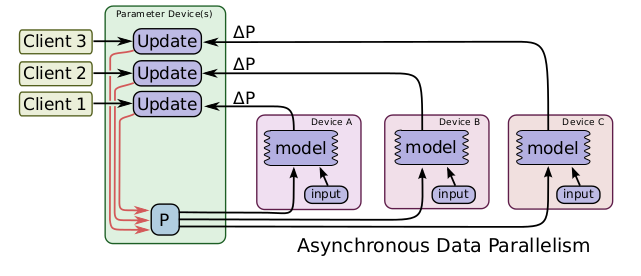
数据并行还有异步的实现方式,如图所示,与同步方式不同的是,在处理来自不同设备的数据更新时进行异步更新,不同设备之间互不影响,对于每一个图副本都有一个单独的客户端线程与其对应。在这样的实现方式下,即使有部分设备性能特别差甚至中途退出训练,对训练结果和训练效率都不会造成太大影响。但是由于设备间互不影响,所以在更新参数时可能其他设备已经更好的更新过了,所以会造成参数的抖动,但是整体的趋势是向着最好的结果进行的。所以说这种方式更适用于数据量大,更新次数多的情况。
模型并行
一个模型并行训练的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2928
2928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









