







计算公式:

并通过下面代码对Mahout in Action的结果进行了验证:
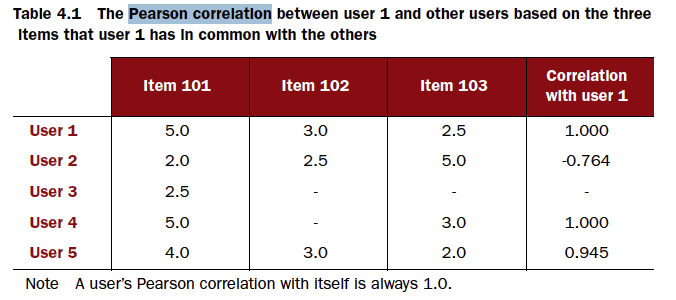
代码如下:
`
package com.example.mahout;
public class TestColl {
public static void main(String[] args) {
// TODO Auto-generated method stub
//int a[]={68,71,62,75,58,60,67,68,71,69,68,67,63,62,60,63,65,67,63,61};
//double b[] ={4.1,4.6,3.8,4.4,3.2,3.1,3.8,4.1,4.3,3.7,3.5,3.2,3.7,3.3,3.4,4.0,4.1,3.8,3.4,3.6};
double a[]={5,3.0,2.5};
double b[]={4,3,2.0};
int i,j;
double sum_a=0,sum_b=0,sum_XY=0,sum_X=0,sum_Y=0,sum_X2=0,sum_Y2=0;
double mean_a,var_a,mean_b,var_b;
for(i=0;i<a.length;i++){
sum_a+=a[i];
sum_b+=b[i];
sum_XY+=a[i]*b[i];
sum_X2+=a[i]*a[i];
sum_Y2+=b[i]*b[i];
}
mean_a = sum_a/a.length;
mean_b = sum_b/b.length;
System.out.println("sum_a:"+sum_a);
System.out.println("sum_b:"+sum_b);
System.out.println("mean_a:"+mean_a);
System.out.println("mean_b:"+mean_b);
sum_X=sum_a;
sum_Y = sum_b;
sum_a=sum_b=0;
for(i=0;i<a.length;i++){
sum_a+=(a[i]-mean_a)*(a[i]-mean_a);
sum_b+=(b[i]-mean_b)*(b[i]-mean_b);
}
var_a=sum_a/(a.length-1);
var_b=sum_b/(a.length-1);
System.out.println("var_a:"+var_a);
System.out.println("var_b:"+var_b);
System.out.println("sum_XY:"+sum_XY);
System.out.println("sum_X:"+sum_X);
System.out.println("sum_X2:"+sum_X2);
System.out.println("sum_Y2:"+sum_Y2);
double r_up = a.length*sum_XY-sum_X*sum_Y;
double r_down = Math.sqrt((a.length*sum_X2-sum_X*sum_X)*(a.length*sum_Y2-sum_Y*sum_Y));
double r=r_up/r_down;
System.out.println("r_up:"+r_up);
System.out.println("r_down:"+r_down);
System.out.println("r:"+r);
}
}
`















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









