







 本文介绍了深度学习中常见的问题及其解决方案,包括过拟合、梯度消失现象及如何提升模型在测试数据集上的效果。建议使用ReLU激活函数避免梯度消失,探讨了maxout激活函数的原理与应用,同时提出早停、正则化(L1和L2)以及dropout策略来增强模型的泛化能力。
本文介绍了深度学习中常见的问题及其解决方案,包括过拟合、梯度消失现象及如何提升模型在测试数据集上的效果。建议使用ReLU激活函数避免梯度消失,探讨了maxout激活函数的原理与应用,同时提出早停、正则化(L1和L2)以及dropout策略来增强模型的泛化能力。
1、模型在训练数据上表现不好,why?
(1)过拟合
(2)激活函数
(3)学习率
2、梯度消失?
盲目增加网络层数很容易导致发生梯度消失现象,尤其是使用sigmoid作为激活函数的时候。sigmoid函数的特点使得权重很大的改变对输出产生很小的影响,当层数很多时这种影响甚至可以忽略不计。在权重更新环节,靠近输出端的权重梯度较大,靠近输入端的权重梯度很小,这使得后端权重更新的很快、很快就收敛,而前端却更新的很少,好像梯度在向后传播的过程中消失了一样,这就是梯度消失现象。
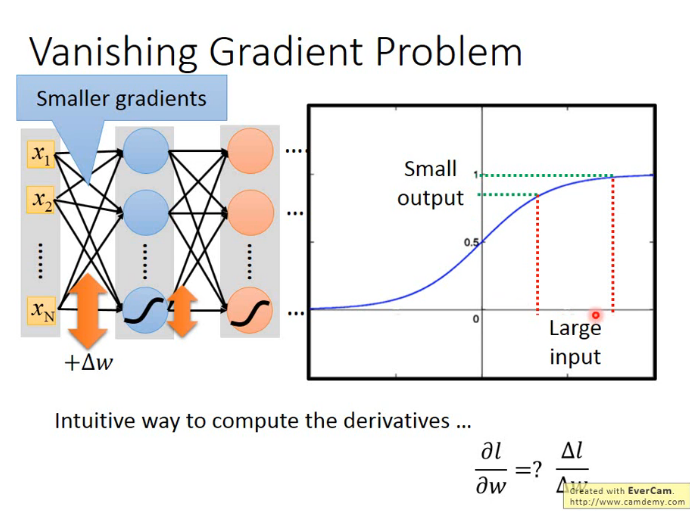
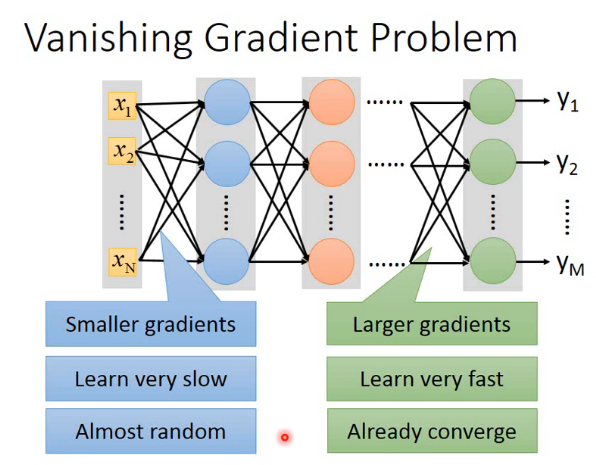
避免梯度消失发生的方法之一是使用ReLU作为激活函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









