






图像分类是根据图像的原始信息将不同类别图像区分开来,是计算机视觉中重要的基本问题,也是图像检测、图像分割、物体跟踪、行为分析等其他高层视觉任务的基础。图像分类在很多领域有广泛应用,包括安防领域的人脸识别和智能视频分析,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
在CNN出现之前,图像分类算法依赖于复杂的特征工程。常用的特征提取方法包括SIFT(Scale-Invariant Feature Transform,尺度不变特征转换)、HOG(Histogram of Oriented Gradient,方向梯度直方图)、LBP(Local Bianray Pattern,局部二值模式)等,常用的分类算法为SVM。
1 基于CNN的图像分类算法
人们尝试直接把原始图像作为输入,通过深度学习算法直接进行图像分类,从而绕过复杂的特征工程。下面介绍几个重要技术点。
1.1 局部连接
常见的深度学习算法都是全连接形式,所谓全连接,就是第n-1层的任意一个节点,都和第n层所有节点有连接,同时,临近输入层的隐藏层的任意节点与输入层的全部节点都有连接,以一个大小为1000×1000的灰度图像为例,输入层节点数量为000×1000=1000000,隐藏层节点数量也为1000×1000=1000000,仅输入层与隐藏层的连接就需要1000000×1000000=1012
,几乎是个天文数字,如此巨大的计算量阻碍了深度学习在图像分类方向的应用。
事情的转机来自于生物学的一个发现。人们在研究猫的视觉神经细胞时发现,一个视觉神经元只负责处理视觉图像的一小块,这一小块称为感受野(Receptive Field),类比在图像分类领域,识别一个图像是何种物体时,一个点与距离近的点之间的关联非常紧密,但是和距离远的点之间关系就不大了,甚至足够远的时候就可以忽略不计具体到深度学习算法上,隐藏层与输入层之间,隐藏层的一个节点只处理一部分输入层结点的数据,形成局部连接。还是接上面的例子,假设每个隐藏层的节点只处理10×10大小的数据,也就是说每个隐藏层的节点只与输入层的100个节点连接,这样在隐藏层节点数量和输入层节点数量不变的情况下,输入层与隐藏层的连接需要1000000×100=108,是全连接的万分之一。虽然计算量下降不少,但是依然十分巨大。局部连接不会减少隐藏层接
具体到深度学习算法上,隐藏层与输入层之间,隐藏层的一个节点只处理一部分输入层结点的数据,形成局部连接。还是接上面的例子,假设每个隐藏层的节点只处理10×10大小的数据,也就是说每个隐藏层的节点只与输入层的100个节点连接,这样在隐藏层节点数量和输入层节点数量不变的情况下,输入层与隐藏层的连接需要1000000×100=108
,是全连接的万分之一。虽然计算量下降不少,但是依然十分巨大。局部连接不会减少隐藏层的节点数量,减少的是隐藏层和输入层之间的连接数。
1.2 参数共享
本质上隐藏层的一个节点与输入层一个节点的连接,对应的就是一个连接参数,大量的连接也就意味着大量的参数需要计算,仅依靠局部连接技术是无法进一步减少计算量的,于是人们又提出了参数共享方法。所谓的参数共享是基于这样一个假设:一部分图像的统计特性与完整图像的特性相同。回到上面的例子,每个隐藏层的节点只与输入层的100个节点连接,这样每个隐藏层节点就具有100个参数,全部隐藏层就具有1000000×100=108个参数,使用参数共享后,每个隐藏层的节点都具有完全相同的参数,全部隐藏层就只有100个参数需要计算了,这大大减少了计算量,而且即使处理更大的图像,只要单一隐藏层节点与输入层连接的个数不变,全部隐藏层的参数个数也不变。这种共享参数的机制,可以理解为针对图像的卷积操作。假设如图2-5所示,具有一个4×4大小的图像和一个2×2大小的卷积核。
大小为2×2的卷积核对原始图像第1个2×2的图像块进行卷积操作,得到卷积结果为2.大小为2×2的卷积核对原始图像第1个2×2的图像块进行卷积操作,得到卷积结果为2。
可见卷积处理后图像的大小与卷积核的大小无关,仅与步长有关,对应的隐藏层的节点个数也仅与步长有关。另外需要说明的是,卷积核处理图像边际时会出现数据缺失,这时候需要将图像补全,常见的补全方式有两种,果
可见卷积处理后图像的大小与卷积核的大小无关,仅与步长有关,对应的隐藏层的节点个数也仅与步长有关。另外需要说明的是,卷积核处理图像边际时会出现数据缺失,这时候需要将图像补全,常见的补全方式有两种,same模式和valid模式,same模式会使用0数据补全,而且保持生成图像与原始图像大小一致。
如果使用same模式,大小为2×2的卷积核依次对原始图像进行卷积操作,移动的步长为1,最终获得一个4×4的新图像。这里需要再次强调,当步长为1时,无论卷积核大小如何,处理前后图像大小不变;只有当步长大于1时,处理后的图像才会变小。
1.3 池化
通过局部连接和参数共享后,我们针对1000×1000的图像,使用卷积核大小为10×10,卷积步长为1,处理后得到的隐藏层节点个数为1000×1000=106
,计算量还是太大。为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值(或最大值)。这种聚合的操作就叫做池化。常见的池化大小为2×2、3×3等,假设隐藏层节点个数为4×4,使用2×2大小池化,取最大值,隐藏层节点个数为1000×1000的神经网络,经过2×2池化后,得到的隐藏层节点个数为500×500=25×104.
1.4 典型的CNN结构及实现
典型的CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数。
·卷积层,执行卷积操作提取底层到高层的特征,发掘图片局部关联性质和空间不变性质。
·池化层,通过抽取卷积输出特征图中局部区块的最大值或者均值,执行降采样操作。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
·全连接层,输入层到隐藏层的神经元是全部连接的。
·非线性变化,卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的是ReLu激活函数。
·Dropout,在模型训练阶段随机让一些隐层节点不工作,提高神经网络的泛化能力,一定程度上可防止过拟合。
这一点就好比人眼在识别图的时候,适当遮住一部分图像并不会影响识别结果一样。相对于浅层学习的SVM、KNN和朴素贝叶斯等,深度学习由于参数众多,更容易出现过拟合的现象,所以一般都需要使用Dropout的机制。
以处理经典的MNIST数据集为例,MNIST数据集作为一个简单的计算机视觉数据集,包含一系列如图2-12所示的手写数字图片和对应的标签。图片是28×28的像素矩阵,标签则对应着0~9的10个数字。每张图片都经过了大小归一化和居中处理。
处理MNIST的CNN结构,这是一个TensorFlow的结构输出图。 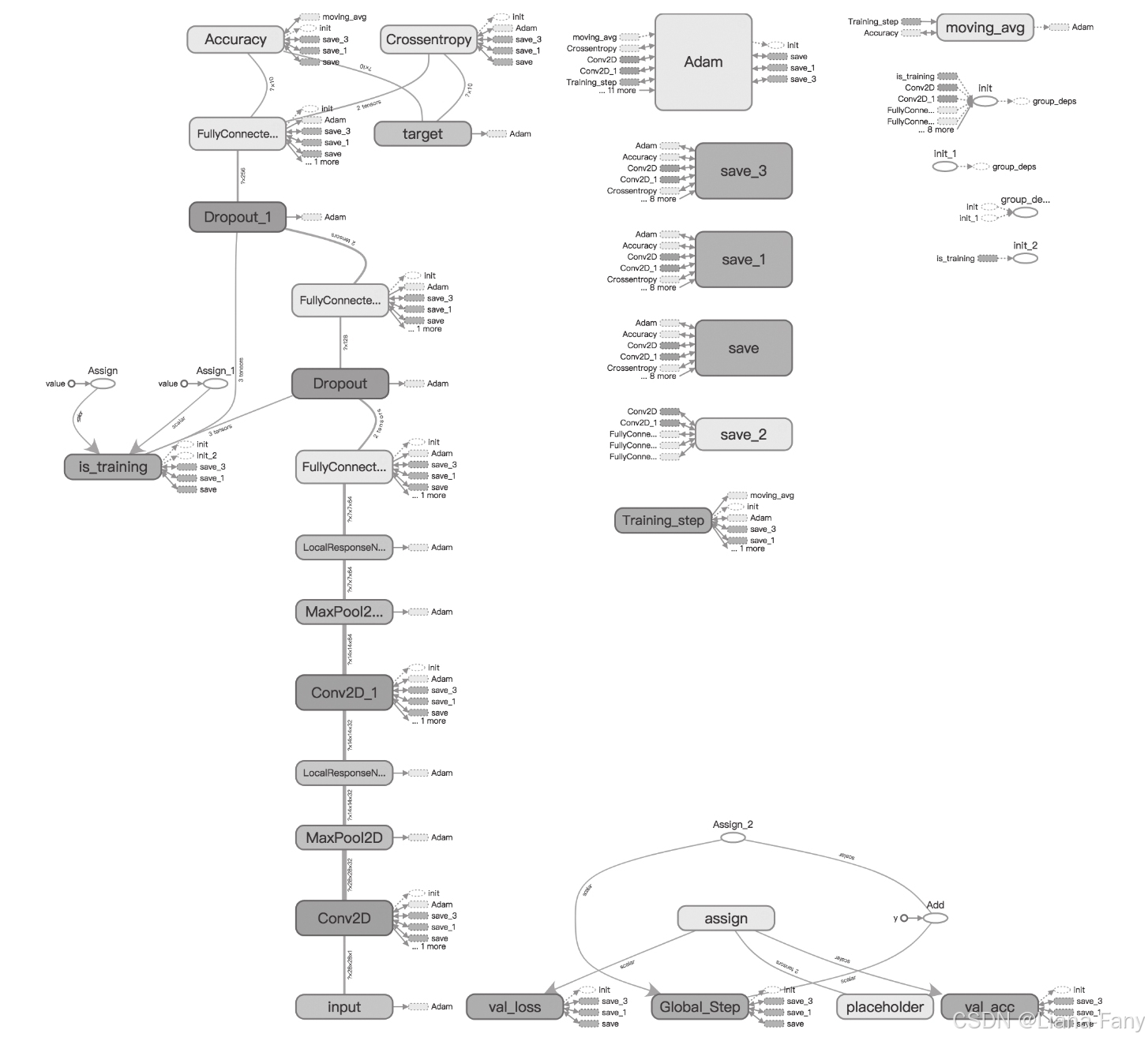
TensorFlow中将处理的数据统一抽象为张量,即所谓的Tensor,原始大小为28×28的图像可以抽象成大小为28×28张量,张量依次经过:
1)卷积核大小为3×3数量为32的卷积处理。
2)池化大小为2×2的池化处理。
3)卷积核大小为3×3数量为64的卷积处理。
4)池化大小为2×2的池化处理以及最后的全连接处理。
5)最后得到长度为10的一维张量,对应正好是图像识别后的结果,即数字0~9。
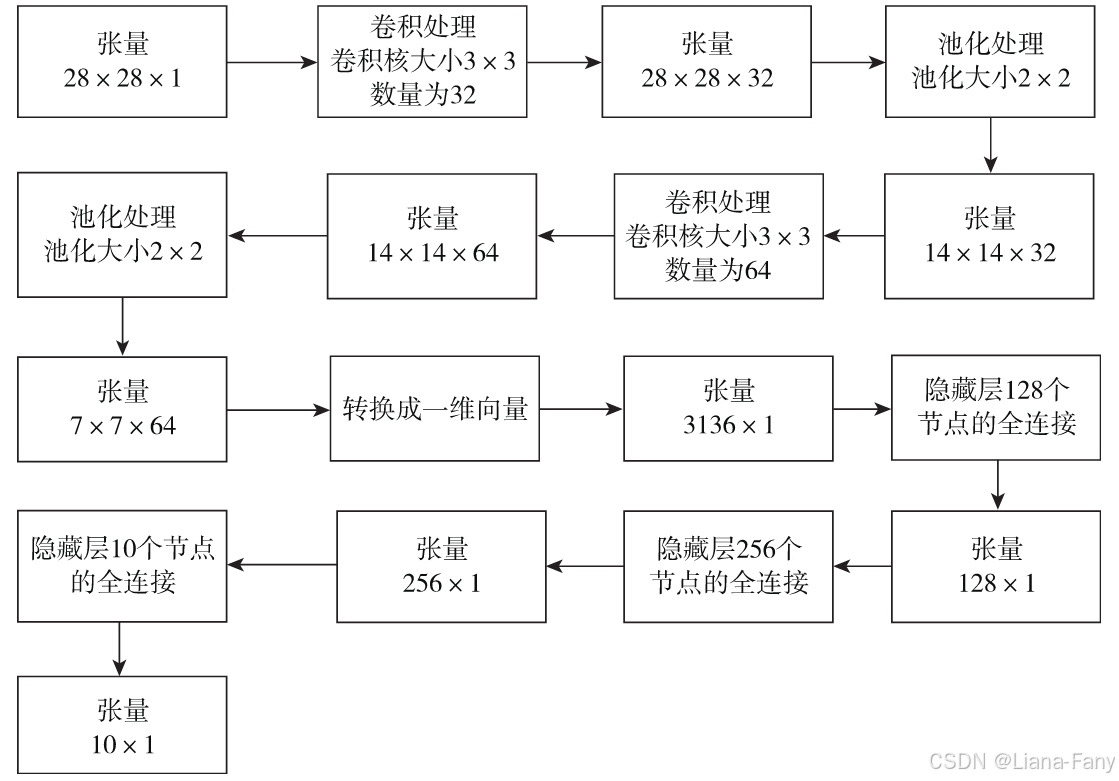
基于TensorFlow一步一步使用代码实现上述过程。
每张图片大小为28×28,可以当做一个28×28的矩阵,CNN输入层的大小为28×28,由于图像是灰度图像,每个像素取值为0或者1,定义输入为[None,28,28,1],这样就获得了大小为28×28的张量:
network = input_data(shape=[None, 28, 28, 1], name='input')
使用卷积处理,卷积核大小为3×3,卷积核数量为32,可以理解为通过3×3大小的卷积操作,提取32种特征,处理后的张量大小为28×28×32,激活函数使用relu:
network = conv_2d(network, 32, 3, activation='relu', regularizer="L2")
使用池化处理,池化大小为2×2,处理后的张量大小为14×14×32:
network = max_pool_2d(network, 2)
使用卷积处理,卷积核大小为3×3,卷积核数量为64,可以理解为通过3×3大小的卷积操作,提取64种特征,处理后的张量大小为14×14×64:
network = conv_2d(network, 64, 3, activation='relu', regularizer="L2")
使用池化处理,池化大小为2×2,处理后的张量大小为7×7×64:
network = max_pool_2d(network, 2)
标准化处理张量,将大小为7×7×64的张量转化为长度为3136的一维张量,并与节点数为128的隐藏层进行全连接,为了避免过拟合,使用Dropout让部分节点临时失效。其中函数local_response_normalization即localresponse normalization最早是由Krizhevsky和Hinton在关于ImageNet的论文里面使用的一种数据标准化方法:
network = local_response_normalization(network)
network = fully_connected(network, 128, activation='tanh')
network = dropout(network, 0.8)
再与节点数为256的隐藏层进行全连接,为了避免过拟合,继续使用Dropout让部分节点临时失效:
network = fully_connected(network, 256, activation='tanh')
network = dropout(network, 0.8)
最后再与节点数为10的输出层进行全连接,获得长度为10的一维张量,至此我们使用CNN,完成了大小为28×28的张量到大小为1×10的张量的训练转化:
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='adam', learning_rate=0.01, loss='categorical_crossentropy', name='target')
值得一提的是,这里使用了多种激活函数,常见的激活函数有:sigmoid函数、tanh函数、ReLU函数。
1.5 AlexNet的结构及实现
AlexNet是在2012年发表的一个经典之作,并在当年取得了ImageNet最好成绩,其官方提供的数据模型,准确率达到57.1%,top1~5达到80.2%。与传统的机器学习分类算法相比,这个结果已经相当出色。
AlexNet一共有8层组成,其中3个卷积层5个全连接层,以处理经典的Oxford’s17Category Flower数据集为例,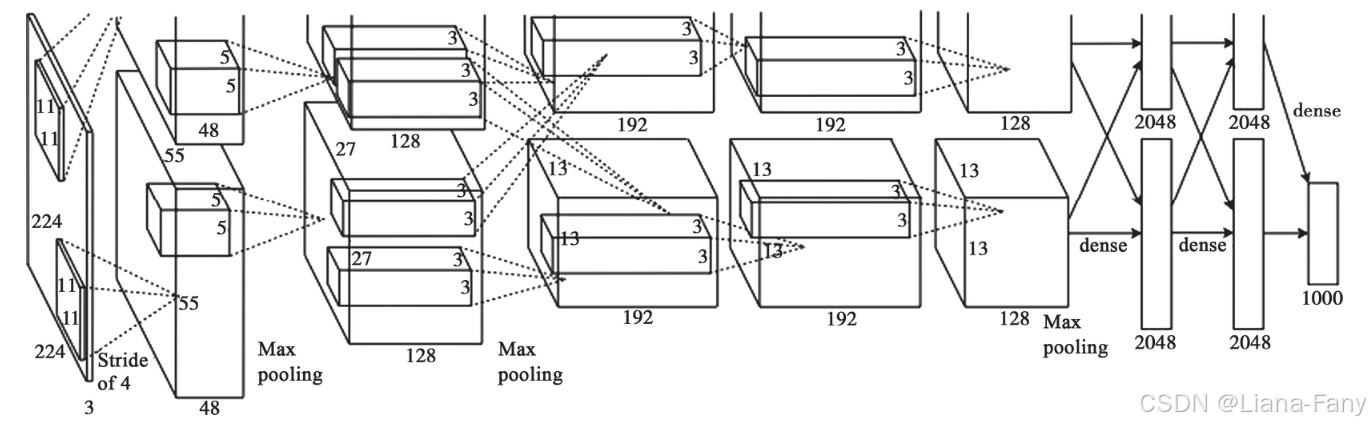
。Oxford’s 17Category Flower数据集是一个不同种类鲜花的图像数据,包含17个不同种类的鲜花,每类80张该类鲜花的图片,这些鲜花种类是英国地区常见的。
每张图片大小为227×224,通道数为3,所以对应的张量大小为227×227×3。部分文献记录图片大小为224,这不影响本文的描述与代码实现。
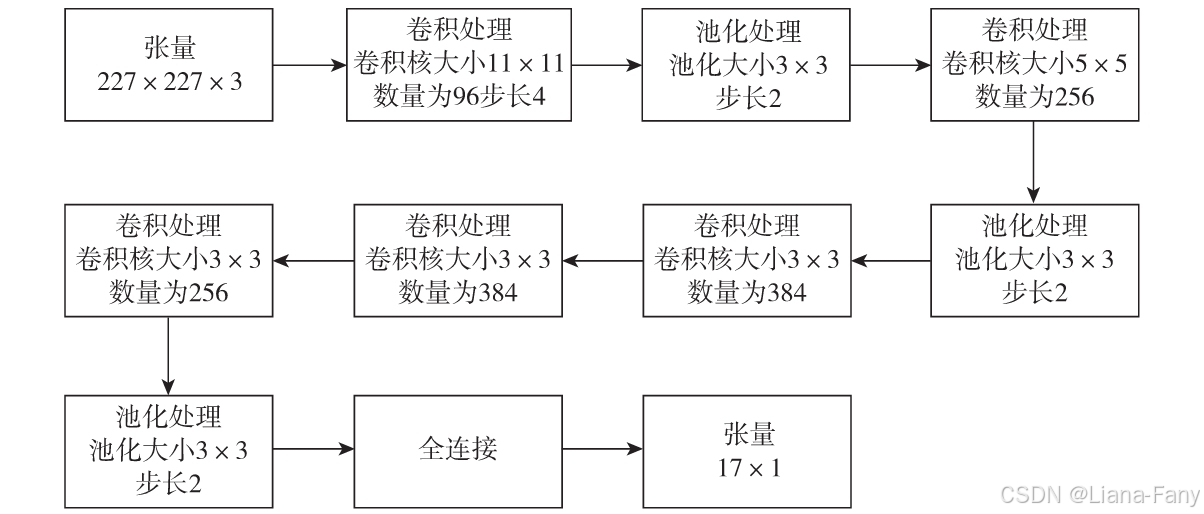
处理Oxford’s 17Category Flower数据集的AlexNet结构,这是一个TensorFlow的结构输出图。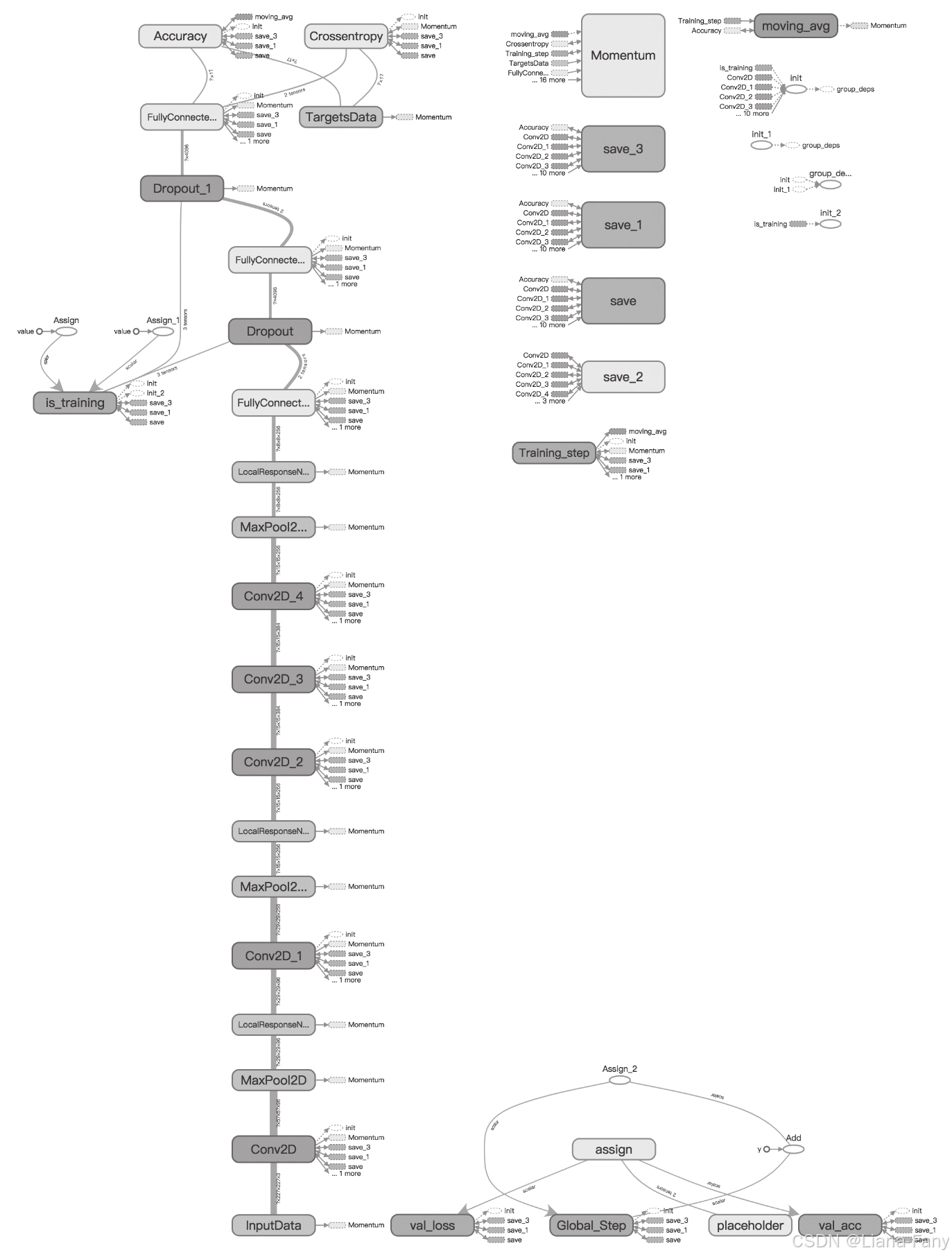
简化后的处理流程,大小为227×227×3张量经过如下处理:
1)卷积核大小为11×11数量为96的卷积处理。
2)池化大小为3×3的池化处理。
3)卷积核大小为5×5数量为256的卷积处理。
4)池化大小为3×3的池化处理。
5)卷积核大小为3×3数量为384的卷积处理。
6)卷积核大小为3×3数量为384的卷积处理。
7)卷积核大小为3×3数量为256的卷积处理。
8)池化大小为3×3的池化处理以及最后的全连接处理。
9)最后得到长度为17的一维张量,对应正好是图像识别后的结果,即对应到17种花卉中的某一种。
基于TensorFlow一步一步使用代码实现上述过程。
每张图片大小为227×227可以当做一个227×227的矩阵,CNN输入层的大小为227×227,由于图像通道数为3,定义输入为[None,227,227,3],这样我们就获得了大小为227×227×3的张量:
network = input_data(shape=[None, 227, 227, 3])
使用卷积处理,卷积核大小为11×11,,卷积核数量为96,步长为4,可构
下面我们基于TensorFlow一步一步使用代码实现上述过程。
每张图片大小为227×227可以当做一个227×227的矩阵,CNN输入层的大小为227×227,由于图像通道数为3,定义输入为[None,227,227,3],这样我们就获得了大小为227×227×3的张量:
network = input_data(shape=[None, 227, 227, 3])
使用卷积处理,卷积核大小为11×11,卷积核数量为96,步长为4,可以理解为通过11×11大小的卷积操作,提取96种特征,处理后的张量大小为56×56×3×96,激活函数使用relu:
network = conv_2d(network, 96, 11, strides=4, activation='relu')
使用池化处理,池化大小为3×3,步长为2:
network = max_pool_2d(network, 3, strides=2)
使用卷积处理,卷积核大小为5×5,卷积核数量为256:
network = conv_2d(network, 256, 5, activation='relu')
使用池化处理,池化大小为3×3,步长为2:
network = max_pool_2d(network, 3, strides=2)
使用卷积处理,卷积核大小为3×3,卷积核数量为384:
network = conv_2d(network, 384, 3, activation='relu')
使用卷积处理,卷积核大小为3×3,卷积核数量为384:
network = conv_2d(network, 384, 3, activation='relu')
使用卷积处理,卷积核大小为3×3,卷积核数量为256:
network = conv_2d(network, 256, 3, activation='relu')
使用池化处理,池化大小为3×3,步长为2:
network = max_pool_2d(network, 3, strides=2)
标准化处理张量,并与节点数为4096的隐藏层进行全连接,为了避免过拟合,使用Dropout让部分节点临时失效:
network = local_response_normalization(network)
network = fully_connected(network, 4096, activation='tanh')
network = dropout(network, 0.5)
network = fully_connected(network, 4096, activation='tanh')
network = dropout(network, 0.5)
最后再与节点数为17的隐藏层进行全连接,获得长度为17的一维张量,至此,我们使用AlexNet,完成了大小为227×227×3的张量到大小为1×17的张量的训练转化:
network = fully_connected(network, 17, activation='softmax')
network = regression(network, optimizer='adam', learning_rate=0.01, loss='categorical_crossentropy', name='target')
1.6 VGG的结构及实现
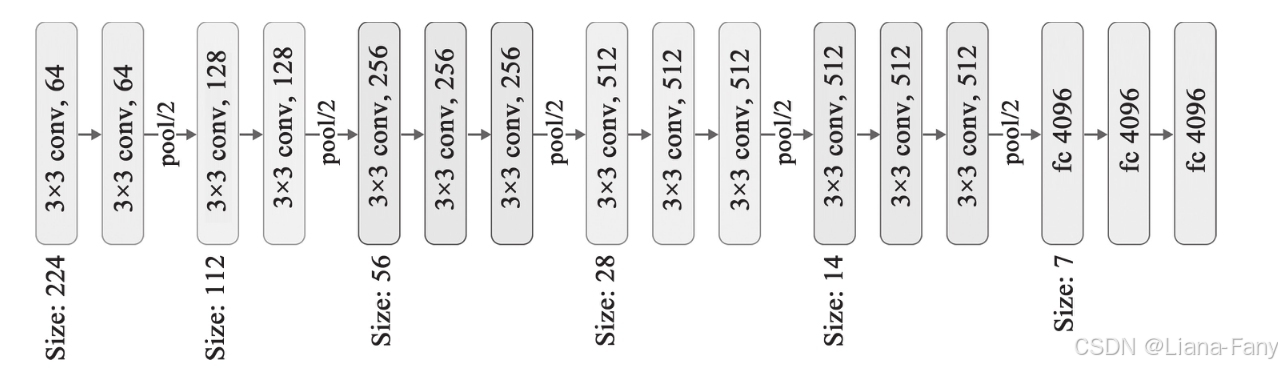
牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型,跟以往模型相比,该模型进一步加宽和加深了网络结构,它的核心是5组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3×3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型就是借鉴VGG模型的结构。
依然使用经典的Oxford’s 17Category Flower数据集为例。每张图片大小为227×224,通道数为3,所以对应的张量大小为227×227×3。部分文献记录图片大小为224,这不影响本文的描述与代码实现。
处理Oxford’s 17Category Flower数据集的VGG结构,这是一个TensorFlow的结构输出图。
简化后的处理流程如下所示,大小为227×227×3张量经过如下处理:
1)卷积核大小为3×3数量为64的卷积处理,激活函数为relu。
2)卷积核大小为3×3数量为64的卷积处理,激活函数为relu。
3)池化大小为2×2的池化处理。
4)卷积核大小为3×3数量为128的卷积处理,激活函数为relu。
5)卷积核大小为3×3数量为128的卷积处理,激活函数为relu。
6)池化大小为2×2的池化处理。
7)卷积核大小为3×3数量为256的卷积处理,激活函数为relu。
8)卷积核大小为3×3数量为256的卷积处理,激活函数为relu。
9)卷积核大小为3×3数量为256的卷积处理,激活函数为relu。
10)池化大小为2×2的池化处理。
11)卷积核大小为3×3数量为512的卷积处理,激活函数为relu。
12)卷积核大小为3×3数量为512的卷积处理,激活函数为relu。
13)卷积核大小为3×3数量为512的卷积处理,激活函数为relu。
14)池化大小为2×2的池化处理。
15)卷积核大小为3×3数量为512的卷积处理,激活函数为relu。
16)卷积核大小为3×3数量为512的卷积处理,激活函数为relu。
17)卷积核大小为3×3数量为512的卷积处理,激活函数为relu。
18)池化大小为2×2的池化处理以及与节点数为4096的隐藏层全连接。
19)最后得到长度为17的一维张量,对应正好是图像识别后的结果,即对应到17种花卉中的某一种。
基于TensorFlow一步一步使用代码实现上述过程。
每张图片大小为227×227可以当做一个227×227的矩阵,VGG输入层的大小为227×227,由于图像通道数为3,定义输入为[None,227,227,3],这样我们就获得了大小为227×227×3的张量:
network = input_data(shape=[None, 227, 227, 3])
使用连续两个卷积层处理,每层都是卷积核大小为3×3,卷积核数量为64,可以理解为通过3×3大小的卷积操作,提取64种特征,激活函数使用relu:
network = conv_2d(network, 64, 3, activation='relu')
network = conv_2d(network, 64, 3, activation='relu')
使用池化处理,池化大小为2×2,步长为2:
network = max_pool_2d(network, 2, strides=2)
使用连续两个卷积层处理,每层都是卷积核大小为3×3,卷积核数量为128,可以理解为通过3×3大小的卷积操作,提取128种特征,激活函数使用relu:
network = conv_2d(network, 128, 3, activation='relu')
network = conv_2d(network, 128, 3, activation='relu')
使用池化处理,池化大小为2×2,步长为2:
network = max_pool_2d(network, 2, strides=2)
使用连续3个卷积层处理,每层都是卷积核大小为3×3,卷积核数量为256,可以理解为通过3×3大小的卷积操作,提取256种特征,激活函数使用relu:
network = conv_2d(network, 256, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
使用池化处理,池化大小为2×2,步长为2:
network = max_pool_2d(network, 2, strides=2)
使用连续3个卷积层处理,每层都是卷积核大小为3×3,卷积核数量为512,可以理解为通过3×3大小的卷积操作,提取512种特征,激活函数使用relu:
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
使用池化处理,池化大小为2×2,步长为2:
network = max_pool_2d(network, 2, strides=2)
使用连续3个卷积层处理,每层都是卷积核大小为3×3,卷积核数量为512,可以理解为通过3×3大小的卷积操作,提取512种特征,激活函数使用relu:
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
使用池化处理,池化大小为2×2,步长为2:
network = max_pool_2d(network, 2, strides=2)
与节点数为4096的隐藏层进行全连接,为了避免过拟合,使用Dropout让部分节点临时失效:
network = local_response_normalization(network)
network = fully_connected(network, 4096, activation='tanh')
network = dropout(network, 0.5)
network = fully_connected(network, 4096, activation='tanh')
network = dropout(network, 0.5)
最后再与节点数为17的隐藏层进行全连接,获得长度为17的一维张量,至此我们使用VGG,完成了大小为227×227×3的张量到大小为1×17的张量的训练转化:
network = fully_connected(network, 17, activation='softmax')
network = regression(network, optimizer='rmsprop',
loss='categorical_crossentropy',
learning_rate=0.0001)
2 基于CNN的文本处理
CNN的诞生是为了解决图像处理领域计算量巨大而无法进行深度学习的问题,CNN通过卷积计算、池化等大大降低了计算量,同时识别效果满足需求。图像通常是二维数组,文字通常都是一维数据,是否可以通过某种转换后,也使用CNN对文字进行处理呢?答案是肯定的。
2.1 典型的CNN结构
在图像处理时CNN是如何处理二维数据的。CNN使用二维卷积函数处理小块图像,提炼高级特征进行进一步分析。典型的二维卷积函数处理图片的大小为3×3、4×4等。
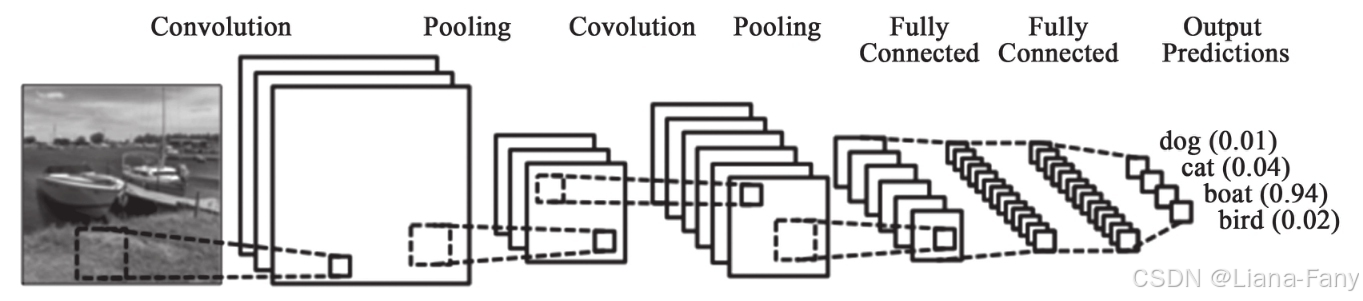
同样原理,使用一维的卷积函数处理文字片段,提炼高级特征进行进一步分析。典型的一维卷积函数处理文字片段的大小为3、4、5等。
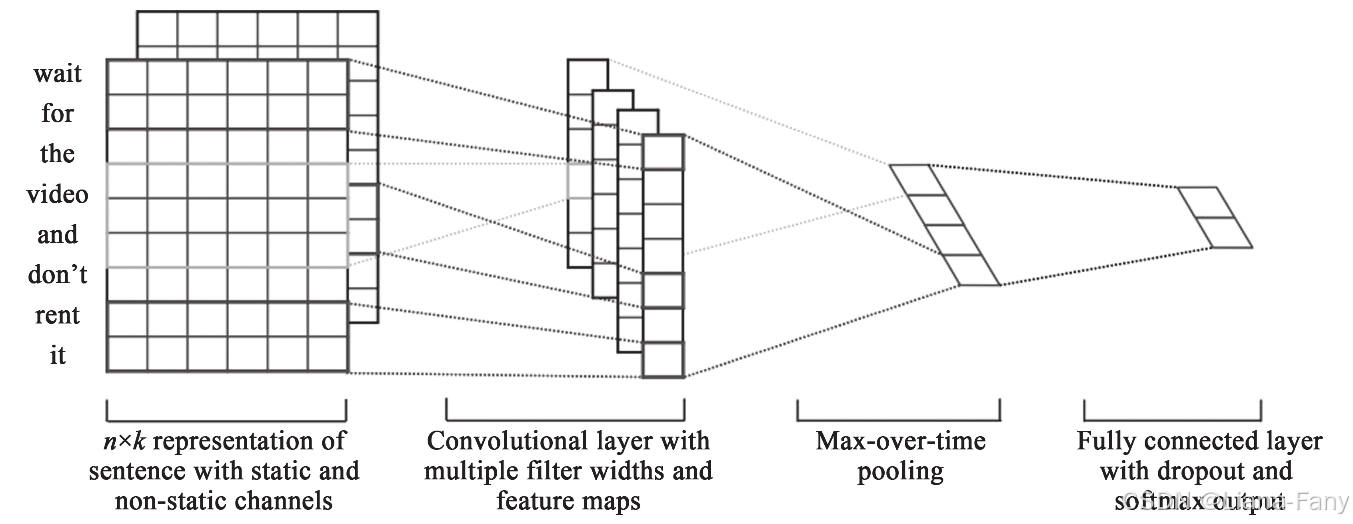
基于TensorFlow的处理文本的CNN的结构,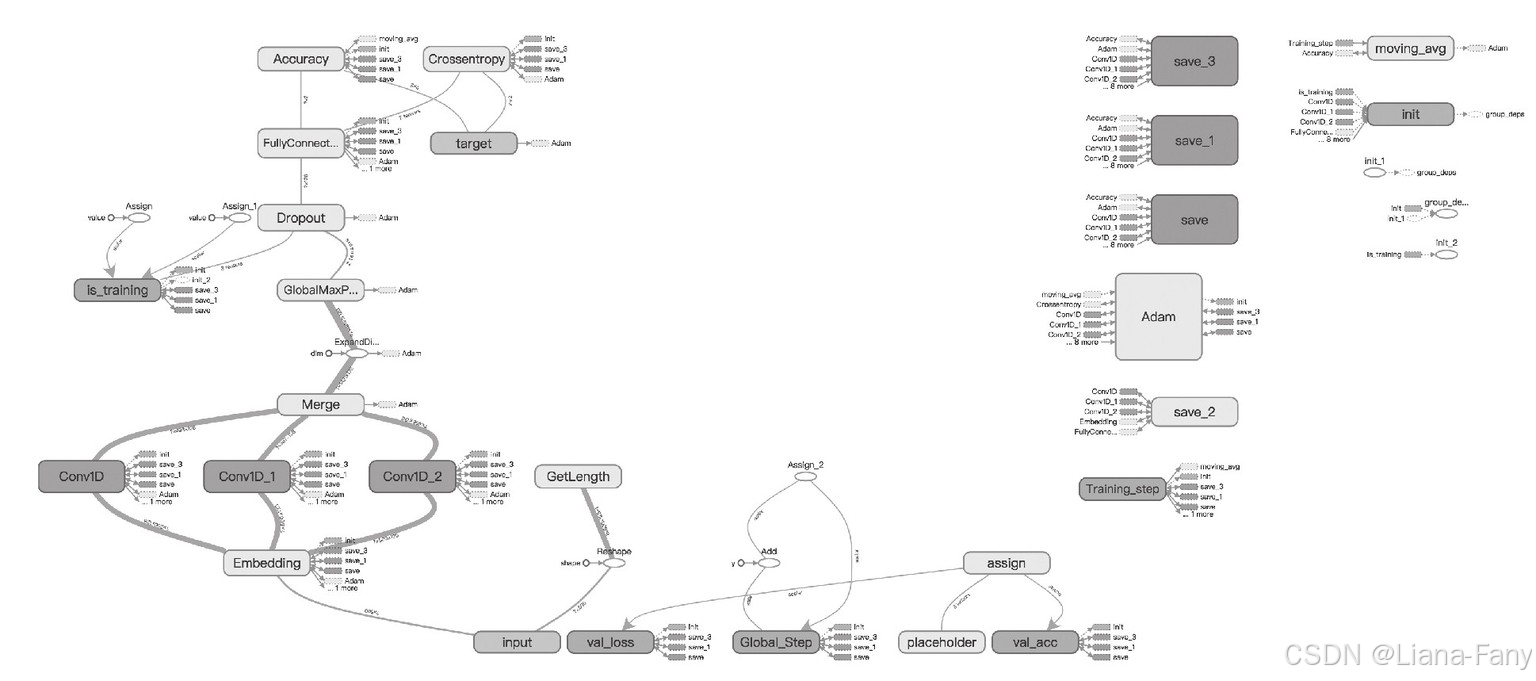
2.2 典型的CNN代码实现
定义CNN模型,其使用数量为128核,长度分别为3、4、5的3个一维卷积函数处理数据。
使用卷积处理,卷积核长度为3,卷积核数量为128,可以理解为通过长度为3的卷积操作,提取128种特征,激活函数使用relu:
branch1 = conv_1d(network, 128, 3, padding='valid', activation='relu', regularizer="L2")
使用卷积处理,卷积核长度为4,卷积核数量为128,可以理解为通过长度为4的卷积操作,提取128种特征,激活函数使用relu:
branch2 = conv_1d(network, 128, 4, padding='valid', activation='relu', regularizer="L2")
使用卷积处理,卷积核长度为5,卷积核数量为128,可以理解为通过长度为5的卷积操作,提取128种特征,激活函数使用relu:
branch3 = conv_1d(network, 128, 5, padding='valid', activation='relu', regularizer="L2")
合并以上3个卷积的处理后的结果,并使用一个全连接处理,输出结果为一个节点为2的输出层:
network = merge([branch1, branch2, branch3], mode='concat', axis=1)
network = tf.expand_dims(network, 2)
network = global_max_pool(network)
network = dropout(network, 0.8)
network = fully_connected(network, 2, activation='softmax')
network = regression(network, optimizer='adam', learning_rate=0.001
, loss='categorical_crossentropy', name='target')


















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











