









find_all()、find()、selector()方法
前言
上一文档讲了如何导入BeautifulSoup库,以及库的规范化输出html数据,本次文档将讲解find_all()、find()、selector()三个提取标签的方法。
一、find_all()和find()方法
知识点:
soup.find_all('div','item') 查找div标签,class='item',
soup.find_all('div',class='item') 查找div标签,class='item',
soup.find_all('div',attrs={'class':'item'}) 自定义字典参数获取特殊属性的tag
#使用find_all()方法和find()方法
import requests
from bs4 import BeautifulSoup #导入相关库函数
#网站地址
url='http://www.222biquge.com/modules/article/search.php?searchkey=%E5%89%91%E6%9D%A5'
#伪装headers
headers={
'Cookie': 'vc=1; Hm_lvt_e1880e6cb1c4b425fe63ef614765e9ec=1694943134; Hm_lpvt_e1880e6cb1c4b425fe63ef614765e9ec=1694943161',
'Host': 'www.222biquge.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36',
}
response=requests.get(url=url,headers=headers)
#print(response.text) #使用此句访问,查看自己是否访问到该网页
soup=BeautifulSoup(response.text,'html.parser')
#print(soup.prettify()) #soup显示的更加清楚,输出的内容会自动分行
tbodys=soup.find_all('td',attrs={"class":"odd"}) #根据键值对可以万能取值,td是标签,class是属性,odd是属性名
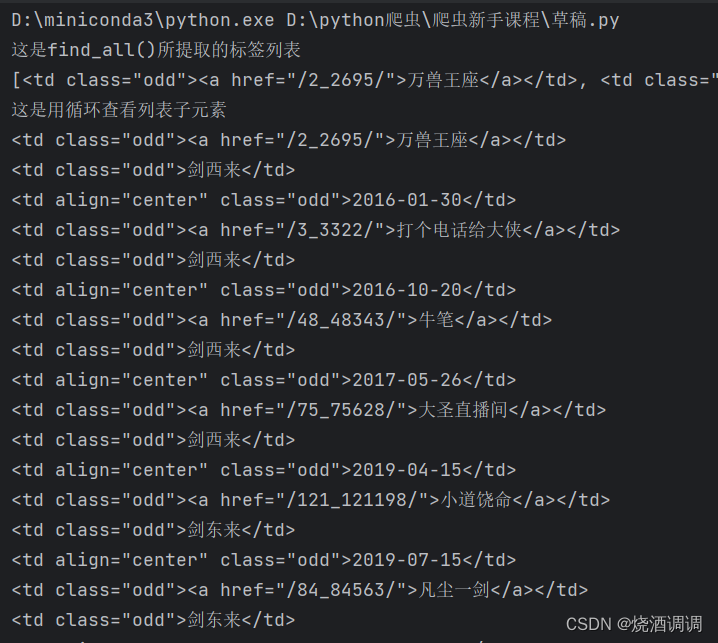
print('这是find_all()所提取的标签列表')
print(tbodys)
print('这是用循环查看列表子元素')
for tbody in tbodys:
print(tbody)
print('这是用find()方法,只能获取到第一个标签元素')
one_tbody=soup.find('td',attrs={"class":"odd"})
print(one_tbody)
![]()
二、selector()方法

selector()貌似已经使用不了了

三、附加内容——.text
print('这是用循环查看列表子元素')
for tbody in tbodys:
print(tbody.text)
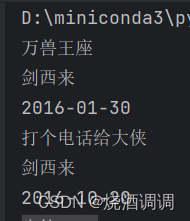
注意到t.text能获取到标签里面的文本数据,方便进行数据解析。
.text只能用于元素,不能用于列表
总结
find_all()提取所有对应的标签,find()提取一个标签数据,.text提取文本数据。
















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











