






摘要
自然梯度增强算法(Natural Gradient Boosting, NGBoost)是一种基于梯度增强的通用概率预测算法。典型的回归模型以协变量为条件返回点估计,但概率回归模型在结果空间上输出完整的概率分布,以协变量为条件。这允许预测不确定性估计——在医疗保健和天气预报等应用中至关重要。NGBoost通过将条件分布的参数作为多参数提升算法的目标,将梯度提升推广到概率回归。此外,我们展示了如何需要自然梯度来纠正我们的多参数增强方法的训练动态。NGBoost可以与任何基础学习器、任何具有连续参数的分布族和任何评分规则一起使用。NGBoost在匹配或超过现有概率预测方法的性能的同时,还提供了灵活性、可扩展性和可用性方面的额外优势。
3.2 广义自然梯度
我们采用标准梯度下降法,通过沿分数相对于每个点x的参数的负梯度下降来找到使评分规则最小化的参数。评分规则S在参数为θ和结果为y的参数化概率分布Pθ上的(普通)梯度表示为∇S(θ, y)。因此,在梯度方向上移动无限小的参数(相对于任何其他方向)将最大程度地增加评分规则。也就是说,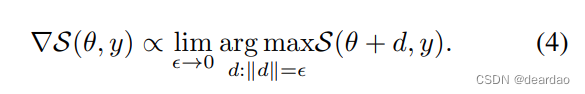
它的梯度对重新参数化不是不变的。考虑将Pθ重新参数化为Pz(θ)(y),因此当ψ = z(θ)时,对于所有事件A, Pθ(y∈A) = Pψ(y∈A)。如果梯度是相对于θ计算的,并且在那个方向上采取了一个无限小的步骤,比如从θ到θ + dθ,得到的分布将不同于梯度是相对于ψ计算的,并且从ψ到ψ + dψ采取了一个步骤。换句话说,Pθ+dθ(y∈A) 6= Pψ+dψ(y∈A)。因此,即使最小值不变,参数化的选择也会极大地影响训练动态。
问题是两个参数值之间的“距离”并不对应于这些参数所识别的分布之间的适当“距离”。这激发了自然梯度(表示∇~),它起源于信息几何(Amari, 1998)。
Divergences。每一个合适的评分规则都会产生一个散度,该散度可以作为分布空间中的局部距离度量。定义一个合适的评分规则满足Eqn 1的不等式。右侧比左侧多出的分数是由该评分规则引起的散度(david and Musio, 2014):
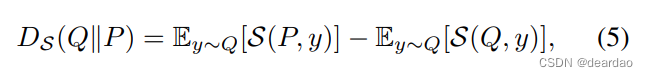
它必然是非负的,并且可以解释为从一个分布Q到另一个分布p的差异度量。MLE评分规则诱导Kullback-Leibler散度(KL散度,或DKL),而CRPS诱导l2散度(david, 2007)。
散度DKL和DL2与Q和P如何参数化无关。虽然散度通常是不对称的,但对于参数的微小变化,它们几乎是对称的,可以作为局部距离度量。当这样使用时,散度会产生一个统计流形,其中流形中的每个点对应于一个概率分布(david和Musio, 2014)。
自然梯度。广义自然梯度是黎曼空间中上升最陡的方向,对参数化不变,定义为: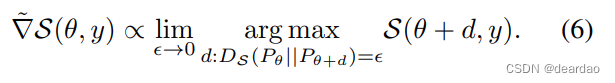
如果我们求解相应的优化问题,我们就得到了自然梯度的形式
其中Is (θ)是统计流形在θ处的黎曼度规,由评分规则s导出。虽然自然梯度最初是用DKL (Martens, 2014)导出的距离度量为统计流形定义的,但我们在这里提供了一种更一般的处理方法,适用于对应于某些适当评分规则的任何散度。
选取S = L(即MLE),求解上述优化问题,可得: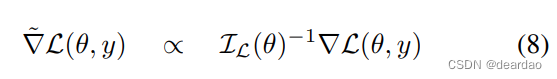
式中
I
L
(
θ
)
I_L(θ)
IL(θ)为观测值携带的Fisher Information,定义为: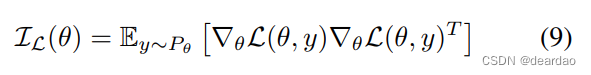
同理,选取S = C(即CRPS),求解上述优化问题,可得:
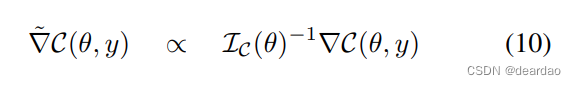
其中IC(θ)是使用DL2作为局部距离度量的统计流形的黎曼度量,由(Dawid, 2007)给出: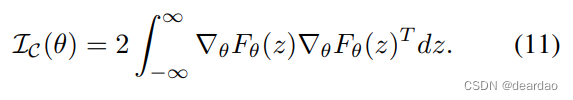
使用自然梯度来学习参数使优化问题对参数化不变性,从而导致更有效和稳定的学习动态(Amari, 1998)。图3为正态分布参数空间上L和C的梯度和自然梯度向量场,参数为µ(均值)和log σ(标准差的对数)。
关注微信公众号,获取更多资讯内容:


















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









