







Blogs:
Zhiyuan, WeChat, Zhihu, CSDN
简单总结
传统的回归和预测任务通常只提供确定性的点估计。为了估计响应变量的不确定性或分布信息,通常使用贝叶斯推理、模型集成或MC Dropout等方法。这些方法要么假设样本的后验分布遵循高斯过程,要么需要数千次前向传递来生成样本。我们提出了一种新的方法,称为DistPred,用于回归和预测任务,它克服了现有方法的局限性,同时保持简单和强大。具体来说,我们将测量预测分布与目标分布之间差异的适当评分规则转换为可微离散形式,并将其用作损失函数来端到端训练模型。这允许模型在单个前向传递中采样大量样本,以估计响应变量的潜在分布。我们已经将我们的方法与多个数据集上的几种现有方法进行了比较,并获得了最先进的性能。此外,我们的方法显著提高了计算效率。例如,与最先进的模型相比,DistPred的推理速度快了90x倍,训练速度提升230x倍(考虑数据处理与指标计算等步骤)。实验结果可以通过这个Github库复现。
论文题目:DistPred: A Distribution-Free Probabilistic Inference Method for Regression and Forecasting
论文作者:Daojun Liang, Haixia Zhang,Dongfeng Yuan
论文地址:https://arxiv.org/abs/2406.11397
代码地址:https://github.com/Anoise/DistPred
论文在线版本 — 论文地址 — Github代码地址
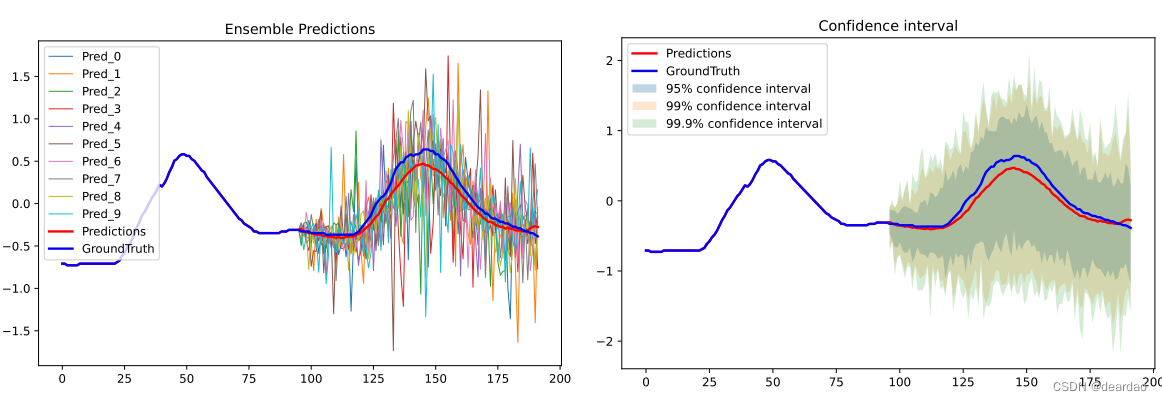
图 0:DistPred可在一次前向过程中给出N个预测,根据这N个预测可求得该点的分布。
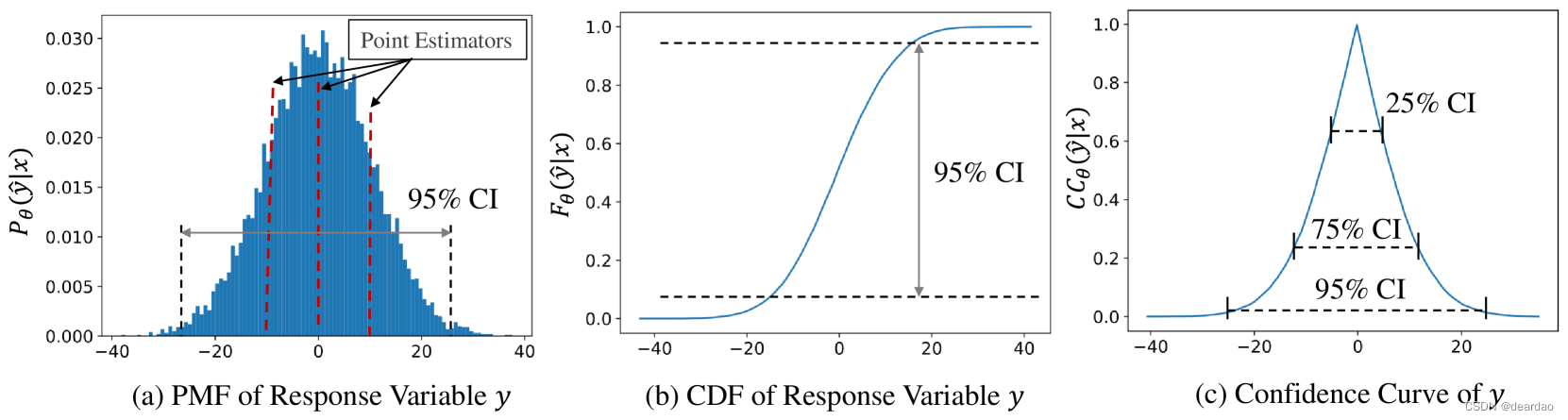
图1:DistPred可以在单个前向过程中给出预测变量的变量,给出响应变量的变量的 K K K预测值,表示为 y ^ \hat{y} y^,其中 y ^ \hat{y} y^表示的是一个最大似然样本。基于这个抽样,可以计算响应变量 y y y的质量分布的概率(PMD) P θ ( y ^ ∣ x ) P_{\theta}(\hat{y}|x) Pθ(y^∣x),累积分布函数(PDF) F θ ( y ^ ∣ x ) F_{\theta}(\hat{y}|x) Fθ(y^∣x),和信心曲线 C C θ ( y ^ ∣ x ) CC_{\theta}(\hat{y}|x) CCθ(y^∣x),从而产生 y y y全面统计量。例如,这包括任何期望水平上的置信区间(CI)以及p-value。
1 简介
在本文中,我们考虑了预测响应变量背后的潜在分布,因为它反映了所有水平的置信区间。例如,基于这个分布,我们可以计算任何级别的置信区间、覆盖率和不确定性量化。目前,预测响应变量的分布是一个挑战,因为在特定时刻,响应变量只能采取单一的确定性值。这个点可以看作是其潜在分布的最大似然样本,但它不能反映潜在分布的整体状态。
目前,在回归和预测任务中,用于解决分布预测和不确定性量化的主要方法是频率采样。这些方法包括通过干扰解释变量或模型来采样大量样本,以近似响应变量的潜在分布。例如,贝叶斯神经网络(bnn)通过假设其参数遵循高斯分布来模拟这种不确定性,从而捕获给定数据的模型的不确定性(Blundell et al., 2015)。同样,基于集成的方法也被提出,将多个具有随机输出的深度模型结合起来,以捕获预测的不确定性。MC Dropout (Gal和Ghahramani, 2016)表明,在每个测试过程中启用Dropout会产生类似于模型集成的结果。此外,还引入了基于GAN和扩散的条件密度估计和预测不确定性量化模型。这些模型利用产生或扩散过程中的噪声来获得不同的预测值,以估计响应变量的不确定性。
上述这些方法的共同特点是要求𝐾前向通过采样 K K K代表性样本。例如,基于贝叶斯框架的方法需要推断 K K K可学习的参数样本,以获得 K K K代表性样本;集成方法需要 K K K模型共同推断;MC Dropout需要 K K K向前通过随机Dropout激活;生成模型需要 K K K正向或扩散过程。然而,过多的向前传递会导致显著的计算开销和较慢的速度,对于具有高实时性要求的AI应用程序来说,这一缺点变得越来越明显。
为了解决这个问题,我们提出了一种新的方法,称为DistPred,它是一种用于回归和预测任务的无分布概率推理方法。DistPred是一种简单而强大的方法,可以估计单次正向传递中响应变量的分布。具体来说,我们考虑使用所有预测分位数来指定预测变量的潜在累积密度函数(CDF),并且我们表明,整个分位数的预测可以转化为计算响应变量和预测集合变量的最小期望值。在此基础上,我们将测量预测分布与目标分布之间差异的适当评分规则转换为可微离散形式,并将其用作损失函数来端到端训练模型。这允许模型在单个前向传递中采样大量样本,以估计响应变量的潜在分布。DistPred与其他方法是正交的,这使得它可以与其他方法相结合来增强估计性能。此外,我们还展示了DistPred可以提供对响应变量的全面统计见解,包括任何期望水平上的置信区间、p值和其他统计信息,如图1所示。实验结果表明,DistPred在精度和计算效率方面都优于现有方法。具体来说,DistPred的推理速度比最先进的模型快90倍,训练速度提升230x倍(考虑数据处理与指标计算等步骤)。
2 方法
假设数据集 D = { x i , y i } i = 1 N D=\{x_i,y_i\}_{i=1}^N D={
xi,yi}i=1N由 N N N样本标签对组成。如果下标 i i i不会在上下文中引起歧义,则将被省略。我们的目标是利用具有参数 θ \theta θ的机器学习模型 M M M来预测响应变量 y y y从 D D D的潜在分布 P ( y ) P(y) P(y),旨在获得全面的统计见解,例如获得置信区间(CI)和在任何期望水平上量化不确定性。
直接预测分布 P P P是不可行的,因为:
- 如果没有分布假设,我们就不能给出预测分布 P θ ( y ^ ) P_\theta(\hat{y}) Pθ(y^)的PDF或CDF的有效表示。
- 对于响应变量 y y y,我们只能得到一个奇异的确定性值,无法获得其分布信息来指导模型学习。
为了解决上述问题,我们考虑采用所有预测分位数 q ^ 1 , q ^ 2 , ⋯ \hat{q}_1, \hat{q}_2, \cdots q^1,q^2,⋯,在水平 α 1 , α 2 , ⋯ \alpha_1, \alpha_2, \cdots α1,α2,⋯上指定预测变量 y ^ \hat{y} y^的潜在CDF F θ ( y ^ ) F_\theta(\hat{y}) Fθ(y^)。这是因为如果我们知道随机变量的累积分布函数,我们可以通过设置 F ( y ) = q F(y) = q F(y)=q找到任何分位数。相反,如果我们有一个完整的分位数集,我们可以近似或重建随机变量的累积分布函数。如图2所示,分位数提供了分布的离散“快照”,而CDF是这些快照的连续、平滑版本,提供了从最小值到最大值的累积概率的完整描述。
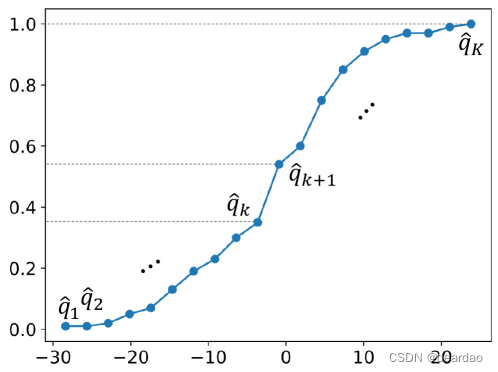
图2:CDF与所有预测分位数之间的关系。
接下来,我们将介绍前面概述的完整预测分位数作为响应变量CDF的适当近似值。全分位数预测可转化为计算响应变量和预测集合变量 Y ^ \hat{Y} Y^的最小期望值,其中 Y ^ = { Y ^ 1 , ⋯ , Y ^ K } \hat{Y} = \{\hat{Y} _1, \cdots, \hat{Y} _K \} Y^={ Y^1,⋯,Y^K}。在深入研究此分析之前,我们将首先介绍用于评估预测分布的适当性的评分规则。
2.1 使用适当的评分规则作为损失函数
评分规则通过根据预测分布和预测结果分配数值分数,为评估概率预测提供了一个简明的度量\citep{gneiting2007strictly, jordan2017evaluating}。具体地说,设 Ω \Omega Ω表示感兴趣的数量的可能值的集合,设 P \mathcal{P} P表示 Ω \Omega Ω上概率分布的凸类。评分规则是一个函数
S : Ω × P → R ∪ { ∞ } ( 1 ) S: \Omega \times \mathcal{P} \rightarrow \mathbb{R} \cup \{\infty\} \quad \quad (1) S:Ω×P→R∪{
∞}(1)
它将数值赋给预测 P ∈ P P \in \mathcal{P} P∈P和观测 y ∈ Ω y \in \Omega y∈Ω。我们用相关的CDF F F F或PDF F F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









