




3.1 PC 架构
首先,我们看看当下许多PC中都使用的酷睿2(Core2)处理器的典型架构,然后分析一下它是如何影响我们使用GPU 加速器的(如图 3-1所示)。
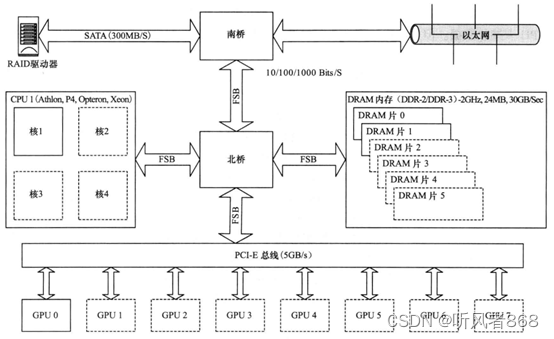
图3-1典型的酷睿2(Core2)系列处理器的结构图
由于所有的 GPU 设备都是通过 PCI-E(Peripheral Communications Interconnect Express)总线与处理器相连,所以我们以PCI-E2.0总线标准来讨论本章内容。PCI-E2.0是目前最快的总线标准,它的传输速率为5GB/s。在撰写本书的过程中,PCI-E3.0已经问世了,它的带宽明显提高了。
然而,为了从处理器中获取数据,我们需要通过与低速前端总线(Front-Side Bus,FSB)连接的北桥(Northbridge)。理论上,FSB的时钟频率最高只能达到1600MHz,而很多实际设计的产品就更低了。这通常只是一个高速处理器时钟频率的1/3.
访问内存也需要经过北桥,访问外设则需要经过北桥和南桥(Southbridge)。北桥服务于所有的高速设备,如内存、CPU、PCI-E总线接口等;而“南桥”则服务于低速设备,如硬盘USB、键盘、网络接口,等等。当然,把硬盘控制器直接连接到PCI-E总线接口上也是可能的。实际上,在这样的系统中,这是要获得高速RAID数据访问的唯一正确方式。
PCI-E是一个很有意思的总线。与其上一代PCI(Peripheral Component Interconnect,外围设备互连)总线不同,PCI-E提供一个确定的带宽。在原先的PCI系统中,每一个设备都可以使用总线的全部带宽,但一次只能让一个设备使用。因此,你增加的PCI卡越多,每个卡能够获得的可用带宽就越少。PCI-E总线通过引入PCI-E通道(lane)解决了这个问题。这些通道是一些高速的串行链路,这些链路组合在一起构成了X1、X2、X4、X8或X16 链路。目前,绝大多数GPU使用的至少是如图3-1所示的PCI-E2.0的X16规范,此配置下提供5GB/s的全双工总线。这意味着,数据的传入与传出可以同时进行并享有同样的速度也就是说,我们在以5GB/s的速度向GPU卡传送数据的同时,还能够以5GB/s的速度从GPU卡接收数据。但是,这并不意味着如果不接收数据,我们就可以10GB/s的速度向GPU卡传送数据(即带宽是不可以累加的)。
在一个典型的超级计算机或者一个台式机应用程序中,我们常常需要处理一个很大的数据集。一个超级计算机需要处理上千万亿字节(PB)的数据,而一个面计算机也要处理数十亿字节(GB)的高分辨率视频图像。这两种情况都需要从外设取来大量的数据,单块100MB/s的硬盘每分钟只能上传6GB的数据。按照这个速度,读取一个标准的1万亿字节(TB)硬盘上的全部内容需要两个半小时以上的时间。
如果使用集群系统中常用的MPI(MessagePassingInterface)作为通信软件,像图 3-1这样将以太网(Ethernet)接口连接到南桥芯片而不是PCI-E总线,构成的通信延迟是很大的。因此,诸如InfniBand这样的专用高速互连设备或者10千兆位(Gigabit)以太网卡常常连接到PCI-E总线上。不过,这就占用了原本可用于GPU的总线插槽。之前,并没有直接用于GPU的MPI接口函数。这类系统的所有通信都需要经过PCI-E总线连通到CPU,然后再原路返回。CUDA4.0SDK提供的GPU直连(GPU-Direct)技术就解决了这个问题。借助 SDK的支持,InfniBand卡就可以直接与GPU通信,而无须先经过CPU转发。SDK中的这项升级还支持GPU与GPU的直接通信。
Nehalem架构中有很多新的变化,其中最主要的变化就是用X58芯片组代替了“北桥”和“南桥”芯片。Nehalem架构引人了快速通道互联(Quick Path Interconnect,QPI)技术,该技术明显优于“前端总线”(Front Side Bus,FSB),达到了与 AMD 公司的超传输(HyperTransport)相当的水平。QPI是一种高速的、可用于与其他设备或CPU 直接通信的互连结构。在一个标准的Nehalem系统中,OPI的作用是连接内存子系统,并通过X58芯片组连接PCI-E子系统(如图3-2所示)。与Extreme/Xeon型号的处理器配合时,QPI的工作速率要么是 4.8GT/s',要么是 6.4GT/s。
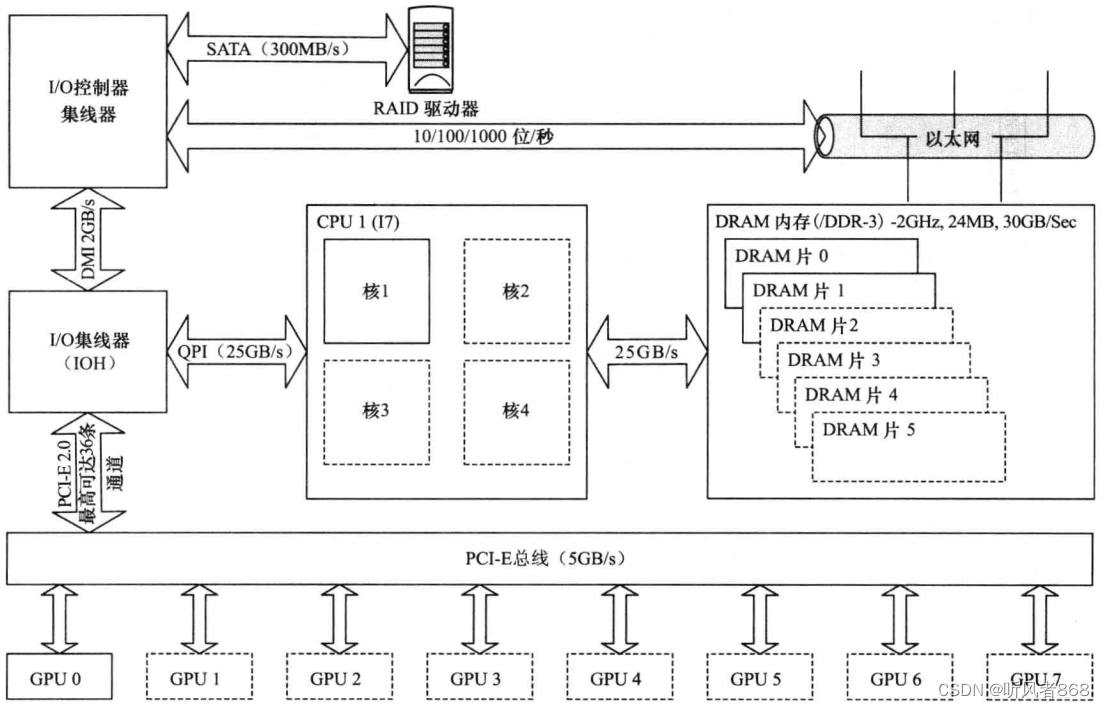
图3-2 Nehalem/X58系统
当使用X58芯片组和LGA1366处理器插槽时,共计有36个PCI-E通道。这就意味着,配置为X16时最多可以支持2个GPU卡,配置为X8时最多可以支持4个GPU卡。在LGA2011插槽出现之前,这是为GPU卡数据传输提供的最好的带宽解决方案。
在较小的P55 芯片组中,也可以使用X58方案。不过,这时仅有16个PCI-E通道。这就意味着,配置为X16时仅支持1个GPU卡,配置为X8时最多可以支持2个GPU卡。
从I7/X58芯片组开始,英特尔公司引入了如图3-3所示的沙桥(SandyBridge)设计方案。其最引人注目的改进之一是支持传输速率可达600MB/s的SATA-3标准。通过与固态硬盘(SSD)结合,在存/取数据时,“沙桥”可以提供很高的输入/输出性能。
沙桥的另外一个主要进步是引人了AVX(Advanced VectorExtensions,高级向量扩展)指令集,该指令集也同时被AMD的处理器支持。AVX允许向量指令最多可以并行处理4个双精度浮点数(256位或32字节)。这是一个很有趣的改进,可以使CPU上的计算密集型应用程序获得一个很高的加速比。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4
4

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











