










原本准备看一下DeepSpeed如何对接使用NCCL的,如何初始化通信后端的,没想到DeepSpeed目前就是直接封装的Pytorch的通信后端。瞬间傻在原地,它自己的通信后端函数还未实现。
哈哈哈,Megatron就更不要脸了,就直接用Pytorch的通信后端,封装都不封装。
一、DeepSpeed如何调用NCCL
视频教程在这:
DeepSpeed调用NCCL 通信后端初始化init_distributed()源码解读_哔哩哔哩_bilibili
init_distributed()程序核心逻辑/步骤:
总结来说:
如果torch的分布式通信后端已经初始化,deepspeed直接使用;
如果torch的分布式通信后端未初始化,利用MPI获取和设置环境变量后初始化torch的NCCL分布式通信后端,共deepSpeed使用。
核心步骤如下:
1、global cdb #Communication Data Backend 的缩写,跟踪和管理分布式通信后端的状态。
2、检查cdb状态,如果为空或者未被初始话,则告诉后续程序需要初始化通信后端dist_init_required is true
3、如果cdb为空,设置通信后端NCCL/gloo/MPI等
4、如果cdb为空并且torch的分布式后端已被初始化,则设置DeepSpeed通信后端为torch通信后端。完成通信后端初始化,函数退出!
5、如果不需要初始化通信后端dist_init_required is False,函数完成退出!
6、如果需要初始化通信后端,
6a、如果开启MPI自动发现并且必须环境变量没有,根据不同运行环境(Azure微软云/AWS亚马逊云/其它环境 这两家肯定打钱了)设置环境变量,以支持 PyTorch 分布式训练时使用 NCCL后端。
6b、如果检查通信后端已被初始化,通信后端初始化完成,函数完成退出!
6c、如果检查通信后端未被初始化,初始化torch通信后端,并赋值给cdb,函数完成退出!这里要注意的点是,本函数中调用两次TorchBackend()输入并不相同,一个是torch分布式后端已经初始化赋值即可(对应步骤4),这里是是torch分布式后端没有初始化需要环境变量初始化。
源码速递:
源码位置:DeepSpeed-master\deepspeed\comm\comm.py
#DeepSpeed通信后端初始化
def init_distributed(dist_backend=None,
auto_mpi_discovery=True,
distributed_port=TORCH_DISTRIBUTED_DEFAULT_PORT,
verbose=True,
timeout=default_pg_timeout,
init_method=None,
dist_init_required=None,
config=None,
rank=-1,
world_size=-1):
''' Initialize dist backend, potentially performing MPI discovery if needed
Arguments:
dist_backend: Optional (str). torch distributed backend, e.g., nccl, mpi, gloo, hccl
auto_mpi_discovery Optional (bool). if distributed environment variables are not set, attempt to discover them from MPI
distributed_port: Optional (int). torch distributed backend port
verbose: Optional (bool). verbose logging
timeout: Optional (timedelta). Timeout for operations executed against the process group. Default value equals 30 minutes.
init_method: Optional (string). Torch distributed, URL specifying how to initialize the process group. Default is “env://” if no init_method or store is specified.
config: Optional (dict). DeepSpeed configuration for setting up comms options (e.g. Comms profiling)
rank: Optional (int). The current manually specified rank. Some init_method like “tcp://” need the rank and world_size as well (see: https://pytorch.org/docs/stable/distributed.html#tcp-initialization)
world_size: Optional (int). Desired world_size for the TCP or Shared file-system initialization.
'''
#1、Communication Data Backend 的缩写,跟踪和管理分布式通信后端的状态。
global cdb
configure(deepspeed_config=config)
#2、检查cdb状态,如果为空或者未被初始话,则告诉后续程序需要初始化通信后端dist_init_required is true
if dist_init_required is None:
dist_init_required = cdb is None or not cdb.is_initialized()
#3、如果cdb为空,设置通信后端NCCL/gloo/MPI等
if cdb is None:
init_deepspeed_backend(get_accelerator().communication_backend_name(), timeout, init_method)
set_backend()
utils.logger.info(f'cdb={cdb}')
#4、如果cdb为空并且torch的分布式后端已被初始化,则设置DeepSpeed通信后端为torch通信后端。完成通信后端初始化,函数退出!
if cdb is None and torch.distributed.is_initialized():
# The user initialized torch.dist themselves, create cdb and short-circuit
cdb = TorchBackend(dist_backend, timeout, init_method)
return
#5、如果不需要初始化通信后端dist_init_required is False,函数完成退出!
if dist_init_required is False:
assert (
cdb is not None and cdb.is_initialized() is True
), "Distributed backend is not initialized. Please set dist_init_required to True or initialize before calling deepspeed.initialize()"
#6、如果需要初始化通信后端,
else:
#6a、如果开启MPI自动发现并且必须环境变量没有,根据不同运行环境(Azure微软云/AWS亚马逊云/其它环境 这两家肯定打钱了)设置环境变量,以支持 PyTorch 分布式训练时使用 NCCL后端。
# Initialize torch distributed if needed
required_env = ["RANK", "WORLD_SIZE", "MASTER_ADDR", "MASTER_PORT", "LOCAL_RANK"]
if auto_mpi_discovery and not all(map(lambda v: v in os.environ, required_env)):
if verbose:
utils.logger.info("Not using the DeepSpeed or dist launchers, attempting to detect MPI environment...")
if in_aml() and not in_dlts():
patch_aml_env_for_torch_nccl_backend(verbose=verbose)
elif in_aws_sm():
patch_aws_sm_env_for_torch_nccl_backend(verbose=verbose)
else:
mpi_discovery(distributed_port=distributed_port, verbose=verbose)
#6b、如果检查通信后端已被初始化,通信后端初始化完成,函数完成退出!
if cdb is not None and cdb.is_initialized():
if int(os.getenv('RANK', '0')) == 0:
utils.logger.info('Distributed backend already initialized')
#6c、如果检查通信后端未被初始化,初始化torch通信后端,并赋值给cdb,函数完成退出!
else:
assert isinstance(timeout, timedelta)
if dist_backend is None:
dist_backend = get_accelerator().communication_backend_name()
if int(os.getenv('RANK', '0')) == 0:
utils.logger.info('Initializing TorchBackend in DeepSpeed with backend {}'.format(dist_backend))
#这里要注意的点是,本函数中调用两次TorchBackend()输入并不相同,一个是torch分布式后端已经初始化赋值即可(对应步骤4),这里是是torch分布式后端没有初始化需要环境变量初始化。
# Create a torch backend object, initialize torch distributed, and assign to cdb
cdb = TorchBackend(dist_backend, timeout, init_method, rank, world_size)下面的代码就是TorchBackend对torch通信接口封装,将torch.distributed.all_reduce()封装为deepspeed自己的通信接口all_reduce()。
源码位置:deepspeed\comm\torch.py
@compiler.disable
def all_reduce(self, tensor, op=torch.distributed.ReduceOp.SUM, group=None, async_op=False):
op = self._reduce_op(op)
return torch.distributed.all_reduce(tensor=tensor, op=op, group=group, async_op=async_op)二、Megatron调用NCCL
如下图所示,Megatron就更不要脸了,就直接用Pytorch的通信后端,封装都不封装。哈哈哈哈哈哈。torch.distributed.broadcast()就是torch的通信后端。
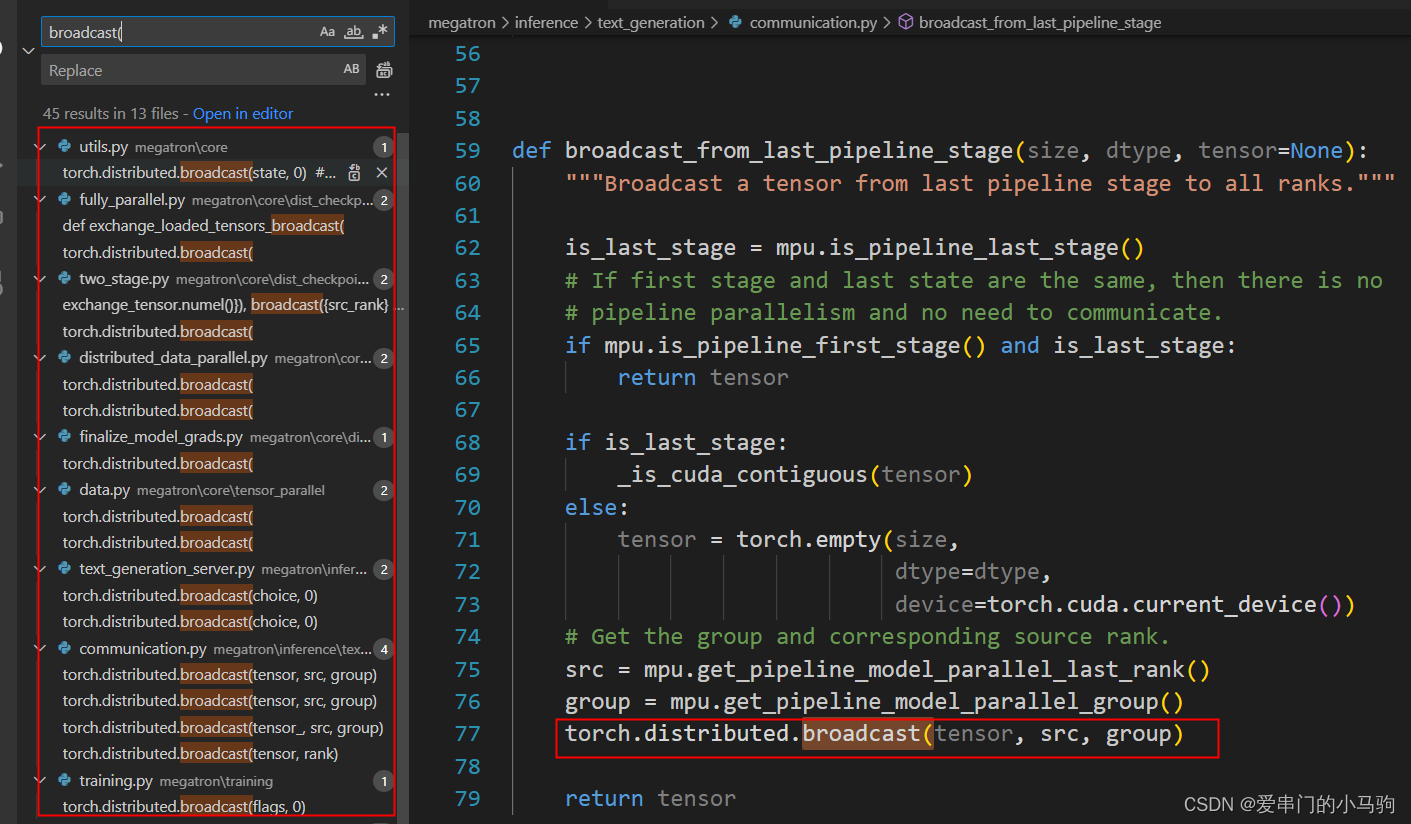
当然Megatron也对torch的通信后端做了封装,但是是功能性的封装,比如下面的代码,封装了torch.distributed.broadcast(),不是把它封装为Megatron自己用的broadcast集合通信接口,而是实现特定功能,下面代码用于在模型并行(model parallelism)的最后一个流水线(pipeline)阶段将张量(tensor)广播(broadcast)到所有其他流水线阶段。
源码位置:megatron\inference\text_generation\communication.py
def broadcast_from_last_pipeline_stage(size, dtype, tensor=None):
"""Broadcast a tensor from last pipeline stage to all ranks."""
is_last_stage = mpu.is_pipeline_last_stage()
# If first stage and last state are the same, then there is no
# pipeline parallelism and no need to communicate.
if mpu.is_pipeline_first_stage() and is_last_stage:
return tensor
if is_last_stage:
_is_cuda_contiguous(tensor)
else:
tensor = torch.empty(size,
dtype=dtype,
device=torch.cuda.current_device())
# Get the group and corresponding source rank.
src = mpu.get_pipeline_model_parallel_last_rank()
group = mpu.get_pipeline_model_parallel_group()
torch.distributed.broadcast(tensor, src, group)#封装torch通信后端#########################
return tensor














 1128
1128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









