






| DeepSeed | DeepSeed代表性功能 | Megatron | Megatron代表性功能 | 备注 | |
| GPU底层优化 | 有 | 开创性的全栈 GPU 内核设计FP6 量化 | 更牛逼 | Fused CUDA Kernels | 毕竟Megatron是Nvidia亲儿子,底层优化信手拈来。 |
| 数据并行 | 更牛逼 | Zero系列的分布式数据并行方案 | 有 | 优化器分片 | Megatron也做了类似Zero1的优化器分片,但数据并行没有deepspeed强 |
| 模型并行 | 有 | 更牛逼 | Megatron的张量并行很牛 |
1、GPU底层优化
Megatron是Nvidia搞的,那必然对Nvidia GPU有着特定的优化。Megatron-Core 提供核心构建模块,例如注意力机制、转换器模块和层、归一化层和嵌入技术等,这些模块必然做了特定优化。
DeepSpeed也做了GPU底层优化,例如:DeepSpeed开创性的全栈 GPU 内核设计FP6 量化。
DeepSpeed/blogs/deepspeed-fp6/03-05-2024/README.md at master · microsoft/DeepSpeed · GitHub
2、数据并行
DeepSpeed的数据并行相比于Megatron做的更牛逼。
DeepSpeed数据并行有很多种策略,例如:Zero1、Zero2、Zero3、Zero++等,这些分布式策略可参考教程:
Megatron做了分布式优化器(优化器分片类似于Zero1)。
DeepSpeed官方也用图示说明了,DeepSpeed的数据并行做的更牛逼。
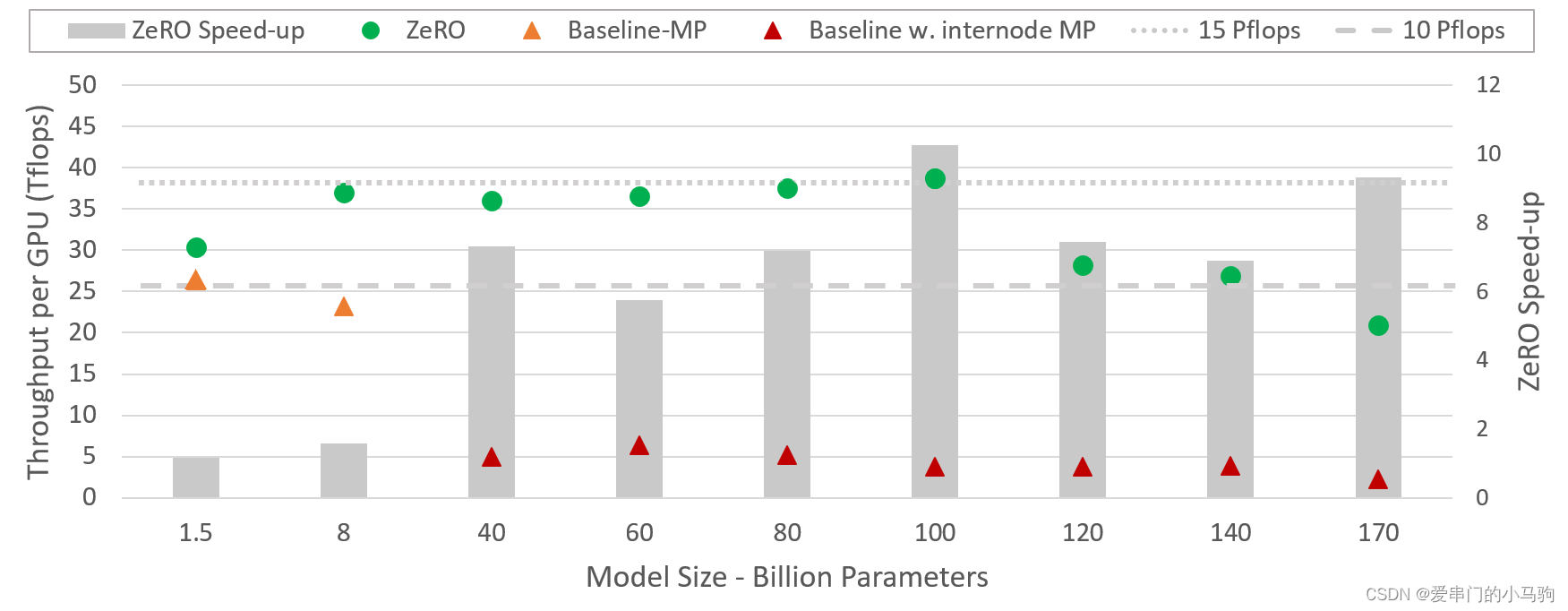
该图描述了与单独使用 Megatron-LM 相比,DeepSpeed(将 ZeRO 驱动的数据并行性与 NVIDIA Megatron-LM 的模型并行性相结合)的系统吞吐量改进。
哈哈哈,DeepSpeed的数据并行于Megatron的模型并行结合,这是不是也说明了,Megatron的模型并行做的更好。
3、模型并行
哈哈哈,如上图所示,DeepSpeed的数据并行于Megatron的模型并行结合,这是不是也说明了,Megatron的模型并行做的更好。
DeepSeed官方教程里面,模型并行一节专门讲了将DeepSeed的数据并行与Megatron的模型并行集成。链接:Megatron-LM GPT2 - DeepSpeed
Megatron官方教程里面,也提到利用DeepSpeed和Megatron共同训练模型。[2201.11990] Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model (arxiv.org)
哈哈哈,现在DeepSpeed与Megatron明显的合作共赢啊!
视频教程
该文档还在持续更新中,后续有必要视频教程的话,视频教程会放在这,欢迎关注。

















 2986
2986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









