






背景
距上次发文章,又过去好久。这期分享给大家带来的是Ai作画的图结构控制几种方法。现在大家用AI作画大部分情况是直接使用AI单图生成能力,其实并不太会取考虑构图,也不太会考虑到大图的图结构这件事。其实构图这件事是一件很综合复杂的事情,很难去定义什么样的叫做构图。AI直接生成出来的单图也并非完全是没有结构,我这边讲的结构是在单图之上的更宏观、更叙述性的构图。
一般构图方式有三大类:
1.直接文本描述,图的结构,左边是什么,右边是什么,上边是什么...
2.用controlnet的segment图来控制不同区块图生成内容
3.区块控制内容+流程控制融合个区块
4.区块控制+生成内容连续行约束保证图一致
前面两种方法是在单张图上单步生成控制,后面两种方法是分工序分多步来控制图结构。
1.1 单张图单步控制的好处就是生成图的速度快,产出的图一致性好,图的风格比较容易保持一致,不容易出现图不同区块撕裂的问题;
1.2 单张图单步控制的问题,对于更大的图,需要叙述的内容非常多的图,单张图单步生成很容易出现细节的遗忘,信息丢失问题(这个是多问题导致的,跟sd架构有关,也跟当时clip的77个词长度限制有关),对于一次生成超大图对机器性能的要求非常高
2.1 对于分区快多步生成的优点,可以无限延展图大小、对于设备性能要求会更低,生成图的可控性会更好,对于复杂的需要表现更多细节的图会更好,复杂描述一样能够胜任
2.2 分区快多步生成的缺点,生成图的时间和图的尺寸成正比例关系,需要图片的生产者需要很强的构图能力,在脑海里要对每个区块有很清晰的画面描述,相隔图之间风格差异不能太大,只能做到渐变式过渡产图。
下面部分会总结下,个人对controlnet segmnet、mixture diffusion、multi-duffusion、outpaint这几种对画面布局控制模型的差异。mixture diffusion和multi-diffusion这里我会把它们归成一类,都是分区快+整体融合算法,巨头细节差异会在算法介绍部分介绍。
controlnet segement,可以通过sement摆放控制图的大体布局,但是无法对每个sement做更精细控制(比如文字描述控制)
mixture diffusion,可以分区快的对每个区块做相对精细的控制,同时可以保证个区块之风格一致性。
outpaint,可以分区快来对每个区域精准描述,但是比较难难保证个区块风格一致
算法介绍
controlnet segment
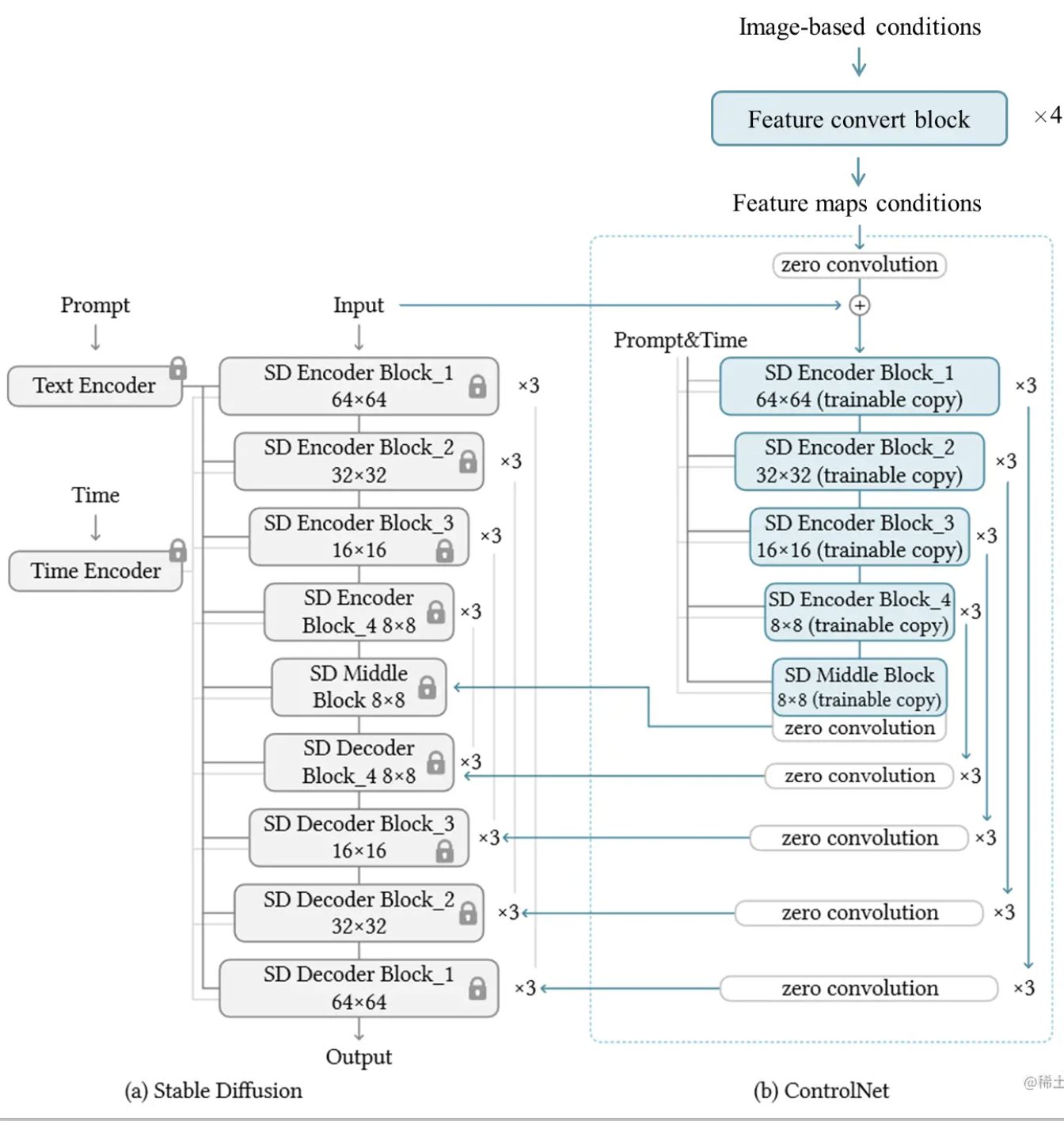
ControlNet 网络设计
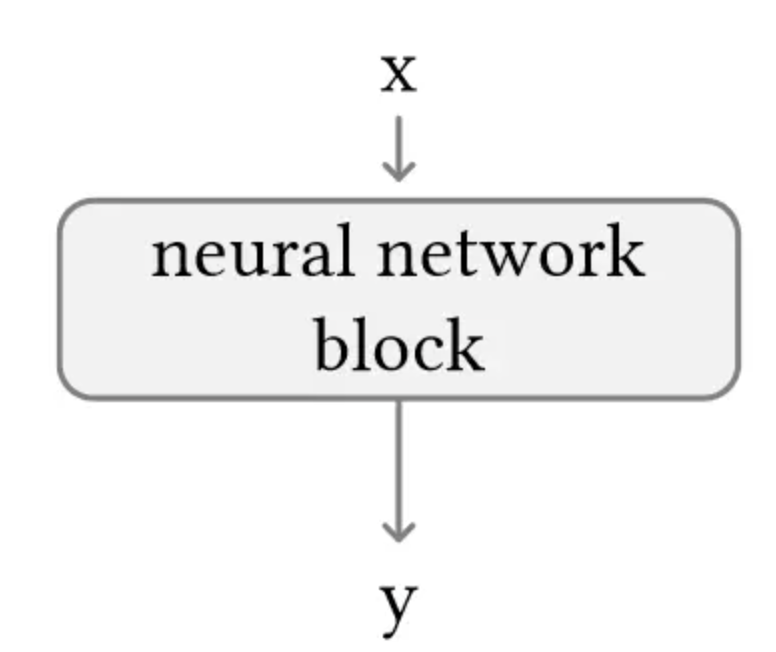
在一个扩散模型中,如果不加ControlNet的扩散模型,其中原始的神经网络F输入x获得y,参数用Θ表示
y=F(x;Θ)也就是下图这个样子。
ControlNet中,就是将模型原始的神经网络锁定,设为locked copy。
然后将原始网络的模型复制一份,称之为trainable copy,在其上进行操作施加控制条件。然后将施加控制条件之后的结果和原来模型的结果相加获得最终的输出。
经过这么一顿操作之后,施加控制条件之后,最后将原始网络的输出修改为:
yc=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)
其中zero convolution,也就是零卷积层Z是初始化weight和bias为0,两层零卷积的参数为{Θz1,Θz2}。
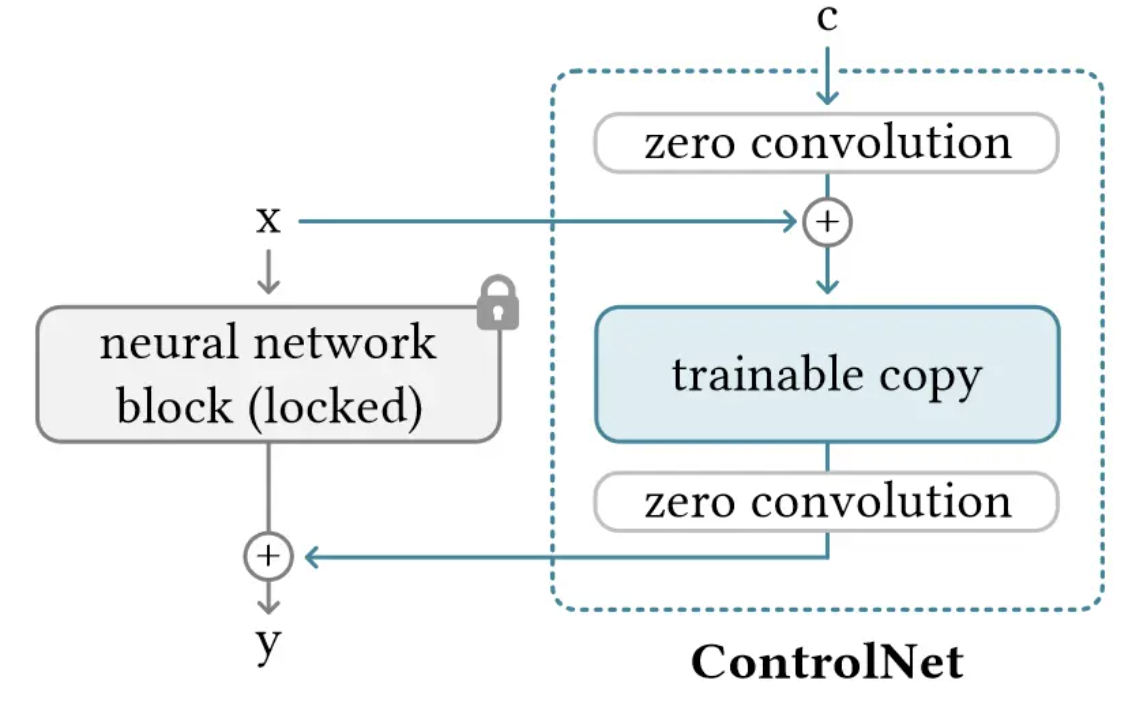
将控制条件通过零卷积之后,与原始输入相加,相加之后进入ControlNet的复制神经网络块中,将网络输出再做一次零卷积之后与原始网络的输出相加。
初始化之后未经训练的ControlNet参数应该是这样的:
将控制条件通过零卷积之后,与原始输入相加,相加之后进入ControlNet的复制神经网络块中,将网络输出再做一次零卷积之后与原始网络的输出相加。
初始化之后未经训练的ControlNet参数应该是这样的:
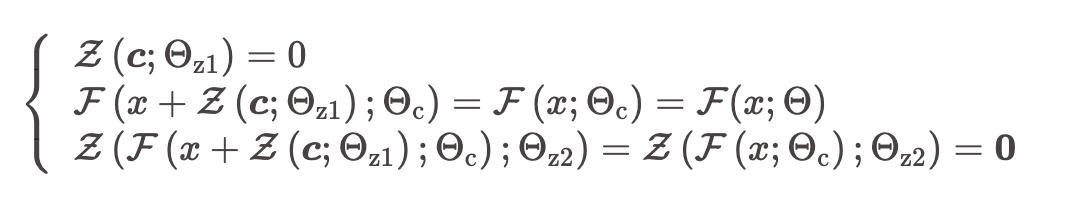
也就是说ControlNet未经训练的时候,输出为0,那加到原始网络上的数字也是0。这样对原始网络是没有任何影响的,就能确保原网络的性能得以完整保存。之后ControlNet训练也只是在原始网络上进行优化,这样可以认为和微调网络是一样的。
ControlNet in Stable Diffusion
上一部分描述了ControlNet如何控制单个神经网络块,论文中作者是以Stable Diffusion为例子,讲了如何使用ControlNet对大型网络进行控制。下图可以看到控制Stable Diffusion的过程就是将Encoder复制训练,decoder部分进行skip connection。
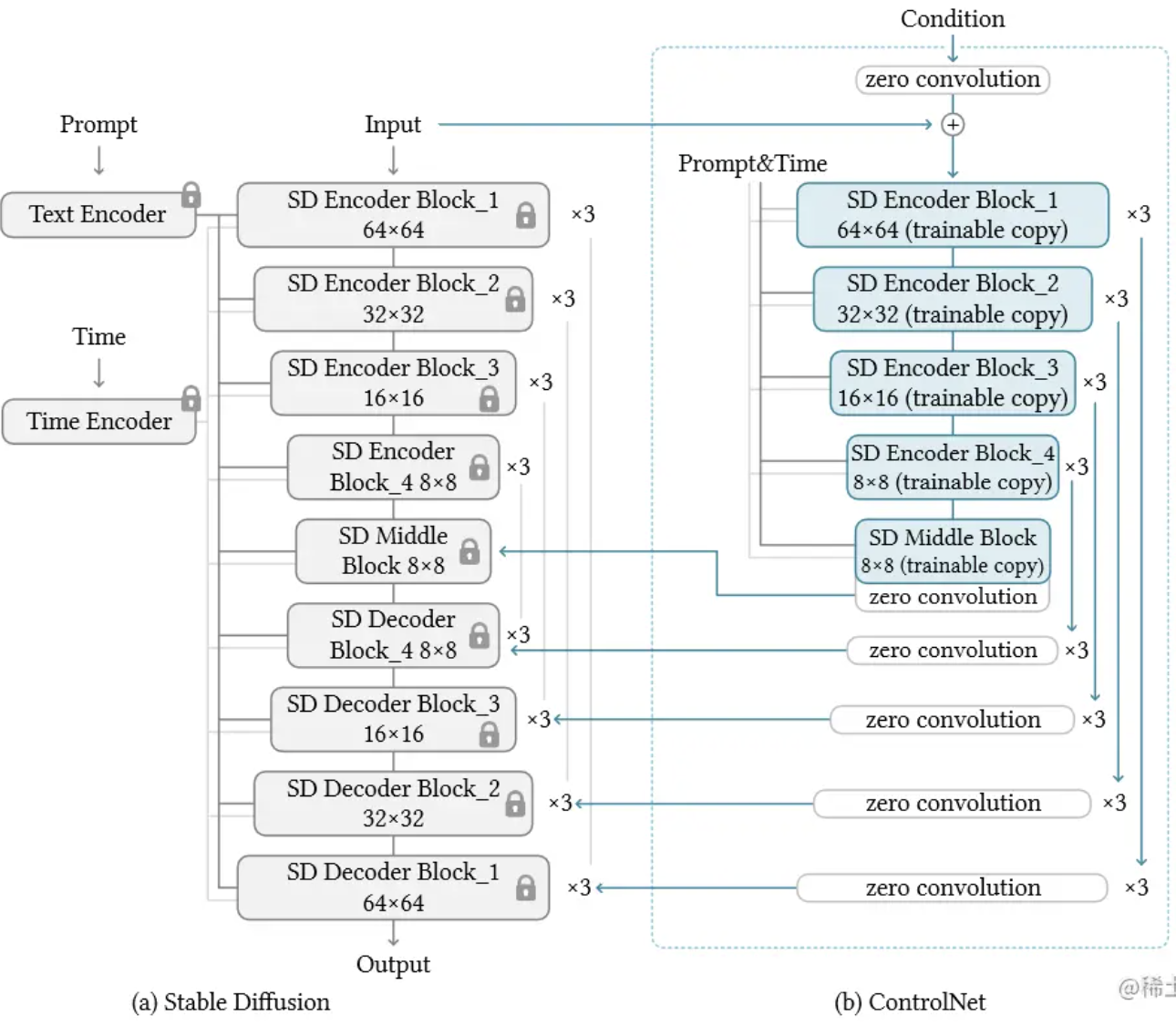
Stable Diffusion有一个预处理步骤,将512×512的图片转化为64×64的图之后再进行训练,因此为了保证将控制条件也转化到64×64的条件空间上,训练过程中添加了一个小网络EE将图像空间条件转化为特征图条件。
cf=E(ci)cf=E(ci)
这个网络EE是四层卷积神经网络,卷积核为4×4,步长为2,通道16,32,64,128,初始化为高斯权重。这个网络训练过程是和整个ControlNet进行联合训练。
训练的目标函数为:
L=Ez0,t,ct,cr,ϵ∼N(0,1)[∥ϵ−ϵθ(zt,t,ct,cf))∥22]
使用的就是人家Stable Diffusion原始的目标函数改了改。
先看一下原始的Stable Diffusion的目标函数:
LLDM:=EE(x),ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t)∥22]
将采样ztzt使用网络ϵθϵθ去噪之后和原图经过网络ϵϵ获得的潜变量计算L2L2loss,看其重建的效果。
那再回到
L=Ez0,t,ct,cr,ϵ∼N(0,1)[∥ϵ−ϵθ(zt,t,ct,cf))∥22]
将原始图像经过ϵϵ之后获得潜变量,和经过网络ϵθϵθ重建之后的图算L2L2loss。原来Stable Diffusion中解码器要处理的是采样ztzt和时间步长tt,在这里加了两个控制条件:
- 文字prompt ctct
- 任务相关的prompt cfcf
训练过程中将50 %的文本提示ctct随机替换为空字符串。这样有利于ControlNet网络从控制条件中识别语义内容。这样做的目的是,当Stable Diffusion没有prompt的时候,编码器能从输入的控制条件中获得更多的语义来代替prompt。(这也就是classifier-free guidance。)

mixture diffusion

算法流程,文本控制每个区块图生成,然后对整幅图做滑块生成保持整体风格一致;重复循环上面的两个步骤直到达到用户设定step。对应的具体代码如下:
1.第一层循环控制整幅图生成需要step多少步
2.第二个循环控制有多少个分块区域
3.padding部分就是整图滑块生成,保持整体画风一致

论文里面还提出了可以对已有图外扩生成方法,能够保持已有图和延续出来的文本控制生成图比较协调一致。算法流程和上面流程整体式一样的,只不过增加了一个如果这个区域已经有用户希望保留的图,那就把用户输入图作为image encoder输入,而不是text2image的输入是一副随机噪点图。具体代码逻辑如下:

例子效果图如下:
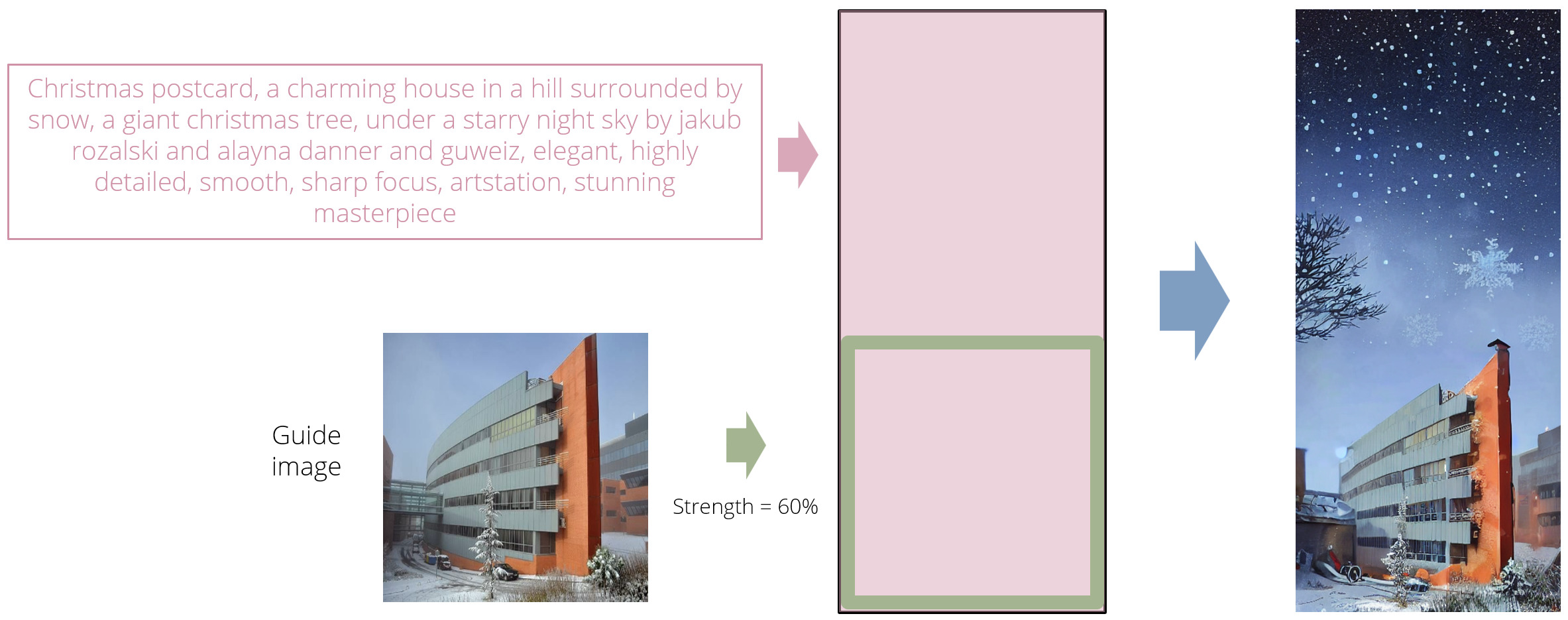
扩散器混合方法有几个好处:
• 每个扩散模型都可以作用于画布的不同区域,使用不同的提示,从而允许在图像的特定位置生成对象,或在样式之间的空间中引入平滑过渡。
• 由于所有扩散过程共享同一个神经网络,所提出方法的内存占用与受单个扩散过程影响的最大区域所需的内存基本相同。 这允许在低内存 GPU 中生成高分辨率图像。
• Mixed of Diffusers 与 SDEdit [15] 兼容,因此允许对图像的生成和文本提示进行调节,从而允许“图像到图像”和outpaint。
• 所提出的方法可以使用任何预训练的扩散模型。 即使在潜在空间中工作的扩散模型也可以使用,只要它们允许定义输入空间中的像素和潜在空间中的位置之间的近似映射。
multi-diffusion
MultiDiffusion是基于Reference Model的一种通用生成框架,建模优化目标是,让图整体一致,同时要满足指定区域内生成的图和约束条件是一致的。数学建模如下:
 Ψ:J×Z→J
Ψ:J×Z→J
它的图像空间为J =RH′×W′×C,条件空间为 z 。从初始噪声开始,按序列生成一系列图像
JT,JT−1,...,J0 s.t. Jt−1 =Ψ(Jt|z)
主要想法是将 Ψ 定义为与 Φ 尽可能一致。 定义了一组目标和参考图像空间之间的映射 Fi : J → I,以及一组相应的条件空间之间的映射:λi : Z → Y 其中 i ∈ [n] = {1,.. .,n}。 这些映射取决于应用。
接着定义了一组目标图像空间和参考图像空间之间的区域映射 Fi : J → I ,以及一组相应的条件空间之间的映射 λi : Z → Y ,其中 i ∈ [n] = {1,...,n}。这些映射的形式取决于具体应用场景,映射关系可表示为:
Iti = Fi(Jt),yi = λi(z)
本文的目标是使每个 MultiDiffusion 采样Jt−1 = Ψ(Jt|z) , 对于所有 i ∈ [n] = {1,.. .,n},尽可能使得 Jt−1 = Ψ(Jt|z)接近Reference Model采样 Φ(Iti|yi), i ∈ [n],可以通过以下过程进行优化:
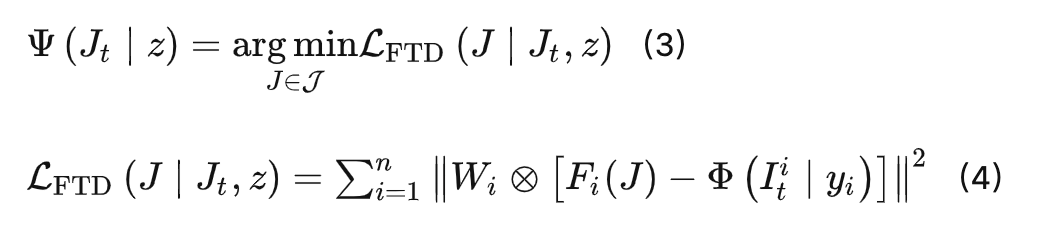
其中 W ∈ RH×W 是每个像素的权重,是per-pixel权重, ⊗ 是Hadamard乘法。
总结一下上述过程,如图1所示,MultiDiffusion生成过程是从噪声图像 Jt开始,在每个生成步骤中,通过一个优化任务,使得目标图像 jt的每个crop(fi(jt) 将尽可能接近参考图像去噪采样 Φ(fi(jt)) 。虽然各个采样 Φ(fi(jt)) 可能会将图像拉向不同的方向,但MultiDiffusion会将这些不一致的方向融合到全局去噪Ψ(jt) 中,从而产生高质量的连贯图像。

上面伪代码还是太凝练,我们可以看看作者具体代码实现,是怎么来保证corp部分控制,以及如何来保证全图风格一致的。
with torch.autocast('cuda'):
for i, t in enumerate(self.scheduler.timesteps): #整图迭代多少step
count.zero_()
value.zero_()
for h_start, h_end, w_start, w_end in views:#有多少个控制区,需要生成
# TODO we can support batches, and pass multiple views at once to the unet
latent_view = latent[:, :, h_start:h_end, w_start:w_end]
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latent_view] * 2)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeds)['sample']
# perform guidance
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_cond - noise_pred_uncond)
# compute the denoising step with the reference model
latents_view_denoised = self.scheduler.step(noise_pred, t, latent_view)['prev_sample']
value[:, :, h_start:h_end, w_start:w_end] += latents_view_denoised
count[:, :, h_start:h_end, w_start:w_end] += 1
# take the MultiDiffusion step
latent = torch.where(count > 0, value / count, value)
# Img latents -> imgs
imgs = self.decode_latents(latent) # [1, 3, 512, 512]
img = T.ToPILImage()(imgs[0].cpu())
return img
从代码实现看,作者在论文中提到的挺复杂的如何保证选定区域-文本控制内容一致性的和整体图求差的部分代码并为实现,只是锁理论上是这样的数学建模。当然你如果有兴趣完全可以在作者代码基础之上做改进,显示的把这部分能力写出来看看是否会比现在更好。

outpainting
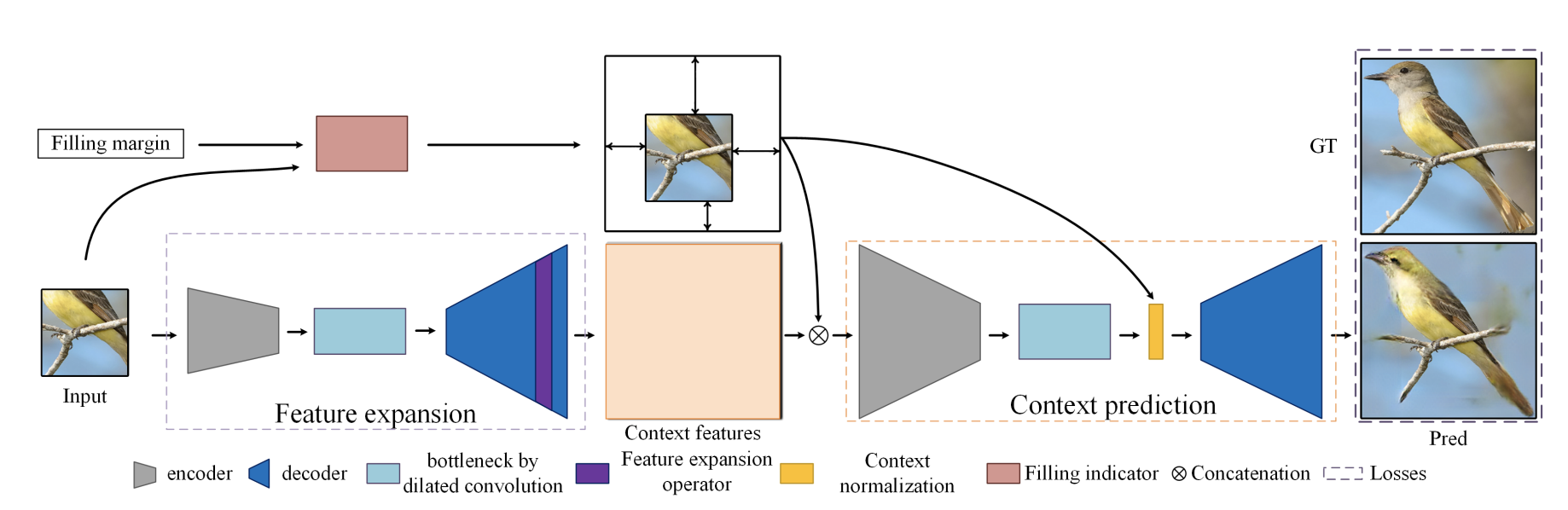
outpaint在是18年左右就提出的一个概念,吴恩达老师在他课程中给学生布置的作业里有这么一个课后实现。利用GAN的方法,通过输入的图像特征作为引导信息来生成一副更合理的图。其实原理和逻辑就是GAN不是有很强的信息生成能力吗,可以从随机噪声作为输入,最后能够编解码出一张非常好的图,那有没办法对输入少部分的非随机噪声的图生成一张好的图,生成的图还能够保证输入的部分图的原貌。
下面这幅图是后面提出来的工作,但是原理和outpaint是致的。
小结
介绍了几种图片布局控制的方法,详细介绍了常用的3种方法的算法原理和实现。
对图布局思路,无非就是单图单步生成,还是多步生成,还是多步+整体融合风格,三种思路。目前看来,每种方法都各有优缺点,现在的图结构布置,其实也还没有完全得到解决,要想得到比较好的效果,还是要打组合拳。
1.controlnet segment可以比较好的控制单张图的结构,但对每个部分物体较详细细节控制不太好
2.mixture diffusion、multdiffusion可以较好的控制局部细节,整体风格一致性保持也就好,但是还是需要比较高技巧
3.outpaint可以对局部细节控制较好,但是整体一致性控制相对较弱,要较高技巧才能控制好效果
参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









