










CSDN链接:
Linux设备模型剖析系列一(基本概念、kobject、kset、kobj_type)
Linux设备模型剖析系列之三(device和device driver)
三、uevent
1. uevent的功能
- uevent是kobject的一部分,用于在kobject状态发生改变时(增加、移除等),通知用户空间程序。用户空间程序收到这样的事件后,会做相应的处理。该机制通常是用来支持热拔插设备的,例如U盘插入后,USB相关的驱动软件会动态创建用于表示该U盘的device结构(相应的也包括其中的kobject),并告知用户空间程序,为该U盘动态的创建/dev/目录下的设备节点,更进一步,可以通知其它的应用程序,将该U盘设备mount到系统中,从而动态的支持该设备。
2. uevent在kernel中的位置
下面图片描述了uevent模块在内核中的位置:
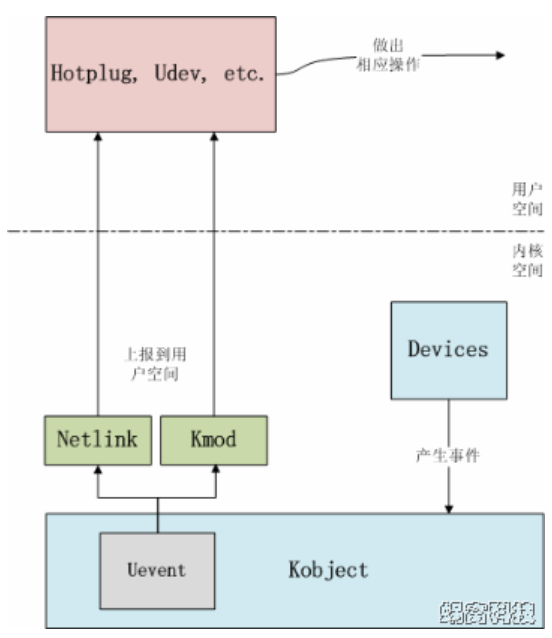
由此可知,uevent的机制是比较简单的,设备模型中任何设备有事件需要上报时,会触发uevent提供的接口。uevent模块准备好上报事件的格式后,可以通过两个途径把事件上报到用户空间:一种是通过kmod模块,直接调用用户空间的可执行文件;另一种是通过netlink通信机制,将事件从内核空间传递给用户空间。有关kmod和netlink,会在其它文章中描述,因此本文就不再详细说明了。
3. uevent的内部逻辑解析
3.1 源代码的位置
uevent的代码比较简单,主要涉及kobject.h和kobject_uevent.c两个文件,如下:
- include/linux/kobject.h
- lib/kobject_uevent.c
3.2 数据结构描述
kobject.h定义了uevent相关的常量和数据结构,如下:
- kobject_action
/* include/linux/kobject.h, line 50 */
enum kobject_action {
KOBJ_ADD,
KOBJ_REMOVE,
KOBJ_CHANGE,
KOBJ_MOVE,
KOBJ_ONLINE,
KOBJ_OFFLINE,
KOBJ_MAX
};
- kobject_action定义了event的类型,包括:
ADD/REMOVE: kobject(或上层数据结构)的添加/移除事件。
ONLINE/OFFLINE:kobject(或上层数据结构)的上线/下线事件,即是否使能。
CHANGE: kobject(或上层数据结构)的状态或者内容发生改变。如果设备驱动需要上报的事件不再上面事件的范围内,或者是自定义的事件,可以使用该event,并携带相应的参数。
MOVE: kobject(或上层数据结构)更改名称或者更改parent(意味着在sysfs中更改了目录结构)。
MAX: 事件种类的最大值
-
kobj_uevent_env
/* include/linux/kobject.h, line 31 */ #define UEVENT_NUM_ENVP 32 /* number of env pointers */ #define UEVENT_BUFFER_SIZE 2048 /* buffer for the variables */ /* include/linux/kobject.h, line 116 */ struct kobj_uevent_env { char *envp[UEVENT_NUM_ENVP]; int envp_idx; char buf[UEVENT_BUFFER_SIZE]; int buflen; };envp,指针数组,用于保存每个环境变量的地址,最多可支持的环境变量数量为UEVENT_NUM_ENVP。
envp_idx,用于访问环境变量指针数组的index。
buf,保存环境变量的buffer,最大为UEVENT_BUFFER_SIZE。
buflen,访问buf的变量。
- 前面有提到过,在利用kmod向用户空间上报event事件时,会直接执行用户空间的可执行文件。而在Linux系统,可执行文件的执行,依赖于环境变量,因此kobj_uevent_env用于组织此次事件上报时的环境变量。
-
kset_uevent_ops
/* include/linux/kobject.h, line 123 */ struct kset_uevent_ops { int (* const filter)(struct kset *kset, struct kobject *kobj); const char *(* const name)(struct kset *kset, struct kobject *kobj); int (* const uevent)(struct kset *kset, struct kobject *kobj, struct kobj_uevent_env *env); };-
kset_uevent_ops是为kset量身订做的一个数据结构,里面包含filter和uevent两个回调函数,用处如下:
-
filter:当任何kobject需要上报uevent时,它所属的kset可以通过该接口过滤,阻止(过滤掉)不希望上报的event,从而达到从整体上管理的目的。
-
uevent:当任何kobject需要上报uevent时,它所属的kset可以通过该接口统一为这些event添加环境变量。因为很多时候上报uevent时的环境变量都是相同的,因此可以由kset统一处理,就不需要让每个kobject独自添加了。
-
name:该接口可以返回kset的名称。如果一个kset没有合法的名称,则其下的所有kobject将不允许上报uevent。
-
-
3.3 内部接口
-
通过
kobject.h,uevent模块提供了如下的API(这些API的实现是在lib/kobject\_uevent.c文件中):/* include/linux/kobject.h, line 206 */ int kobject_uevent(struct kobject *kobj, enum kobject_action action); int kobject_uevent_env(struct kobject *kobj, enum kobject_action action, char *envp[]); int add_uevent_var(struct kobj_uevent_env *env, const char *format, ...); int kobject_action_type(const char *buf, size_t count, enum kobject_action *type);
3.3.1 kobject_uevent_env
-
kobject_uevent_env函数以envp为环境变量,上报一个指定action的uevent。环境变量的作用是为执行用户空间程序指定运行环境。具体动作如下:- 查找kobj本身或者其parent是否从属于某个kset,如果不是,则报错返回(如果一个kobject没有加入kset,是不允许上报uevent的);
- 查看kobj->uevent_suppress是否设置,如果设置,则忽略所有的uevent上报并返回(可以通过kobject的uevent_suppress标志,管控kobject的uevent的上报);
- 如果所属的kset有
uevent_ops->filter函数,则调用该函数,过滤此次上报(kset可以通过filter接口过滤不希望上报的event,从而达到整体的管理效果); - 判断所属的kset是否有合法的名称(称作subsystem,和前期的内核版本有区别),否则不允许上报uevent;
- 分配一个用于此次上报的、存储环境变量的buffer(结果保存在env指针中),并获得该kobject在sysfs中的路径信息(用户空间软件需要依据该路径信息在sysfs中访问它);
- 调用add_uevent_var接口(下面会介绍),将action、路径信息、subsystem等信息,添加到env指针中;
- 如果传入的envp不空,则解析传入的环境变量,同样调用add_uevent_var接口,添加到env指针中;
- 如果所属的kset存在uevent_ops->uevent接口,调用该接口,添加kset统一的环境变量到env指针;
- 根据ACTION的类型,设置kobj->state_add_uevent_sent和kobj->state_remove_uevent_sent变量,以记录正确的状态;
- 调用add_uevent_var接口,添加格式为"SEQNUM=%llu”的序列号;
- 如果定义了"CONFIG_NET”,则使用netlink发送该uevent;
- 以uevent_helper、subsystem以及添加了标准环境变量(HOME=/,PATH=/sbin:/bin:/usr/sbin:/usr/bin)的env指针为参数,调用kmod模块提供的
call_usermodehelper函数,上报uevent。uevent_helper的内容是由内核配置项CONFIG_UEVENT_HELPER_PATH(位于./drivers/base/Kconfig)决定的(可参考lib/kobject_uevent.c, line 32),该配置项指定了一个用户空间程序(或者脚本),用于解析上报的uevent,例如"/sbin/hotplug”。call_usermodehelper的作用,就是fork一个进程,以uevent为参数,执行uevent_helper。
3.3.2 kobject_uevent
-
kobject_uevent,和kobject_uevent_env功能一样,只是没有指定任何的环境变量。int kobject_uevent(struct kobject *kobj, enum kobject_action action) { return kobject_uevent_env(kobj, action, NULL); }
3.3.3 add_uevent_var
add_uevent_var以格式化字符的形式(类似printf、printk等),将环境变量copy到env指针中。
3.3.4 kobject_action_type
-
kobject_action_type将enum kobject_action类型的action转换为字符串。 -
注意:怎么指定处理uevent的用户空间程序(简称uevent helper)?
-
上面介绍kobject_uevent_env的内部动作时,有提到,uevent模块通过Kmod上报uevent时,会通过call_usermodehelper函数,调用用户空间的可执行文件(或者脚本,简称*uevent helper* )处理该event。而该uevent helper的路径保存在**uevent_helper数组中。
-
可以在编译内核时,通过CONFIG_UEVENT_HELPER_PATH配置项,静态指定uevent helper。但这种方式会为每个event fork一个进程,随着内核支持的设备数量的增多,这种方式在系统启动时将会是致命的(可以导致内存溢出等)。因此只有在早期的内核版本中会使用这种方式,现在内核不再推荐使用该方式。因此内核编译时,需要把该配置项留空。
-
在系统启动后,大部分的设备已经ready,可以根据需要,重新指定一个uevent helper,以便检测系统运行过程中的热拔插事件。这可以通过把helper的路径写入到
/sys/kernel/uevent_helper文件中实现。实际上,内核通过sysfs文件系统的形式,将uevent_helper数组开放到用户空间,供用户空间程序修改访问,具体可参考./kernel/ksysfs.c中相应的代码,这里不再详细描述。
-
四、sysfs
1. 前言
sysfs是一个基于RAM的文件系统,它和kobject一起,可以将kernel的数据结构导出到用户空间,以文件目录结构的形式,提供对这些数据结构(以及数据结构的属性)的访问支持。sysfs是一种表示内核对象、对象属性,以及对象关系的一种机制,一般内核对象、属性、以及对象关系组织成树状形式。其中内核对象被映射为用户态的目录;对象属性被映射为用户态的文件,文件在目录下;对象关系被映射成用户空间的符号链接。
sysfs具备文件系统的所有属性,而本文主要侧重其设备模型的特性,因此不会涉及过多的文件系统实现细节,而只介绍sysfs在Linux设备模型中的作用和使用方法。具体包括:
- sysfs和kobject的关系
- attribute的概念
- sysfs的文件系统操作接口
2. sysfs和kobject的关系
在前面有提到过,每一个kobject,都会对应sysfs中的一个目录。因此在将kobject添加到kernel时,create_dir函数会调用sysfs文件系统的创建目录接口,创建和kobject对应的目录,相关的代码如下:
/* lib/kobject.c, line 47 */
static int create_dir(struct kobject *kobj)
{
int error = 0;
if (kobject_name(kobj)) {
error = sysfs_create_dir(kobj);
if (!error) {
error = populate_dir(kobj);
if (error)
sysfs_remove_dir(kobj);
}
}
return error;
}
- 这个函数接受唯一的一个参数,也就是要为其创建目录的kobject的地址。它完成如下操作:
- 检查传递进来kobject对象的name的有效性,若无效,则返回0。
- 若有效,则调用sysfs_create_dir(kobj)来在sysfs中创建目录。
/* fs/sysfs/dir.c, line 736 */
/*
* sysfs_create_dir - create a directory for an object.
*/
int sysfs_create_dir(struct kobject * kobj)
{
enum kobj_ns_type type;
struct sysfs_dirent *parent_sd, *sd;
const void *ns = NULL;
int error = 0;
BUG_ON(!kobj);
if (kobj->parent)
parent_sd = kobj->parent->sd;
else
parent_sd = &sysfs_root;
error = create_dir(kobj, parent_sd, kobject_name(kobj), &sd);
if (!error)
kobj->sd = sd;
return error;
}
- 这个函数首先会找到要为其创建目录的kobject的sysfs_dirent对象的父sysfs_dirent,通常是由父kobject的sd字段所指向。若父kobject为NULL,则设为sysfs根目录的sysfs_dirent。
- 然后调用create_dir(kobj, parent_sd, kobject_name(kobj) , &sd)来创建目录。
- 最后,若成功,设置kobject的sd字段指向为其新创建的sysfs_dirent,并返回0。若失败则返回错误码。
3. attribute
3.1 attribute的功能概述
在sysfs中,为什么会有attribute的概念呢?其实它是对应kobject而言的,指的是kobject的属性。我们知道,sysfs中的目录描述了kobject,而kobject是特定数据类型变量(如struct device)的体现。因此kobject的属性,就是这些变量的属性。它可以是任何东西,名称、一个内部变量、一个字符串等等。而attribute,在sysfs文件系统中是以文件的形式提供的,即:kobject的所有属性,都在它对应的sysfs目录下以文件的形式呈现。这些文件一般是可读写的,而kernel中定义了这些属性的模块,会根据用户空间的读写操作,记录和返回这些attribute的值。
总结一下:所谓的attibute,就是内核空间和用户空间进行信息交互的一种方法。例如某个驱动定义了一个变量,却希望用户空间程序可以修改该变量,以控制driver的运行行为,那么就可以将该变量以sysfs attribute的形式开放出来。
Linux内核中,attribute分为普通的attribute和二进制attribute,如下:
/* include/linux/sysfs.h, line 26 */
struct attribute
{
const char *name;
umode_t mode;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
bool ignore_lockdep:1;
struct lock_class_key *key;
struct lock_class_key skey;
#endif
};
/* include/linux/sysfs.h, line 100 */
struct bin_attribute {
struct attribute attr;
size_t size;
void *private;
ssize_t (*read)(struct file *, struct kobject *, struct bin_attribute *, char *, loff_t, size_t);
ssize_t (*write)(struct file *,struct kobject *, struct bin_attribute *, char *, loff_t, size_t);
int (*mmap)(struct file *, struct kobject *, struct bin_attribute *attr, struct vm_area_struct *vma);
};
struct attribute为普通的attribute,使用该attribute生成的sysfs文件,只能用字符串的形式读写(后面会说为什么)。而struct bin_attribute在struct attribute的基础上,增加了read、write等函数,因此它所生成的sysfs文件可以用任何方式读写。
说完基本概念,我们要问两个问题:
kernel怎么把attribute变成sysfs中的文件呢?
用户空间对sysfs的文件进行的读写操作,怎么传递给kernel呢?
下面来看看这个过程。
3.2 attibute文件的创建
在linux内核中,attibute文件的创建是由fs/sysfs/file.c中sysfs_create_file接口完成的,该接口的实现没有什么特殊之处,大多是文件系统相关的操作,和设备模型没有太多的关系,这里先略过不提。
3.3 attibute文件的read和write
看到3.1章节struct attribute的原型时,也许我们会犯嘀咕,该结构很简单啊,name表示文件名称,mode表示文件模式,其它的字段都是内核用于debug kernel Lock的,那文件操作的接口在哪里呢?
不着急,我们去fs/sysfs目录下看看sysfs相关的代码逻辑。
所有的文件系统,都会定义一个struct file_operations变量,用于描述本文件系统的操作接口,sysfs也不例外:
/* fs/sysfs/file.c, line 472 */
const struct file_operations sysfs_file_operations = {
.read = sysfs_read_file,
.write = sysfs_write_file,
.llseek = generic_file_llseek,
.open = sysfs_open_file,
.poll = sysfs_poll,
};
attribute文件的read操作,会由VFS转到sysfs_file_operations的read(也就是sysfs_read_file)接口上,让我们大概看一下该接口的处理逻辑。
/* fs/sysfs/file.c, line 127 */
static ssize_t sysfs_read_file(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
struct sysfs_buffer *buffer = file->private_data;
ssize_t retval = 0;
mutex_lock(&buffer->mutex);
if (buffer->needs_read_fill || *ppos == 0) {
retval = fill_read_buffer(file->f_path.dentry, buffer);
if (retval)
goto out;
}
...
}
/* fs/sysfs/file.c, line 67 */
static int fill_read_buffer(struct dentry * dentry, struct sysfs_buffer * buffer)
{
struct sysfs_dirent *attr_sd = dentry->d_fsdata;
struct kobject *kobj = attr_sd->s_parent->s_dir.kobj;
const struct sysfs_ops * ops = buffer->ops;
...
count = ops->show(kobj, attr_sd->s_attr.attr, buffer->page);
...
}
read处理看着很简单,sysfs_read_file从file指针中取一个私有指针,转换为一个struct sysfs_buffer类型的指针,以此为参数(buffer),转身就调用fill_read_buffer接口。而fill_read_buffer接口,直接从buffer指针中取出一个struct sysfs_ops指针,调用该指针的show函数,即完成了文件的read操作。
那么后续呢?当然是由ops->show接口接着处理咯。而具体怎么处理,就是其它模块(例如某个driver)的事了,sysfs不再关心(其实,Linux大多的核心代码,都是只提供架构和机制,具体的实现,也就是苦力,留给那些码农吧!这就是设计的魅力)。
不过还没完,这个struct sysfs_ops指针哪来的?好吧,我们再看看open(sysfs_open_file)接口吧。
/* fs/sysfs/file.c, line 326 */
static int sysfs_open_file(struct inode *inode, struct file *file)
{
struct sysfs_dirent *attr_sd = file->f_path.dentry->d_fsdata;
struct kobject *kobj = attr_sd->s_parent->s_dir.kobj;
struct sysfs_buffer *buffer;
const struct sysfs_ops *ops;
int error = -EACCES;
/* need attr_sd for attr and ops, its parent for kobj */
if (!sysfs_get_active(attr_sd))
return -ENODEV;
/* every kobject with an attribute needs a ktype assigned */
if (kobj->ktype && kobj->ktype->sysfs_ops)
ops = kobj->ktype->sysfs_ops;
else {
WARN(1, KERN_ERR "missing sysfs attribute operations for kobject: %s\n", kobject_name(kobj));
goto err_out;
}
...
buffer = kzalloc(sizeof(struct sysfs_buffer), GFP_KERNEL);
if (!buffer)
goto err_out;
mutex_init(&buffer->mutex);
buffer->needs_read_fill = 1;
buffer->ops = ops;
file->private_data = buffer;
...
}
原来和ktype有关系。这个指针是从该attribute所从属的kobject中拿的。再去看一下ktype的定义,里面有一个struct sysfs_ops的指针。
注意:通过注释“every kobject with an attribute needs a ktype assigned”以及其后代码逻辑可知,如果从属的kobject(就是attribute文件所在的目录)没有ktype,或者没有ktype->sysfs_ops指针,是不允许它注册任何attribute的!
经过确认后,sysfs_open_file从ktype中取出struct sysfs_ops指针,并在随后的代码逻辑中,分配一个struct sysfs_buffer类型的指针(buffer),并把struct sysfs_ops指针保存在其中,随后把buffer指针交给file的private_data,随后read/write等接口便可以取出使用。这是内核中的常用方法!
顺便看一下struct sysfs_ops吧,我想你已经能够猜到了。
/* include/linux/sysfs.h, line 124 */
struct sysfs_ops {
ssize_t (*show)(struct kobject *, struct attribute *,char *);
ssize_t (*store)(struct kobject *,struct attribute *,const char *, size_t);
const void *(*namespace)(struct kobject *, const struct attribute *);
};
attribute文件的write过程和read类似,这里就不再多说。另外,上面只分析了普通attribute的逻辑,而二进制类型的呢?也类似,去看看fs/sysfs/bin.c吧,这里也不说了。
讲到这里,应该已经结束了,事实却不是如此。上面read/write的数据流,只到kobject(也就是目录)级别哦,而真正需要操作的是attribute(文件)啊!这中间一定还有一层转换!确实,不过又交给其它模块了。 下面我们通过一个例子,来说明如何转换的。
4. sysfs在设备模型中的应用总结
让我们通过设备模型class.c中有关sysfs的实现,来总结一下sysfs的应用方式。
首先,在class.c中,定义了class所需的ktype以及sysfs_ops类型的变量,如下:
/* drivers/base/class.c, line 86 */
static const struct sysfs_ops class_sysfs_ops = {
.show = class_attr_show,
.store = class_attr_store,
.namespace = class_attr_namespace,
};
static struct kobj_type class_ktype = {
.sysfs_ops = &class_sysfs_ops,
.release = class_release,
.child_ns_type = class_child_ns_type,
};
由前面章节的描述可知,所有class_type的kobject下面的attribute文件的读写操作,都会交给class_attr_show和class_attr_store两个接口处理。以class_attr_show为例:
/* drivers/base/class.c, line 24 */
#define to_class_attr(_attr) container_of(_attr, struct class_attribute, attr)
static ssize_t class_attr_show(struct kobject *kobj, struct attribute *attr, char *buf)
{
struct class_attribute *class_attr = to_class_attr(attr);
struct subsys_private *cp = to_subsys_private(kobj);
ssize_t ret = -EIO;
if (class_attr->show)
ret = class_attr->show(cp->class, class_attr, buf);
return ret;
}
该接口使用container_of从struct attribute类型的指针中取得一个class模块的自定义指针:struct class_attribute,该指针中包含了class模块自身的show和store接口。下面是struct class_attribute的声明:
/* include/linux/device.h, line 399 */
struct class_attribute {
struct attribute attr;
ssize_t (*show)(struct class *class, struct class_attribute *attr,char *buf);
ssize_t (*store)(struct class *class, struct class_attribute *attr, const char *buf, size_t count);
const void *(*namespace)(struct class *class, const struct class_attribute *attr);
};
因此,所有需要使用attribute的模块,都不会直接定义struct attribute变量,而是通过一个自定义的数据结构,该数据结构的一个成员是struct attribute类型的变量,并提供show和store回调函数。然后在该模块ktype所对应的struct sysfs_ops变量中,实现该本模块整体的show和store函数,并在被调用时,转接到自定义数据结构(struct class_attribute)中的show和store函数中。这样,每个atrribute文件,实际上对应到一个自定义数据结构变量中了。
- 【参考资料】

















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











