









工作流我放文末,需要的自取!
一张真人照片,一张动漫图片,ComfyUI工作流让你轻松实现角色转换。

大家好,今天我们要分享一个令人兴奋的话题——如何使用ComfyUI工作流,将你喜爱的动漫角色转化为逼真的真人形象。这不仅是一个技术教程,更是一次创意的飞跃,让我们一起探索动漫与现实交汇的奇妙世界。
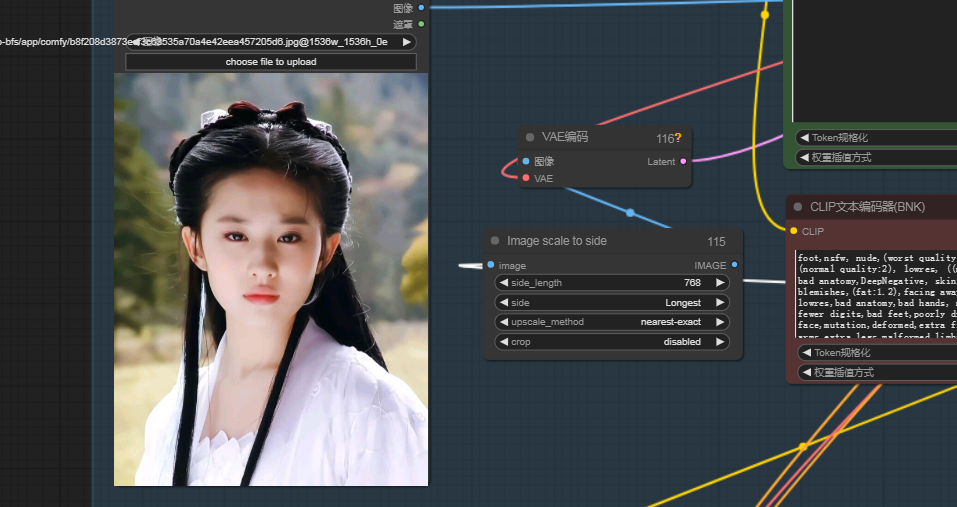
一、ComfyUI工作流简介
ComfyUI是一个基于节点的图形用户界面,专为Stable Diffusion设计,它通过链接不同的节点来构建复杂的图像生成工作流程。今天,我们将使用ComfyUI工作流中的一系列特定节点,完成从动漫到真人的图像转换。
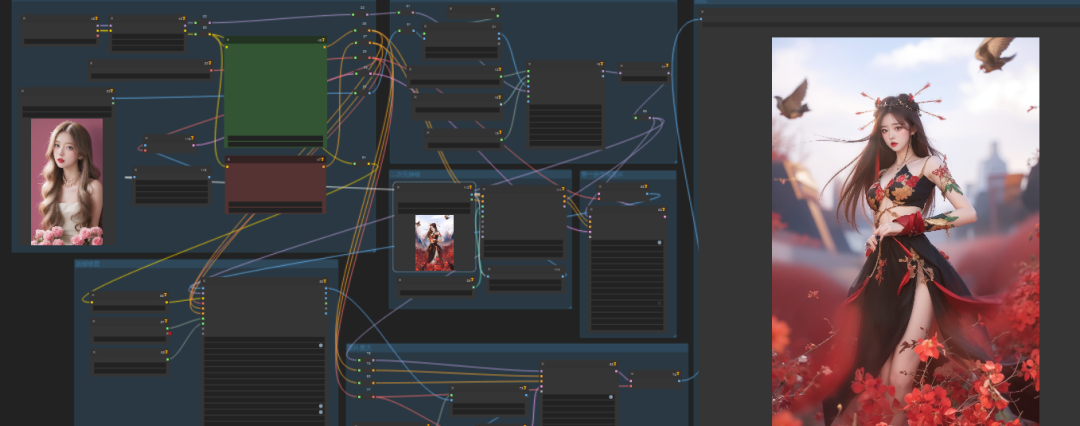
二、所需材料
- 一张真人照片
- 一张动漫角色图片
三、核心节点介绍
- Primitive Nodes:基础节点,包括视频线性配置指导、Lora模型加载、VAE编解码等,它们是构建工作流的基础。
- Custom Nodes:自定义节点,如
wlsh_nodes、ComfyUI_IPAdapter_plus等,它们提供了额外的功能和定制化选项。 - Checkpoints:检查点,例如
majicMIX realistic/v7,用于确保生成的图像具有高度的真实感。 - Loras:特定风格或特征的加载,如
Miao girl costume/v1.0,为角色增添独特的魅力。 - Unknown Nodes:未知节点,如
DF_Image_scale_to_side,可能用于图像尺寸调整或其他未知功能。
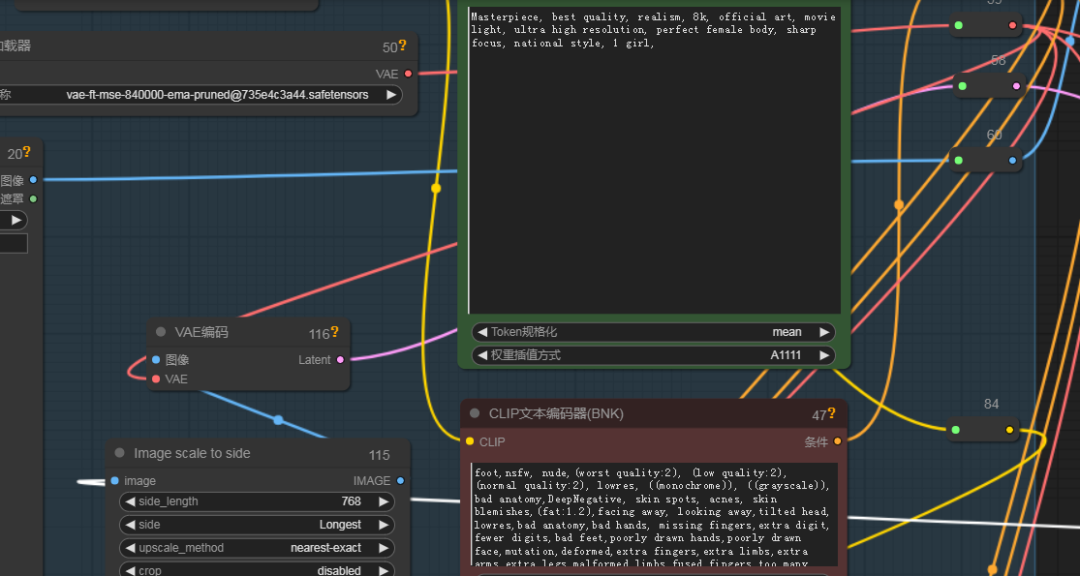
四、操作步骤
- 加载图像:使用
LoadImage节点加载你的真人照片和动漫图片。 - 风格提取:通过
VAEEncode和VAEDecode节点提取动漫图片的风格特征。 - 角色转换:利用
CharacterFaceSwap节点将动漫角色的脸转换到真人照片上。 - 细节修复:使用
ComfyUI-Advanced-ControlNet节点对转换后的角色进行细节调整。 - 图像放大:通过
UpscaleModelLoader节点对图像进行高质量放大,确保最终输出的清晰度。 - 保存成果:最后,使用
SaveImage节点保存你的无实物Cosplay作品。
**
**
通过ComfyUI工作流,我们不仅能够实现动漫角色到真人形象的转换,还能够在这个过程中体验到创意和技术的完美结合。无论你是Cosplay爱好者,还是数字艺术家,ComfyUI都能为你的创作之旅增添无限可能。



关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









