







样本不均衡导致分类结果较差的本质原因
样本不均衡包括样本类别不均衡和样本难易程度不均衡,样本不均衡导致的分类效果较差本质上是样本难易程度不均衡导致的[^1]。
对本质原因的个人理解
个人理解,如果一个样本集中的所有样本都能够被一个模型非常容易的进行分类,即使样本不同类别的数量差距较大,模型也能够达到比较好的分类效果。
1、人眼(可以看做一个模型)去区分鲸鱼和狗两种动物,由于两个类别的样本差别较大,人眼(模型)非常容易进行区分,即使鲸鱼样本集中包括99990个鲸鱼样本,狗样本集中包括10个样本,人眼(模型)分类的准确率也会达到100%。
2、相反,在区分饼干和狗的例子中,由于饼干和狗特别相似,即使饼干样本集和狗样本集同样都包含1000个样本,则人眼(模型)也会存在很多误判。
(图片引用自网络)

解决方法
网上多处资料(参考:https://www.sohu.com/a/306064501_500659)已指出:样本集中包含大量容易分类的简单样本,容易分类的简单样本对模型参数的更新贡献较小,但是当大量简单样本产生的loss叠加时,就会对模型产生主导作用,个人理解是在网络的训练过程中,参数更新是由样本产生的loss反向传播得到的,而整个样本集产生的loss主要是由大量简单样本叠加产生的,因此说大量简单样本对模型占据了主导作用。
容易分类的简单样本对模型参数更新贡献较小,不容易分类的样本对模型参数的更新贡献较大,模型参数的更新又是由损失函数值决定的,因此相关文献在损失函数的角度提出了相关解决方案。网络中已存在许多详细的介绍(https://www.sohu.com/a/306064501_500659、http://www.pianshen.com/article/7435282398/)在这里只对其进行一点简单的总结和记录一下自己对解决方案中某些内容的理解,方便日后回顾。
1、OHEM-LOSS
在OHEM算法中,使用两个网络进行困难样本挖掘,首先第一个网络用于计算样本损失,将损失较大的样本作为第二个网络的输入,经过后续计算得到损失函数值进行反向传播,其中第一个网络只是用于样本筛选,这种算法只使用了困难样本进行训练,忽略了简单样本的分布。
2、FOCAL-LOSS
focal-loss在交叉熵损失函数的基础上进行修改,在交叉熵损失函数中添加前置项,公式如下(引用自网络)
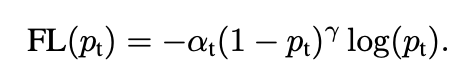
其中pt为一个样本正确分类的概率,γ,α为人为设定的超参数,
假设γ的值为2:
1)针对简单样本而言,当一个样本的正确分类的额概率为0.9时,focal-loss会将该样本的损失函数值缩小为标准交叉熵损失的0.01倍。
2)但是针对复杂样本,一个样本的预测概率为0.5时,focal-loss会将该样本的损失函数值缩小为标准交叉熵损失函数的0.25倍,相比之下,抑制了简单样本对于损失函数的贡献。
3)针对更复杂的样本,正确分类概率为0.1时,focal-loss会将该样本的损失函数缩小为标准交叉熵损失函数的0.81倍
总结:该方法的目的在于抑制容易分类的简单样本对于损失函数的贡献,加强不容易分类的复杂样本对损失函数值得贡献,即模型参数更新主要是由复杂样本造成,加强模型对不容易分类样本的分类能力。
3、GHM-C LOSS
FOCAL-LOSS从损失函数的角度抑制简单样本对模型参数更新的贡献,加强复杂样本对模型参数更新的贡献,GHM则进一步的在梯度更新的角度来缓解样本不平衡问题。
1)梯度模长
GHM首先定义了梯度模长的概念,梯度模长即为损失函数值对参数的偏导值得绝对值,公式如下图
(图片引用自网络)
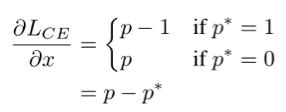
2)梯度模长分布统计
通过统计样本梯度模长的长度分布,发现绝大部分的梯度模长都非常小,即绝大多数样本的类别预测概率与实际标签值非常接近,也就代表了绝大部分样本是非常容易进行分类的,然而还有一部分样本的梯度模长非常大,这部分样本为异常数据。
(图片引用自网络)

为了均衡各个难易程度的样本对模型梯度更新的贡献,研究者提出了梯度均衡机制,对每个难易程度的样本产生的梯度进行加权,从而实现均衡的目的。由于梯度值是由损失函数值反向传播得到的,因此将加权值加在模型的损失函数中(个人针对不直接加在梯度中的原因比较小白的理解是:在实际开发过程中,将加权值加在损失函数中会相对比较容易实现,如果直接加在梯度中需要修改框架的部分源码,这种理解不知道对不对)。
3)梯度密度
将梯度模长取值范围划分为若干个区域,某区域内的样本数除以区域长度即为梯度密度,例如梯度模长取值范围为[0,1],将其划分为3个区域,[0,0.3],[0.4,0.7],[0.8,1.0],其中[0,0.3]区域内的样本数为30,则该区域内的密度为30/0.3=100。
由于样本的梯度密度是训练时根据 batch 计算出来的,通常情况下 batch 较小,直接计算出来的梯度密度可能不稳定,所以采用滑动平均的方式处理梯度计算。(具体公式目前也看不懂。。。。。。)
(图片引用自网络)

4)梯度均衡
梯度均衡的方法是,将某样本计算得到的loss值与该样本的梯度密度的倒数相乘,即梯度密度的倒数为损失函数的权值,
个人对其均衡的原因理解如下:
(1)针对梯度模长较小的样本区域。假设梯度模长为[0,0.1]的区域内有1000个样本,并且每个样本产生的损失函数值平均为0.2,则梯度密度为1000/0.1 = 10000,这1000个样本的损失函数值加权值为0.21000/10000=0.02,即均衡之后的梯度值为0.02,均衡之前的梯度值为0.21000=200
(2)针对梯度模长较大的样本区域。假设梯度模长为[0.5,0.7]的区域内有300个样本,每个样本产生的损失函数值平均为0.4,则梯度密度为300/0.2=1500,这300个样本的损失函数值的加权值为0.2*300/1500=0.04,均衡之前的梯度值为60。
均衡之后相比于均衡之前二者之间的差距和比例会相对较小,困难举的数字不太合适,算出来的结果比较奇怪。。。。。。
5)梯度密度乘样本数量
(图片引用自网络)
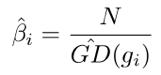
梯度密度乘样本数量的原因是为了避免梯度模长只划分一个区域长度时,损失函数值不变。如果不乘样本数量N的话,损失函数值会缩小为原来的1/N倍
疑惑:不是只划分一个单位区域时,损失函数乘以权重,同样也会缩小损失函数值,为什么只划分一个单位区域时就要避免损失函数缩小了呢???
6)得到GHM-C LOSS
在标准交叉熵损失函数的基础上进行修改得到GHM-C LOSS,其中LCE为标准交叉熵损失函数,βi为梯度密度的倒数
(图片引用自网络)
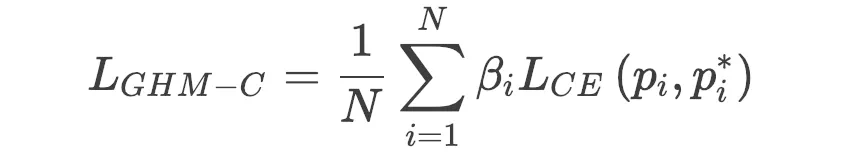
参考:
[1]Gradient Harmonized Single-stage Detector
[2]:https://www.chainnews.com/articles/050135711210.htm
[3]:https://www.sohu.com/a/306064501_500659
[4]:https://www.jiqizhixin.com/articles/2019-02-12-20















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









