







 本文探讨了在处理类别不平衡数据时使用SMOTE(合成少数类过采样技术)算法进行数据增强的效果。通过实验发现,随着正类数据的增加,模型准确率下降而召回率上升,这可能是由于增强过程中引入的噪声导致模型将更多数据错误地分类为正类。这种现象提示我们在应用数据增强时需要注意平衡模型的精度与召回率。
本文探讨了在处理类别不平衡数据时使用SMOTE(合成少数类过采样技术)算法进行数据增强的效果。通过实验发现,随着正类数据的增加,模型准确率下降而召回率上升,这可能是由于增强过程中引入的噪声导致模型将更多数据错误地分类为正类。这种现象提示我们在应用数据增强时需要注意平衡模型的精度与召回率。
最近在看数据增强相关的内容,看到smote算法比较流行,具体原理和代码实现可以参考:数据分析:使用Imblearn处理不平衡数据(过采样、欠采样),正好有一份类别不平衡的数据集,正负类数据量分别为3W和50W,想要使用smote算法对正类数据进行增强看一下实际效果,具体实验结果如下:
1、原始数据结果:
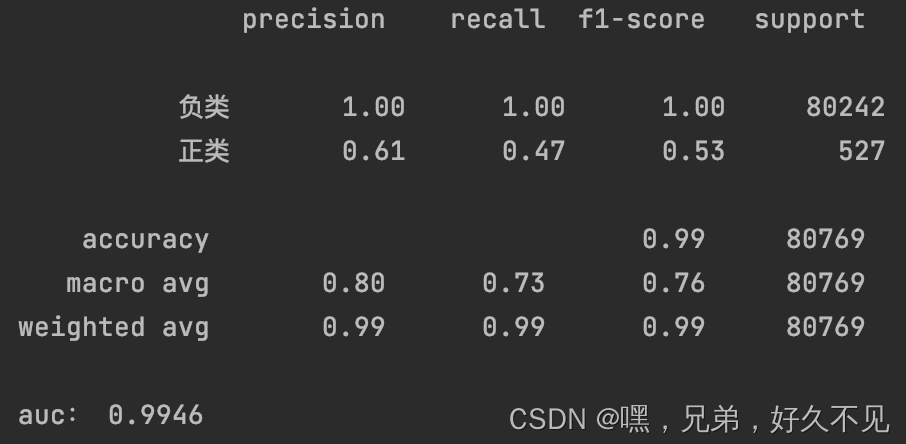
2、正类数据增强1W条
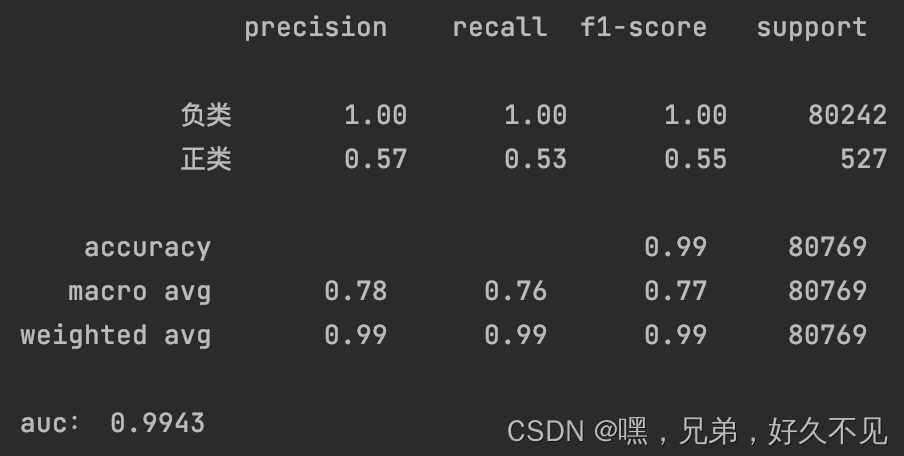
3、正类数据增加一倍即3W条
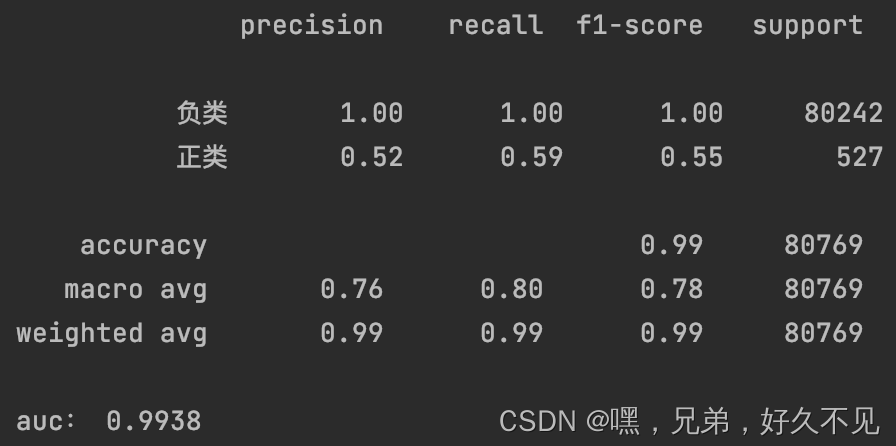
4、正类数据增加5W条
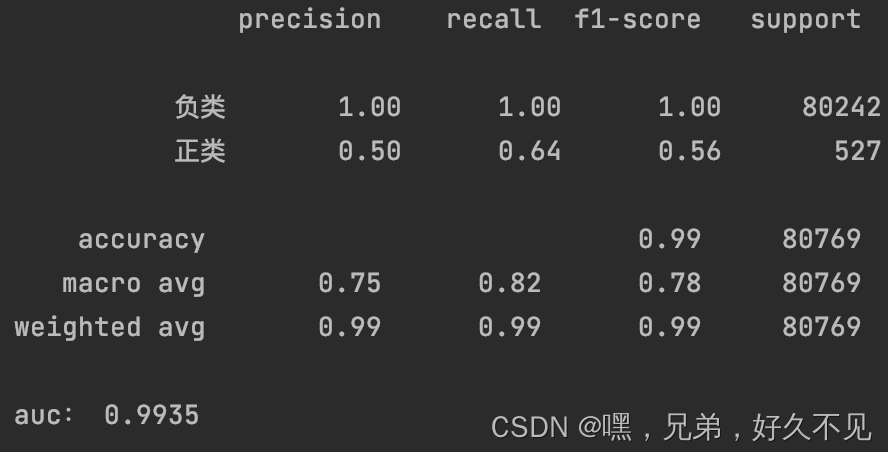
5、增加至正负类比例为1:1
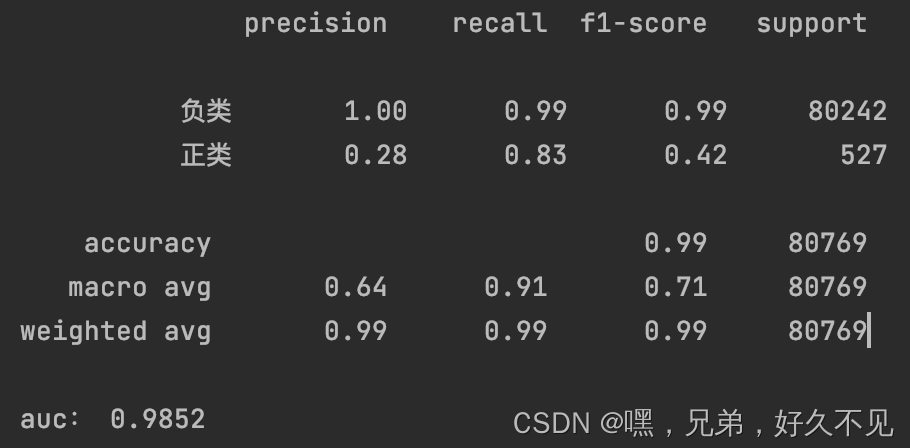
经过几次实验发现增强的数据量越多,正类的准确率降低、召回率提升,个人理解是数据增强的过程中引入了噪声,也就是增强的正类数据并不是真正的正类数据,在训练的过程中模型会将负类数据也认为是正类数据,从而在预测的时候将更多的数据预测为正类,最终出现准确率降低、召回率提升的现象。

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









