









回顾:极大似然估计
考虑一个随机变量
X
,只能取1和2两个值中的1个,我们现在要对这个随机变量进行描述。现在已知这个随机变量服从两点分布,也就是
用表格表示,就是
XP1μ12μ2
这里的 μ1 和 μ2 都是两点分布模型的 参数,这两个参数描述了随机变量 X 的特性。
我们每对
我们进行
现在我们真正地进行 n 次采样,首先得到的是一串有顺序的类似于“11222212111”的数字,也就是我们的样本集,忽略其中的1和2的顺序,可以得到一个计数向量
P(x1=n1)=Cn1nμn11(1−μ1)n−n1
注意,上式表示的是观测结果发生的概率,但是由于参数 μ1 未知,它现在是一个关于 μ1 的函数(其他量都已知),这个函数叫做似然函数(这里是离散的形式)。
极大似然估计的思路就是,找到一个 μ1 ,使得似然函数的值最大(也就是使得观测结果发生的概率最大),这样的 μ1 就是我们的极大似然估计的结果。具体这里的做法十分简单,让似然函数对参数 μ1 求导,然后令导函数为0,即可得到 μ1 的估计值
μ1^=n1n
带隐含变量的情况
现在考虑如下模型(例子来自《统计学习方法》):假设有三枚硬币,分别记作
A、B和C
,这些硬币正面出现的概率分别是
π、p和q
。进行如下掷硬币实验:先掷硬币
A
,但是不记录结果,然后根据结果来决定是掷硬币
1,1,0,1,0,0,1,0,1,1
假设只能观测到掷硬币的结果,现在我们来估计三硬币正面出现的概率,也就是三硬币模型的所有三个参数。
我们用 y 表示观测变量,它只能取0或者1;用
三硬币模型中 y 的分布可以写作
将观测数据表示为 Y=(Y1,Y2,⋯,Yn)T ,隐含的变量的取值表示为 Z=(Z1,Z2,⋯,Zn)T ,则观测数据的似然函数为
P(Y∣θ)=∑zP(Z∣θ)P(Y∣Z,θ)
即
P(Y∣θ)=∏j=1n[πpyj(1−p)1−yj+(1−π)qyj(1−q)1−yj]
考虑求模型参数 θ=(π,p,q) 的极大似然估计,即
θ^=argmaxθlogP(Y∣θ)
由于对数函数里面有求和符号,这时候让似然函数对参数求偏导然后令偏导数为零是不可行的,这时候就需要用EM算法了。
下面直接给出针对以上问题的EM算法。EM算法首先选取参数的初值(有时候会随机选初值),我们把初值记作 θ(0)=(π(0),p(0),q(0)) ,然后通过下面的步骤迭代计算参数的估计值,直到收敛到局部最优解,这个局部最优解使得似然函数的值极大。第 i 次迭代参数的估计值为
E步:计算在模型参数 θ(i) 下观测数据 yj 来自硬币B的概率
μ(i+1)j=π(i)(p(i))yj(1−p(i))1−yjπ(i)(p(i))yj(1−p(i))1−yj+(1−π(i))(q(i))yj(1−q(i))1−yj
M步:计算模型参数的新估计值
π(i+1)=1n∑j=1nμ(i+1)jp(i+1)=∑nj=1μ(i+1)jyj∑nj=1μ(i+1)jq(i+1)=∑nj=1(1−μ(i+1)j)yj∑nj=1(1−μ(i+1)j)
不断重复E步和M步,就可以得到参数的一组局部最优解。其实上面的E步和M步都是很好理解的,在E步的时候,我们已知模型的参数以及观测值,求隐含变量的分布变得很容易;而在M步的时候,我们已知模型的隐含变量的分布,于是这时候问题变成了普通的极大似然估计问题(即相当于没有隐含变量),于是求出一组新的参数也十分容易。
因此,现在我们对于EM算法可以有一个感性的理解:由于隐含变量的存在,我们没有办法直接对似然函数最大化。但是如果知道了隐含变量的分布,我们可以很方便地对参数进行估计;如果知道了参数的值,我们可以很方便地求出隐含变量的分布。于是就可以不断迭代求出参数的局部最优值,只是最开始的时候,参数需要一个初始值。
从一个维度理解EM算法的原理
现在我从一个维度说说EM算法的原理(公式来自PRML这本书)。首先,约定一些符号的意义。
X
表示观测变量,
我们的目标是求
θ
的极大似然估计值,即
θ^=argmaxθlnp(X∣θ)
而 lnp(X∣θ)=ln∑Zp(X,Z∣θ) ,由于对数里面带有求和符号,无法直接对似然函数极大化,因此要考虑曲线救国。
如果定义隐含变量的分布为 q(Z) ,则
lnp(X∣θ)=∑Zq(Z)lnp(X∣θ)=∑Zq(Z)lnp(X,Z∣θ)p(Z∣X,θ)=∑Zq(Z)lnp(X,Z∣θ)q(Z)p(Z∣X,θ)q(Z)=∑Zq(Z)lnp(X,Z∣θ)q(Z)−∑Zq(Z)lnp(Z∣X,θ)q(Z)(1)
我们记
L(q,θ)KL(q∣∣p)==∑Zq(Z)lnp(X,Z∣θ)q(Z)−∑Zq(Z)lnp(Z∣X,θ)q(Z)(2)(3)
其中 L(q,θ) 是 q(Z) 的泛函形式, KL(q∣∣p) 是 q(Z) 和 p(Z∣X,θ) 的 KL 散度, KL 散度在这里就不做具体介绍了,它是一个衡量两个分布相似程度的函数,两个分布越相似,它就越趋向于0,但是它始终大于等于0,当且仅当两个分布完全相同时,它等于0。
观察 (1) 可知,想找一组 θ 使得左边最大,我们可以找一组 θ 使得右边最大,即使得 (2) 和 (3) 的和最大。
这时候,考虑如果 θ 已知会发生什么。如果 θ=θ(i) 已知,则 p(X,Z∣θ(i)) 和 p(Z∣X,θ(i)) 都已知,则 (2) 和 (3) 完全由 q(Z) 决定。现在我们选择 q(Z)=p(Z∣X,θ(i)) ,于是
KL(q∣∣p)lnp(X∣θ(i))=0=L(q,θ(i))=∑Zq(Z)lnp(X,Z∣θ(i))q(Z)(4)
注意,此时的 θ=θ(i) ,而且 q(Z)=p(Z∣X,θ(i)) ,于是 (4) 的两边其实都是确定的值。这时候,如果我们变动 (4) 中 p(X,Z∣θ(i)) 的 θ ,则 (4) 的两边会随着变动,这时候我们找到 θ=θ(i+1) ,使得 (4) 右边极大,即 (4) 的右边现在其实等于
∑Zq(Z)lnp(X,Z∣θ(i+1))q(Z)=∑Zp(Z∣X,θ(i))lnp(X,Z∣θ(i+1))p(Z∣X,θ(i))
但是 θ 一变动, (3) 中的 p(Z∣X,θ) 就会变动,此时 p(Z∣X,θ(i+1)) 和 q(Z)=p(Z∣X,θ(i)) 不再相等,于是 KL(q∣∣p) 不再为0, (4) 不再成立,我们需要找到一个新的 q(Z)=p(X,Z∣θ(i+1)) 。
总体来说,流程大概就是这样:确定 θ 以后,找合适的 q(Z) 使得 (3) 为0,然后更新 θ 使得 (1) 的右边极大化,但是 (1) 的右边极大化的同时, (1) 的左边比它增长得更快,因为此时 (3) 不再为0了,于是我们要基于当前的 θ 重新找一组合适的 q(Z) 。
下面来说明如何由当前的 q(Z) 更新 θ 的值:
L(q,θ)=∑Zq(Z)lnp(X,Z∣θ)q(Z)=∑Zp(Z∣X,θ(i))lnp(X,Z∣θ)p(Z∣X,θ(i))=∑Zp(Z∣X,θ(i))lnp(X,Z∣θ)−∑Zp(Z∣X,θ(i))lnp(Z∣X,θ(i))=∑Zp(Z∣X,θ(i))lnp(X,Z∣θ)−const(5)
(5) 右边的第一项就是 Z 对于全数据分布的期望,也就是
θ(i+1)=argmaxθEZ[lnp(X,Z∣θ)]
所以,EM算法的E和M两步的名称就很好理解了,E步就是由 θ(i) 求隐含变量 Z 的分布,由
下面这张图来自PRML这本书,它形象展示了EM算法:
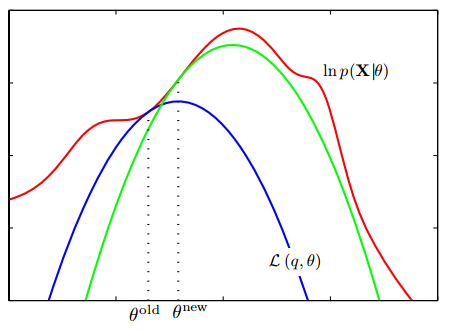
图中红色的函数就是原似然函数 lnp(X∣θ) ,而蓝色的函数就是 L(q,θ) ,我们对 L(q,θ) 极大化了以后(即找到一组 θnew ),原似然函数 lnp(X∣θ) 比它增长更快,于是我们不得不再找一个新的 L(q,θ) ,对新的函数极大化,最后直到收敛到 lnp(X∣θ) 的局部极大值。















 7210
7210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









