







 本文探讨如何通过Prompt压缩技术减少RAG(检索增强生成)的成本。介绍了AutoCompressors、选择性背景压缩和LongLLMLingua等方法,强调LongLLMLingua在保持信息准确性的同时,能有效压缩输入tokens,从而显著降低推理成本。
本文探讨如何通过Prompt压缩技术减少RAG(检索增强生成)的成本。介绍了AutoCompressors、选择性背景压缩和LongLLMLingua等方法,强调LongLLMLingua在保持信息准确性的同时,能有效压缩输入tokens,从而显著降低推理成本。
原文地址:How to Cut RAG Costs by 80% Using Prompt Compression
通过即时压缩加速推理
2024 年 1 月 5 日
推理过程是使用大型语言模型时消耗资金和时间成本的因素之一,对于较长的输入,这个问题会更加凸显。下面,您可以看到模型性能与推理时间之间的关系。
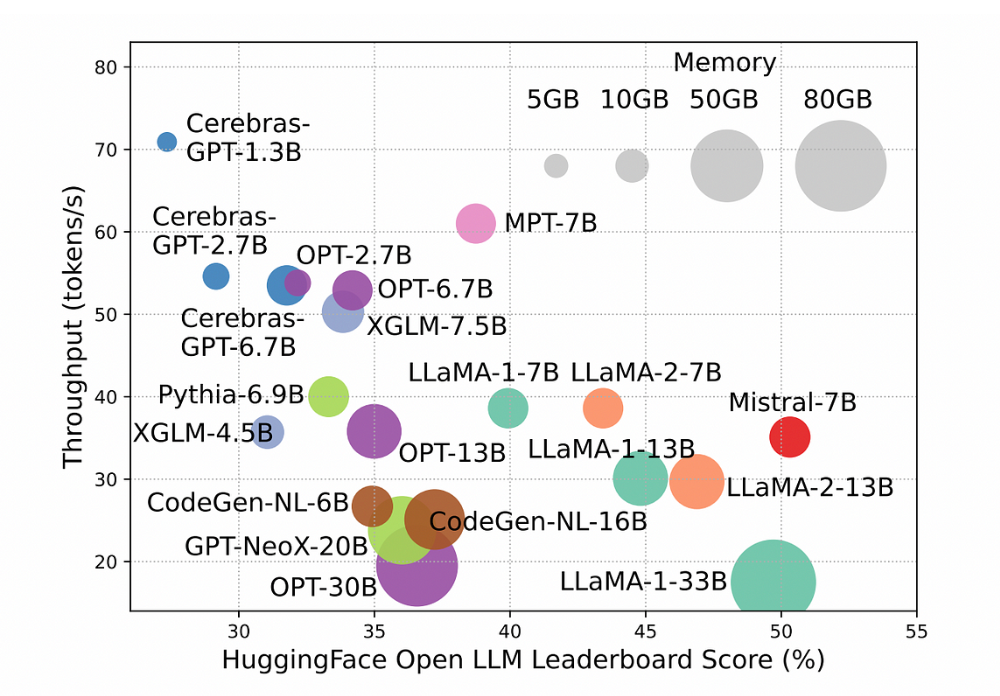
性能得分与推理吞吐量[1]
小型模型每秒生成更多的tokens,往往在Open LLM排行榜上得分较低。增加模型参数大小可以提高性能,但会降低推理吞吐量。这使得在实际应用中部署它们变得困难[1]。提高LLMs的速度并减少资源需求将使其能够更广泛地被个人或小型组织使用。
对于提高LLM的效率,目前大家提出了不同的解决方案来,有些人会关注模型架构或系统。然而,像ChatGPT或Claude这样的专有模型只能通过API访问,因此我们无法改变它们的内部算法。
本文我们将讨论一种简单且廉价的方法,该方法仅依赖于改变输入给模型的方式—即prompt压缩。
首先,让我们澄清LLMs如何理解语言。理解自然语言文本的第一步是将其分割成片段。这个过程被称为tokenization(标记化)。一个token可以是一个完整的单词,一个音节,或者是当前口语中经常使用的字符序列。

分词示例。图片由作者提供。
作为一个经验法则,tokens的数量通常比单词的数量高出33%。因此,1000个单词大约对应1333个tokens。让我们具体看一下OpenAI gpt-3.5-turbo模型的定价,因为这是我们将来要使用的模型。

OpenAI定价[3]
我们可以看到,推理过程对输入tokens(对应发送给模型的提示)和输出tokens(模型生成的文本)都有成本。
输入tokens消耗最多资源的应用之一是检索增强生成。输入甚至可以达到数千个tokens。在检索增强生成中,用户查询被发送到一个向量数据库,从中检索出最相似的信息,并与查询一起发送到LLM。在向量数据库中,我们可以添加模型在初始训练中未见过的个人文档。
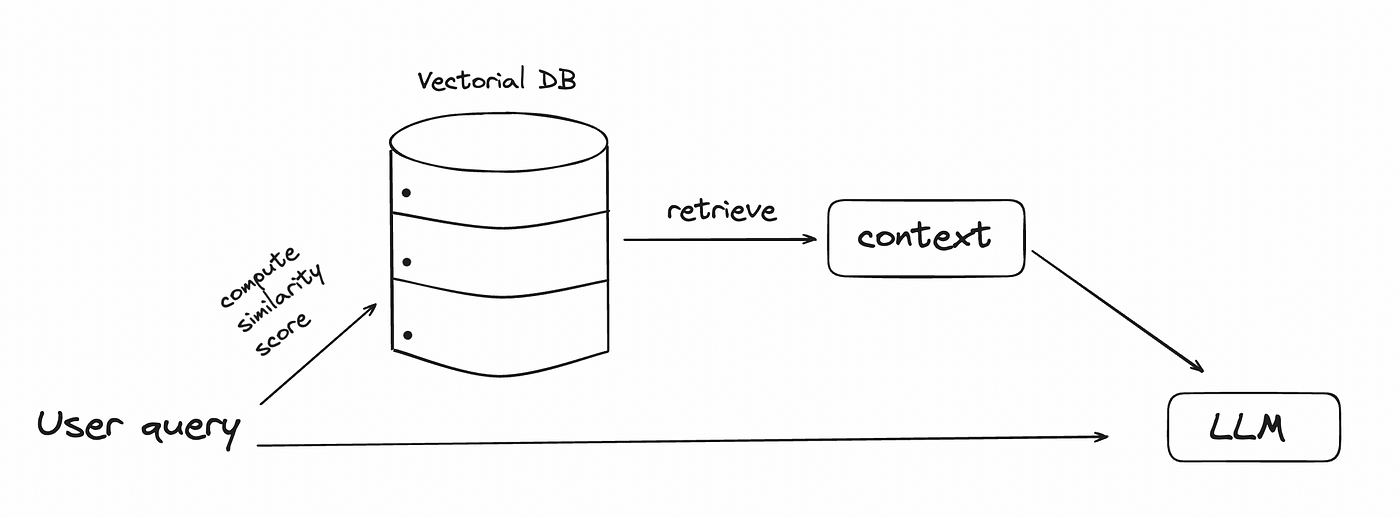
RAG流程图。作者提供的图片。
发送到LLM的tokens数量可能会很大,这取决于从数据库中检索到多少文本块。
Prompt 压缩
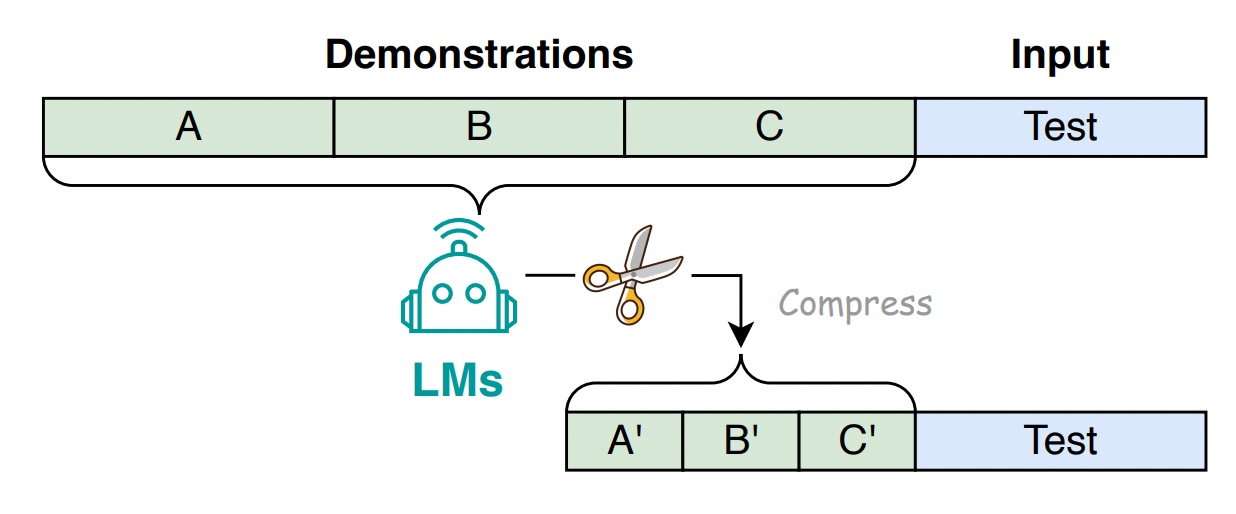
提示压缩的插图[1]
Prompt压缩可以缩短原始提示,同时保留最重要的信息。它还可以加快语言模型处理输入的速度,帮助生成快速准确的答案。
这种技术利用了语言中常常包含不必要的重复。研究表明,英语在段落或章节长度的文本中有很多冗余,大约占75% [2]。这意味着大部分单词可以从它们前面的单词中预测出来。
自动压缩机(AutoCompressors)
我们将要讨论的第一种压缩方法是AutoCompressors。它通过将长文本总结为称为摘要向量的短向量表示来工作。这些压缩的摘要向量然后作为模型的软提示。
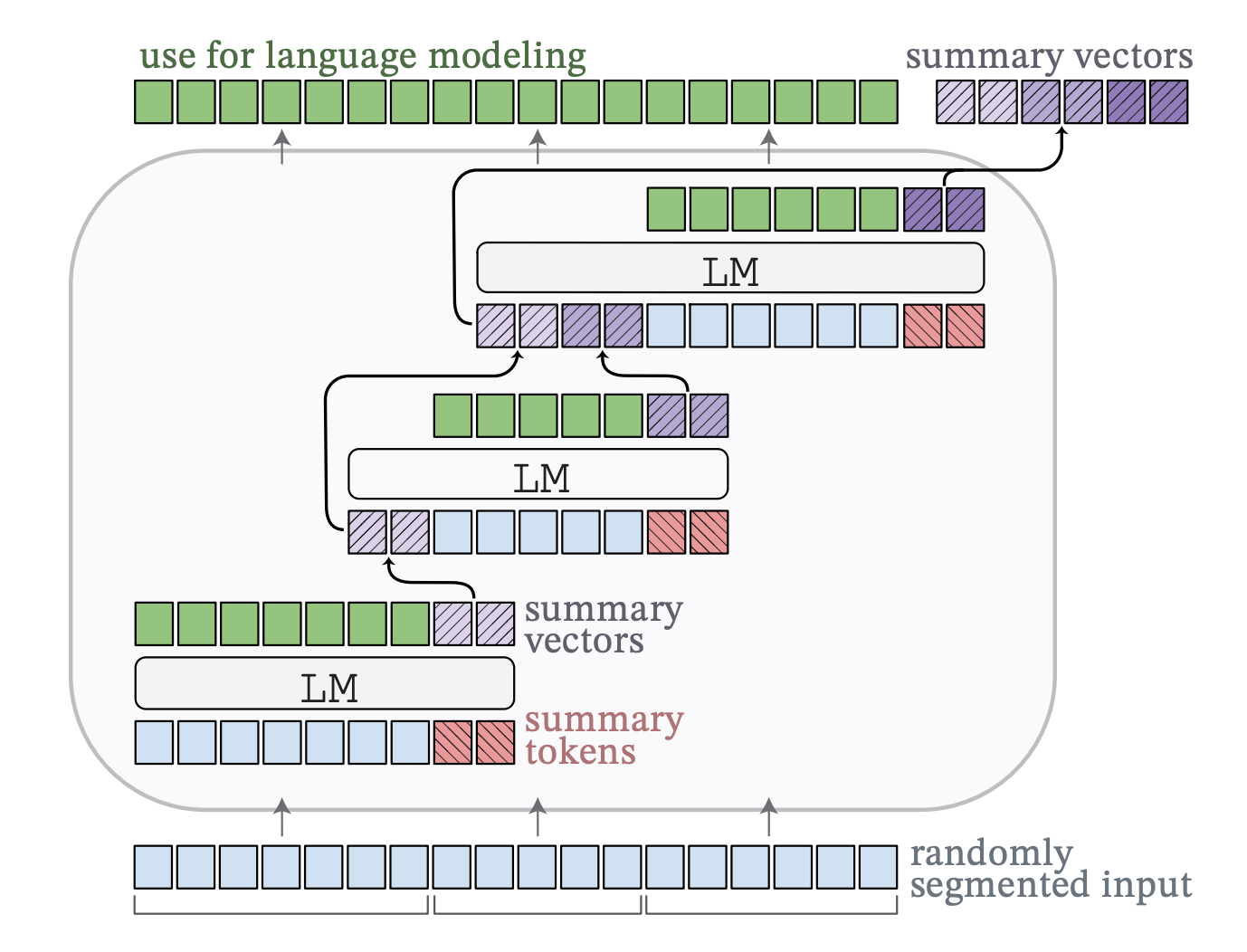
自动压缩机流量[4]
在软提示期间,预训练模型保持冻结状态,并在每个特定任务的输入文本开头添加了少量可训练的标记。这些标记不是固定的,而是通过训练学习得到的。它们在整个模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









