







数据
该数据集包含2,507篇研究论文标题,并已手动分类为5个类别(即会议)。
探索与预处理
import torch
from tqdm.notebook import tqdm
from transformers import BertTokenizer
from torch.utils.data import TensorDataset
from transformers import BertForSequenceClassification
df = pd.read_csv('data/title_conference.csv')
df.head()

df['Conference'].value_counts()

您可能已经注意到我们的类别不平衡,我们将在稍后解决这个问题。
对标签进行编码
possible_labels = df.Conference.unique()
label_dict = {}
for index, possible_label in enumerate(possible_labels):
label_dict[possible_label] = index
label_dict
![]()
df['label'] = df.Conference.replace(label_dict)
训练和验证集划分
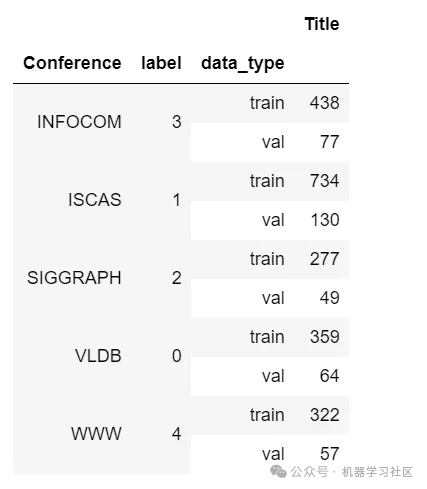
由于标签不平衡,我们以分层的方式划分数据集,使用这个作为类别标签。
在划分后,我们的标签分布将如下所示。
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(df.index.values,
df.label.values,
test_size=0.15,
random_state=42,
stratify=df.label.values)
df['data_type'] = ['not_set']*df.shape[0]
df.loc[X_train, 'data_type'] = 'train'
df.loc[X_val, 'data_type'] = 'val'
df.groupby(['Conference', 'label', 'data_type']).count()
BertTokenizer 和数据编码
标记化是将原始文本拆分为标记的过程,这些标记是表示单词的数字数据。
-
我们构建一个基于WordPiece的BERT标记器。
-
实例化一个预训练的BERT模型配置来编码我们的数据。
-
为了将所有标题从文本转换为编码形式,我们使用一个名为batch_encode_plus的函数,并且我们将分别处理训练和验证数据。
-
上述函数中的第一个参数是标题文本。
-
add_special_tokens=True意味着序列将被编码为相对于它们的模型的特殊标记。
-
当将序列批处理在一起时,我们设置return_attention_mask=True,这样它将根据max_length属性定义的特定标记器返回注意力掩码。
-
我们还希望将所有标题填充到特定的最大长度。
-
实际上,我们不需要设置max_length=256,只是为了谨慎起见。
-
return_tensors='pt' 用于返回PyTorch张量。
-
然后,我们需要将数据分成input_ids、attention_masks和labels。
-
最后,在获取编码数据集后,我们可以创建训练数据和验证数据。
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased',
do_lower_case=True)
encoded_data_train = tokenizer.batch_encode_plus(
df[df.data_type=='train'].Title.values,
add_special_tokens=True,
return_attention_mask=True,
pad_to_max_length=True,
max_length=256,
return_tensors='pt'
)
encoded_data_val = tokenizer.batch_encode_plus(
df[df.data_type=='val'].Title.values,
add_special_tokens=True,
return_attention_mask=True,
pad_to_max_length=True,
max_length=256,
return_tensors='pt'
)
input_ids_train = encoded_data_train['input_ids']
attention_masks_train = encoded_data_train['attention_mask']
labels_train = torch.tensor(df[df.data_type=='train'].label.values)
input_ids_val = encoded_data_val['input_ids']
attention_masks_val = encoded_data_val['attention_mask']
labels_val = torch.tensor(df[df.data_type=='val'].label.values)
dataset_train = TensorDataset(input_ids_train, attention_masks_train, labels_train)
dataset_val = TensorDataset(input_ids_val, attention_masks_val, labels_val)
BERT预训练模型
我们将每个标题视为其独特的序列,因此一个序列将被分类到五个标签中的一个(即会议)。
-
bert-base-uncased是一个较小的预训练模型。
-
使用num_labels来指示输出标签的数量。
-
我们实际上不关心output_attentions。
-
我们也不需要output_hidden_states。
model = BertForSequenceClassification.from_pretrained("bert-base-uncased",num_labels=len(label_dict),output_attentions=False,output_hidden_states=False)
数据加载器
数据加载器结合了数据集和采样器,并提供对给定数据集的可迭代方式。
我们在训练中使用RandomSampler,而在验证中使用SequentialSampler。
考虑到我的环境内存有限,我将batch_size设置为3。
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
batch_size = 3
dataloader_train = DataLoader(dataset_train, sampler=RandomSampler(dataset_train), batch_size=batch_size)
dataloader_validation = DataLoader(dataset_val, sampler=SequentialSampler(dataset_val), batch_size=batch_size)
优化器和调度器
要构建一个优化器,我们必须给它一个包含要优化的参数的可迭代对象。然后,我们可以指定特定于优化器的选项,如学习率、epsilon等。
我发现对于这个数据集,epochs=5效果很好。
创建一个调度器,其中学习率从优化器中设置的初始学习率线性减小到0,在一个热身期之后,在热身期内,学习率从0线性增加到优化器中设置的初始学习率。
from transformers import AdamW, get_linear_schedule_with_warmup
optimizer = AdamW(model.parameters(),lr=1e-5, eps=1e-8)
epochs = 5
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0,num_training_steps=len(dataloader_train)*epochs)
性能指标
我们将使用每个类别的F1分数和准确率作为性能指标。
from sklearn.metrics import f1_score
def f1_score_func(preds, labels):
preds_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return f1_score(labels_flat, preds_flat, average='weighted')
def accuracy_per_class(preds, labels):
label_dict_inverse = {v: k for k, v in label_dict.items()}
preds_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
for label in np.unique(labels_flat):
y_preds = preds_flat[labels_flat==label]
y_true = labels_flat[labels_flat==label]
print(f'Class: {label_dict_inverse[label]}')
print(f'Accuracy: {len(y_preds[y_preds==label])}/{len(y_true)}\n')
训练循环
import random
seed_val = 17
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
def evaluate(dataloader_val):
model.eval()
loss_val_total = 0
predictions, true_vals = [], []
for batch in dataloader_val:
batch = tuple(b.to(device) for b in batch)
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'labels': batch[2],
}
with torch.no_grad():
outputs = model(**inputs)
loss = outputs[0]
logits = outputs[1]
loss_val_total += loss.item()
logits = logits.detach().cpu().numpy()
label_ids = inputs['labels'].cpu().numpy()
predictions.append(logits)
true_vals.append(label_ids)
loss_val_avg = loss_val_total/len(dataloader_val)
predictions = np.concatenate(predictions, axis=0)
true_vals = np.concatenate(true_vals, axis=0)
return loss_val_avg, predictions, true_vals
for epoch in tqdm(range(1, epochs+1)):
model.train()
loss_train_total = 0
progress_bar = tqdm(dataloader_train, desc='Epoch {:1d}'.format(epoch), leave=False, disable=False)
for batch in progress_bar:
model.zero_grad()
batch = tuple(b.to(device) for b in batch)
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'labels': batch[2],
}
outputs = model(**inputs)
loss = outputs[0]
loss_train_total += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
progress_bar.set_postfix({'training_loss': '{:.3f}'.format(loss.item()/len(batch))})
torch.save(model.state_dict(), f'data_volume/finetuned_BERT_epoch_{epoch}.model')
tqdm.write(f'\nEpoch {epoch}')
loss_train_avg = loss_train_total/len(dataloader_train)
tqdm.write(f'Training loss: {loss_train_avg}')
val_loss, predictions, true_vals = evaluate(dataloader_validation)
val_f1 = f1_score_func(predictions, true_vals)
tqdm.write(f'Validation loss: {val_loss}')
tqdm.write(f'F1 Score (Weighted): {val_f1}')

加载和评估模型
model = BertForSequenceClassification.from_pretrained("bert-base-uncased",
num_labels=len(label_dict),
output_attentions=False,
output_hidden_states=False)
model.to(device)
model.load_state_dict(torch.load('data_volume/finetuned_BERT_epoch_1.model', map_location=torch.device('cpu')))
_, predictions, true_vals = evaluate(dataloader_validation)
accuracy_per_class(predictions, true_vals)















 4195
4195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









