







论文地址:https://arxiv.org/abs/2402.18679
Github:MetaGPT: The Multi-Agent Framework
数据解释器(Data Interpreter)是一个基于大型语言模型(LLM)的代理,专门为解决数据科学问题而设计。它通过代码来解决数据科学中的挑战,特别是在需要实时数据调整、复杂任务间依赖关系的优化以及识别逻辑错误的精确推理方面表现出色。数据解释器采用了三种关键技术来增强数据科学问题解决能力:
- 1. 动态规划与层次图结构:利用层次图结构来实时适应数据变化,动态规划方法使得数据解释器能够适应任务变化,特别是在监控数据变化和管理数据科学问题中固有的复杂变量依赖关系方面表现出高效性。
- 2. 工具集成与动态增强:在执行过程中动态集成各种人类编写的代码片段,创建特定任务的自定义工具,超越了仅依赖API的现有能力。这一过程涉及自动组合多种工具与自生成的代码,利用任务级执行来独立构建和扩展其工具库,简化工具使用,并根据需要进行代码重构。
- 3. 逻辑不一致性识别与经验记录提升效率:基于执行结果获得的置信分数,检测代码解决方案与测试代码执行之间的不一致性,并通过比较多次尝试来减少逻辑错误。在整个执行和推理过程中,记录任务级经验,主要包括元数据和运行轨迹,包括成功和失败的经验。
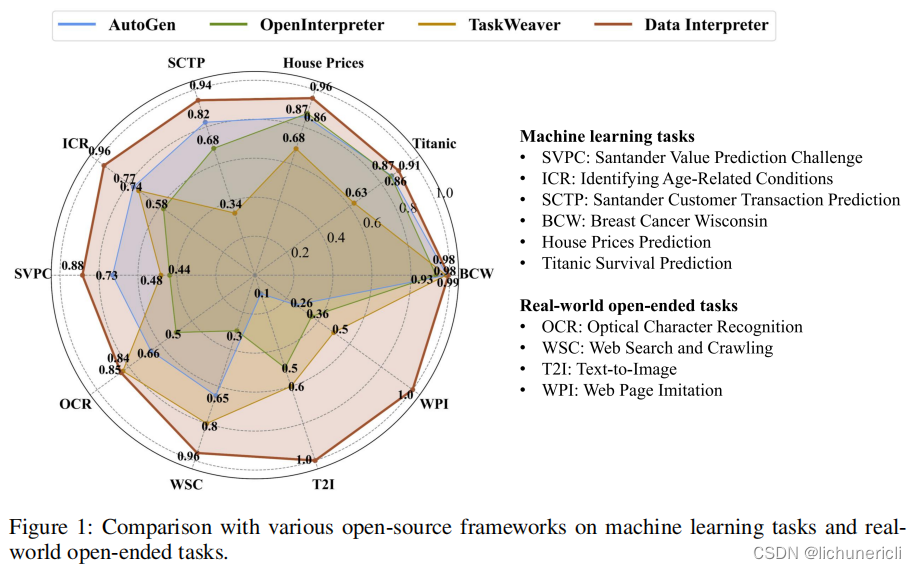
数据解释器在各种数据科学和现实世界任务上进行了评估,与开源基线相比,显示出优越的性能,在机器学习任务中表现显著提升,从0.86提高到0.95。此外,它在MATH数据集上显示出26%的增长,在开放式任务中更是显著提升了112%。该解决方案将在GitHub上发布,地址为:https://github.com/geekan/MetaGPT。
摘要(Abstract)
基于大型语言模型(LLM)的代理在多个领域展现出了显著的有效性。然而,它们在需要实时数据调整、由于各种任务间复杂依赖性所需的优化专业知识,以及识别逻辑错误以进行精确推理的数据科学场景中的性能可能会受到影响。
在本研究中,我们介绍了数据解释器(Data Interpreter),这是一个旨在通过代码解决数据科学问题的解决方案,强调了三种关键技术来增强问题解决能力:
- 1)动态规划与层次图结构,用于实时数据适应性;
- 2)动态集成工具以增强执行期间的代码熟练度,丰富所需的专业知识;
- 3)在反馈中识别逻辑不一致性,并通过经验记录提高效率。
我们在各种数据科学和现实世界任务上评估了数据解释器。与开源基线相比,它展示了卓越的性能,在机器学习任务中表现出显著的改进,从0.86提高到0.95。此外,它在MATH数据集上显示出26%的增长,在开放式任务中更是显著提升了112%。解决方案将在Github上发布。
引言(Introduction)
大型语言模型(LLMs)使代理在广泛的应用中表现出色,展示了它们的适应性和有效性。这些由LLM驱动的代理显著影响了软件工程、导航复杂开放世界场景、促进多模态任务的协作多代理结构、提高虚拟助手的响应性、优化群体智能,并为科学研究做出贡献。
最近的研究集中在通过改进它们的推理过程来提高这些代理的问题解决能力,旨在提高复杂性和效率。然而,包括机器学习、数据分析和数学问题解决在内的数据为中心的科学问题,提出了一些独特的挑战,这些挑战仍有待解决。机器学习过程涉及复杂的、漫长的任务处理步骤,其特点是多个任务之间的复杂依赖关系。这需要专家介入进行过程优化和在失败或数据更新的情况下进行动态调整。对于LLM来说,一次性提供正确的解决方案往往是具有挑战性的。
在当前的数据科学领域,有一种方法是通过编写代码来解决以数据为核心的问题,这种方法被称为解释器范式。它结合了对需求的静态分析和代码的实际执行。尽管这种方法有其优势,但在实际的数据科学应用中,它也暴露出了一些重要的挑战:
1)数据依赖强度:数据科学固有的复杂性源于各个步骤之间的复杂相互作用,这些步骤可能会实时变化。为了获得准确的结果,在开发任何机器学习模型之前,数据清洗和全面的特工程是前提条件。因此,监控数据变化并动态调整转换后的数据和变量至关重要。机器学习建模过程,包括特征选择、模型训练和评估,涉及广泛的处理操作符和搜索空间。挑战在于同时生成和解决整个过程代码。
2)精细的领域知识:数据科学家的专业知识和编码实践在解决数据相关挑战中至关重要。通常嵌入在专有代码和数据中,这些知识对当前的LLM来说往往是不可访问的。例如,为特定领域(如能源或地质学)生成数据转换代码可能对没有所需领域专业知识的LLM构成挑战。现有的方法主要依赖于LLM,这种依赖可能会简化流程,但可能会牺牲性能。
3)严格的逻辑要求:解释器通过代码执行和错误捕获能力来增强问题解决性能。然而,它们往往忽略了无错误的执行,错误地将其视为正确的。虽然基本编程任务可以通过即时执行反馈来简化,并且当要求明确界定时依赖于即时执行反馈,但数据科学问题往往提出了模糊、不规则和定义不明确的要求,这使得LLM难以理解。因此,LLM生成的代码解决方案可能包含需要严格验证逻辑正确性的模糊性,这超出了单纯的执行反馈。
相关工作(Related Work)
作为数据科学
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5537
5537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









