







30Wqps 闲鱼优惠中台架构
优惠券业务的场景分析
优惠券业务,在大量的场景中,会有使用。在我们日常生活中,常常会遇到下面这样的场景:优惠券业务是一种促销方式,通常由商家向消费者提供的折扣或者特价优惠,在推广和销售产品时具有重要的作用。
优惠券业务主要使用场景分析
场景1:电商平台
在电商平台上,商家可以通过发布优惠券来吸引更多用户购买商品,从而提高销售额。比如,在双十一或者618等大促销活动中,商家会发布各种优惠券,包括满减券、折扣券、免邮券等等,以达到促销的目的。
场景2:实体店铺
实体店铺也可以通过发放优惠券来吸引更多顾客到店消费。比如,在超市或者餐厅中,可以提供满减券、折扣券、赠品券等等,让消费者享受到更多的实惠,从而增加消费频次和消费金额。
场景3:O2O平台
在O2O平台中,商家可以通过发放优惠券来吸引用户使用其服务。比如,在外卖平台上,商家可以发布满减券、新用户专属券等等,以吸引更多的用户尝试其服务;在打车平台上,也可以发布优惠券来吸引用户使用其服务。
场景4:品牌推广
品牌推广也是优惠券业务的一个重要场景。比如,在新品上市或者品牌促销活动中,可以通过发放折扣券或者礼品券等等,来吸引更多用户尝试品牌产品或者服务,提高品牌知名度和美誉度。总之,优惠券业务在各个行业中都有广泛的应用,可以帮助商家提高销售额、增加用户粘性和忠诚度,同时也能为消费者提供更多的实惠和福利。
优惠券场景的业务迭代
如何提升优惠券的引流能力。答案是:设计一个个性化的优惠券系统,为不同的粉丝群体,设置不同的优惠券价格。
为了设计一个个性化的优惠券系统,闲鱼团队需要考虑以下几个方面:
粉丝群体分类
首先,需要将粉丝群体进行分类,比如按照年龄、性别、地域、消费习惯等等进行分类。这样可以更好地理解不同群体的需求和行为特征,有针对性地推出不同的优惠券。
优惠券类型
其次,需要确定不同的优惠券类型,比如满减券、折扣券、免单券等等。根据不同的群体需求,设置不同的优惠力度和使用条件,例如对于高消费群体,可以设置更高额度的满减券或者更高折扣力度的折扣券。
优惠券价格
最后,需要考虑不同粉丝群体的经济实力和消费能力,合理设置优惠券价格。例如,对于大学生群体,可以设置较低的价格,以吸引他们尝试新产品或服务;而对于高收入群体,则可以设置更高的价格,以提升产品或服务的价值感。
优惠券的迭代分析
除此之外,可以通过数据分析的方式,不断优化和调整优惠券系统,以达到更好的促销效果和用户满意度。同时,还需要注意保障优惠券系统的安全性和有效性,例如设置使用期限、使用限制等措施,避免滥用和恶意操作。
闲鱼的个性化优惠场景
闲鱼是一款二手交易平台APP,主要面向年轻用户群体。以下是闲鱼APP的用户分析:
年龄分布
闲鱼APP的主要用户群体年龄在18-35岁之间,其中以25-30岁的用户占比最高。这个年龄段的用户更注重物品的性价比和实用性,同时也更善于使用互联网和移动设备进行购物。
性别分布
相比于其他二手交易平台APP,闲鱼APP的用户男女比例较为接近,女性用户占比略高。这也反映出闲鱼APP对女性用户的吸引力较大,可能与其简单易用、社区氛围浓厚等特点有关。
地域分布
闲鱼APP的用户主要集中在一二线城市,尤以杭州、上海、北京等城市为主。这些城市的用户更注重生活品质和消费体验,对于二手商品的需求也更为广泛和多样化。
用户行为特征
闲鱼APP的用户通常具有以下几个行为特征:爱好交友、追求个性化、注重环保节能等等。他们不仅使用闲鱼APP进行二手交易,还会通过闲鱼社区分享生活经验、交流兴趣爱好等,形成了一种类似于社交媒体的共享氛围。
用户需求和偏好
闲鱼APP的用户需求和偏好主要集中在以下几个方面:时尚潮流、个性化定制、品质保障等。他们通常会在闲鱼APP上寻找一些独特而实用的物品,包括衣物、配饰、家居用品等等,同时也关注卖家的信誉度和商品质量。
总闲鱼APP的用户具有年轻、多样化、社交化等特点,商家可以根据这些特点进行针对性的营销策略和产品服务优化,提高用户满意度和购买转化率。
在闲鱼上,针对闲鱼交易中的 粉丝群体,提供了 专门的 优 策略,针对 粉丝购买和粉丝回购的优惠促销场景,提供了一种定向的/个性化的优惠价:

-
卖家可以按商品分别面向全部粉丝、老粉、已购粉设置不同的优惠价格。
-
买家在导购、下单等场景可以实时看到自己能够享受的最低优惠价格。
虽然闲鱼没有使用优惠券的概念,使用的优惠价格。 但是和 个性化的优惠券,本质是一样的。所以,闲鱼的优惠中台的架构,对大家做 个性化的优惠券中台的架构,具有巨大的借鉴的架构。
海量用户场景问题与挑战
闲鱼APP的DAU,注册用户数2.5个亿,日活跃用户数(DAU)为2900万左右。吞吐量峰值至少在30Wqps+。
这么大的 海量用户场景, 在 优惠券计算、优惠券展示的过程中,存在巨大的技术难题:
-
难题1:如何描述、存储和计算优惠,提供较好的业务可扩展性?
-
难题2:如何保障大流量下,优惠实时计算的性能?
-
难题3:为优惠查询加速做的数据同步,如何实现一致性?
闲鱼的个性化优惠中台的技术演进
闲鱼的个性化优中台的技术演进, 分为三个阶段来实现:
-
阶段1:分解优惠的基本要素,实现优惠的基本表达和计算;
-
阶段2:对优惠对象的判定过程进行抽象和加速
为了保障大流量下的优惠查询下性能和业务的可扩展性,对优惠对象的判定过程进行抽象和加速;
-
阶段3:在优惠对象制备的过程中,通过离线+实时的方式同步数据,保障数据一致性。
阶段1:分解优惠的基本要素,实现优惠的基本表达和计算
分解优惠的基本要素
一个优惠主要描述了“谁对哪个商品享受什么优惠”,拆解为三个要素就是:
【优惠对象】+【优惠商品】+【优惠价格】。
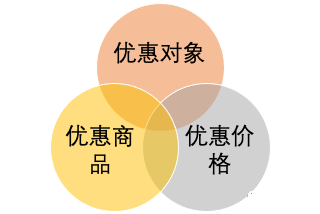
在粉丝优惠的场景下,优惠对象是指卖家的粉丝、卖家的已购粉丝等,优惠对象 如何存储呢?
一个卖家的粉丝,可以被描述为“卖家ID_all_fans”的符号 。一个卖家的已购用户,可以被描述为“卖家ID_buy_fans” 的符号 。
这样闲鱼团队可以得到一个优惠规则的描述大致如下:
【卖家A_all_fans】+【商品1234】+【18.88元】
对应的业务语义是:
卖家A的所有粉丝,对于(卖家A的)商品1234,可以以18.88元的优惠价格。
实现优惠的基本表达和计算的三个步骤
以这条优惠为例,当买家B访问商品1234时,闲鱼团队会执行这样的一个过程:
第一步:根据商品,查询优惠规则
查询商品1234上的优惠规则,发现一条【卖家A_all_fans】+【商品1234】+【18.88元】的规则;
第二步:分析 优惠对象的语义
分析【卖家A_all_fans】表达的含义,表示的是卖家A的全部粉丝可以享受优惠;
第三步:根据规则的语义,计算当前用户的优惠价格
确定买家B是否是卖家A的粉丝,如果是,则以18.88元的价格展示优惠或者成交。
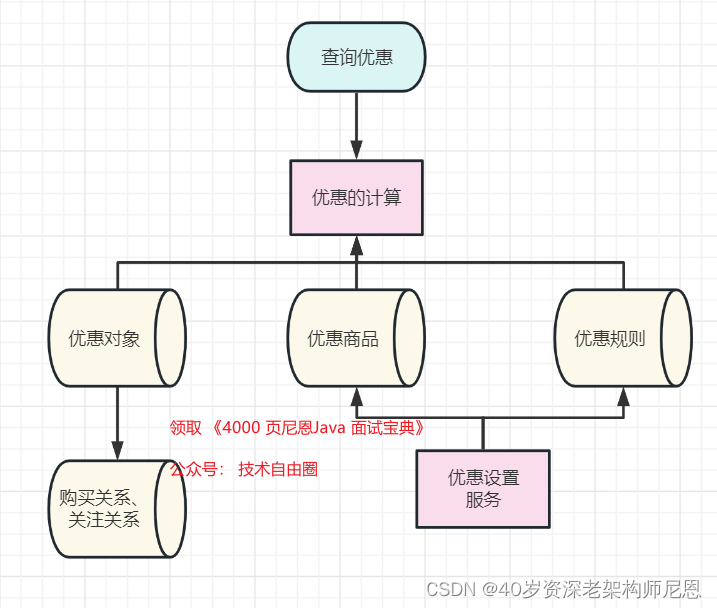
闲鱼的优惠中台的架构1.0版本
为了实现了优惠设置和计算的能力,闲鱼的优惠中台的架构1.0版本,大致如下:
阶段2:对优惠对象的判定过程进行抽象和加速
闲鱼的优惠中台的架构1.0版本存在两个问题
-
问题1:优惠对象语义分析,可扩展性差
优惠计算过程需要解析【优惠对象】这个符号背后所包含的业务语义,再由系统进行判断买家是否符合条件,随着业务规则的升级,系统的会变的非常复杂,可扩展性差。
-
问题2:太多的RPC调用,性能差
每一次优惠查询,都需要访问用户的关注关系、购买关系,这整个查询过程非常长,性能低下,当面对大流量时,系统会陷入瘫痪。
对优惠对象的计算进行抽取和解耦
为了解决这两个问题,闲鱼希望优惠计算过程不再需要理解【优惠对象】的语义,判定过程中也不要再去查询各个业务系统。
闲鱼团队发现,优惠对象的判定过程都是在回答“用户是否属于某个群体”,于是,可以将这个关系进行抽象,提前制备并存储起来。
常见的技术手段中,表达一个用户是否属于某个群体有两种实现:
-
在用户对象上打上一个标记。
-
创建一个“人群”对象,将用户关联到人群。
一般情况下,第一种方式使用于群体较少可枚举的情况,第二种方案适用于群体较多的情况。在闲鱼的实现中,使用了第二种方案。
具体的措施是, 抽取出一个新的 实体:人群 ,并且提前进行 异步计算。
闲鱼将用于描述优惠对象的符号(例如“卖家A_all_fans”)作为人群的名称去定义一个人群。按照这个规则,平台为每个卖家的不同分组各定义这样一个人群。
闲鱼定义了人群的概念,并提供了一种实现人群的技术方案,这个架构中,人群在同时充当了“协议”和“缓存”的作用。
人群和用户的关系,如何存储呢?
方案一:可以通过redis string 实现,设计一个类似:${user_A} ${crowd_B} 的key写入redis。
在查询时,查询 ${user_A} ${crowd_B} 这个key是否存在,就可以判定user_A是否属于crowd_B。
方案二:可以通过redis set 实现,设计一个类似 ${crowd_B} 的key写入redis, 然后把 ${user_A} 的用户加入到set 。
在查询时,查询 ${crowd_B},是否在 ${user_A} 的集合中,就可以判定user_A是否属于crowd_B。
当然,上面仅仅是参考的案例,闲鱼设计中需要根据数据特性进行优化。
闲鱼的优惠中台的架构2.0版本
这时闲鱼的得到的整体架构是这样的:
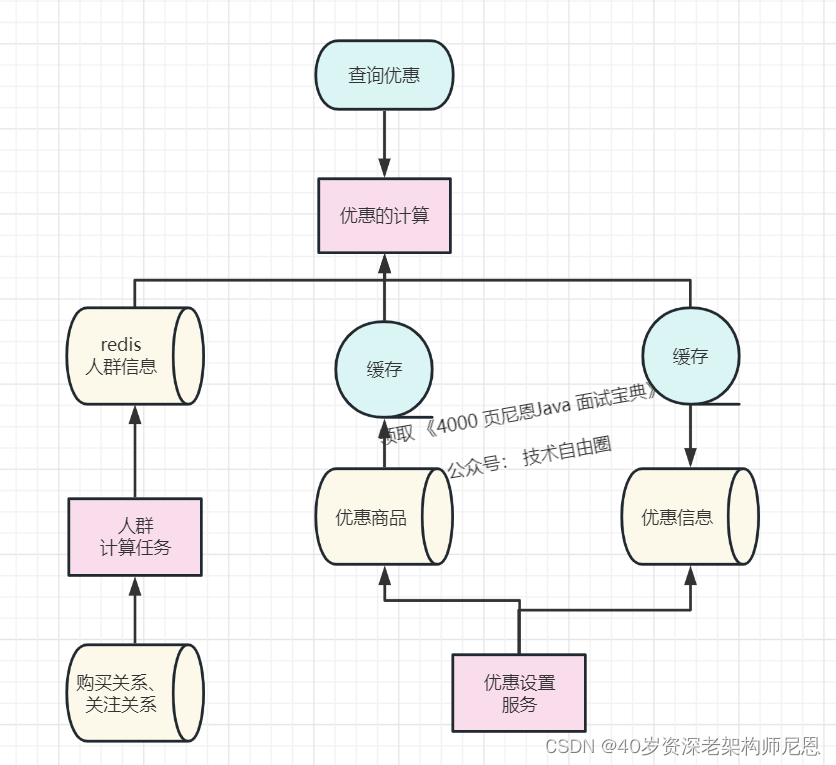
在上面的架构中,顺带缓存了一下优惠数据 。事实上,在闲鱼基于中台的解决方案中,从一开始面临的就是这样的架构(实际中台的架构比这个会更复杂一些)。如果尝试从头演进了这个系统,也得到这样的一个方案。从一定程度来说,这也是架构的必然性 。
具体来说,当我们从业务的可扩展性、系统的性能角度从头进行推演的时候,我们发现最终会回到类似的架构上来。
可以说,在特定的业务规模下,架构的演进有它历史的必然性。
阶段3:在优惠对象制备的过程中,通过离线+实时的方式同步数据,保障数据一致性
闲鱼的优惠中台的架构2.0版本的问题
在实际落地的过程中,如何将业务系统中的关注和购买关系同步到人群中,并保证数据的一致性。
人群的同步整体上分为两个主要部分:
-
将离线业务数据通过T+1的方式,同步到人群服务中。
-
通过实时同步的方式,将当天实时产生的关注、取消关注等行为产生的变动,同步的更新到人群服务中。

这种结合的方式具有以下优点:
-
实时消费消息进行同步,保障了数据的实时性。
-
离线T+1的全量同步,保证实时同步过程中产生的数据不一致会被及时的纠正,保障了数据的最终一致。
-
离线同步解决了数据初始化过程中的全量同步问题。
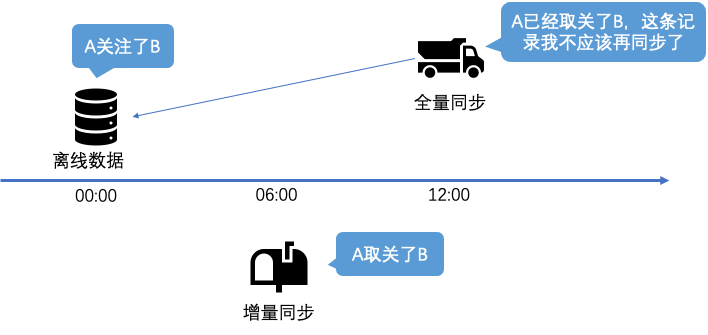
但上述的两个过程中,会出现两类问题:
-
离线数据因为其数据存储的特征,只会记录存在的关注关系,如果是被删除的关注关系(取消关注),则不会出现在离线数据中。因此实时同步中,因未同步取消关注事件产生了不一致,数据无法被全量同步纠正。
-
离线同步和实时同步在实际实施过程中,会产生一种常见的数据冲突:用户A今天原本关注了用户B,某天较早的时候取消关注了,如果这个时候的离线数据还没同步完成,全量同步会再次将A对B的关注关系写入到人群中,出现了与实际数据的不一致。
闲鱼的优惠中台的架构3.0版本
针对上述的两个问题,分别给出了以下两个解决方案:
-
针对取关数据误差无法通过全量同步纠正的问题,同步过程中,写入人群的时候会添加一个过期时间,这个过期时间略长于离线全量同步的间隔,这样的好处是一旦在实时同步过程中,出现了取关但未同步到人群的情况,这条记录会自动过期,从而避免了不一致的数据在系统中积累。
-
针对同步过程中发生数据冲突的问题,通过在实时同步的过程中,取关的事件在redis写入一条临时记录,表示该数据近期发生过取关;在全量同步过程中,去比对redis中是否有取关记录,避免发生冲突。
通过上述两个解决方案,闲鱼实现了人群同步的最终一致性,最终实现的方式如图:
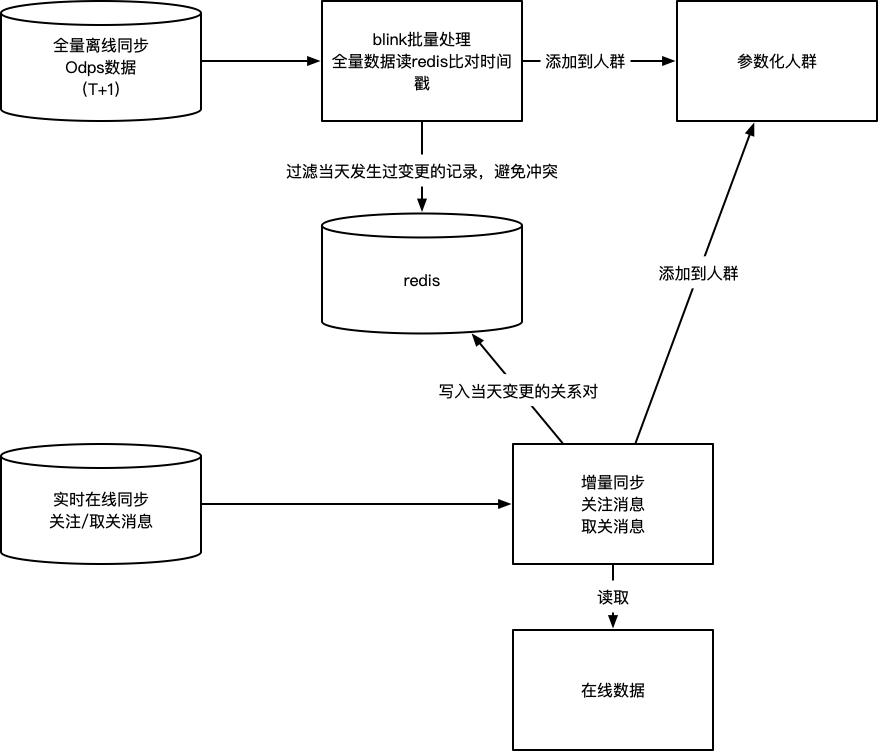
闲鱼数据一致性方案的普适性
这样的同步方案,对于搜索、推荐等大流量的导购场景,提供了充分的数据一致性保障。
绝大多数情况下,数据实时一致,对于小概率出现数据实时同步不一致,通过全量同步保障数据最终一致,满足导购场景的一致性要求。
此外,针对交易这样的要求强一致性但访问规模较小的场景,闲鱼团队通过下单前对人群同步的数据进行核对,保障数据的实时完全一致。
闲鱼团队结语
本文从三个部分介绍了优惠的实现:
-
通过对优惠要素的拆解和人群的定义,我们在描述、存储和计算优惠的同时,提供较好的业务可扩展性。
-
通过提前制备人群数据,我们保障了大流量下的优惠查询下性能,系统能够支持几十万QPS下的毫秒级响应。
-
在人群同步的过程中,通过离线+实时的方式同步数据,保障了数据的最终一致性。
在优惠的实现过程中,直接面临了一个迭代了多年的优惠中台,需要闲鱼团队通过同步人群数据的方式进行接入。可能一开始会疑惑为什么需要执行一个复杂、高成本且会引入数据一致性风险的同步过程。
但当闲鱼团队从业务的可扩展性、系统的性能角度从头进行推演的时候,闲鱼团队发现最终会回到类似的架构上来。
可以说,在特定的业务规模下,架构的演进有它历史的必然性。当然,也不是说这样的架构是适用于所有情况的,架构选型还是需要结合实际情况出发量身定制。
哈希映射(哈希表)基本原理
为了一次存储便能得到所查记录,在记录的存储位置和它的关键字之间建立一个确定的对应关系H,已H(key)作为关键字为key的记录在表中的位置,这个对应关系H为哈希(Hash)函数, 按这个思路建立的表为哈希表。
哈希表也叫散列表。从根本上来说,一个哈希表包含一个数组,通过特殊的关键码(也就是key)来访问数组中的元素。哈希表的主要思想:
(1)存放Value的时候,通过一个哈希函数,通过关键码(key)进行哈希运算得到哈希值,然后得到映射的位置, 去寻找存放值的地方 ,
(2)读取Value的时候,也是通过同一个哈希函数,通过关键码(key)进行哈希运算得到哈希值,然后得到 映射的位置,从那个位置去读取。
哈希函数
哈希表的组成取决于哈希算法,也就是哈希函数的构成。哈希函数计算过程会将键转化为数组的索引。一个好的哈希函数至少具有两个特征:
(1)计算要足够快;
(2)最小化碰撞,即输出的哈希值尽可能不会重复。
那接下来我们就来看下几个常见的哈希函数:
直接定址法
-
取关键字或关键字的某个线性函数值为散列地址。
-
即 f(key) = key 或 f(key) = a*key + b,其中a和b为常数。
除留余数法
将整数散列最常用方法是除留余数法。除留余数法的算法实用得最多。我们选择大小为m的数组,对于任意正整数k,计算k除以m的余数,即f(key)=k%m,f(key)<m。这个函数的计算非常容易(在Java中为k% M)并能够有效地将键散布在0到M-1的范围内。
数字分析法
-
当关键字的位数大于地址的位数,对关键字的各位分布进行分析,选出分布均匀的任意几位作为散列地址。
-
仅适用于所有关键字都已知的情况下,根据实际应用确定要选取的部分,尽量避免发生冲突。
平方取中法
-
先计算出关键字值的平方,然后取平方值中间几位作为散列地址。
-
随机分布的关键字,得到的散列地址也是随机分布的。
随机数法
-
选择一个随机函数,把关键字的随机函数值作为它的哈希值。
-
通常当关键字的长度不等时用这种方法。
每种数据类型都需要相应的散列函数。例如,Interge的哈希函数就是直接获取它的值:
public static int hashCode(int value) {
return value;
}
对于字符串类型则是使用了s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]的算法:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
public static int hashCode(byte[] value) {
int h = 0;
for (byte v : value) {
h = 31 * h + (v & 0xff);
}
return h;
}
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}
double类型则是使用位运算的方式进行哈希计算:
public int hashCode() {
long bits = doubleToLongBits(value);
return (int)(bits ^ (bits >>> 32));
}
public static long doubleToLongBits(double value) {
long result = doubleToRawLongBits(value);
if ( ((result & DoubleConsts.EXP_BIT_MASK) == DoubleConsts.EXP_BIT_MASK)
&&
(result & DoubleConsts.SIGNIF_BIT_MASK) != 0L)
result = 0x7ff8000000000000L;
return result;
}
于是Java让所有数据类型都继承了超类Object类,并实现hashCode()方法。接下来我们看下Object.hashcode方法。Object类中的hashcode方法是一个native方法。
public native int hashCode();
hashCode 方法的实现依赖于jvm,不同的jvm有不同的实现,我们看下主流的hotspot虚拟机的实现。
hotspot 定hashCode方法在src/share/vm/prims/jvm.cpp中,源码如下:
JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle))
JVMWrapper("JVM_IHashCode");
return handle == NULL ? 0 : ObjectSynchronizer::FastHashCode (THREAD, JNIHandles::resolve_non_null(handle)) ;
JVM_END
接下来我们看下ObjectSynchronizer::FastHashCode 方法是如何返回hashcode的,ObjectSynchronizer::FastHashCode 在synchronized.hpp文件中,
intptr_t ObjectSynchronizer::identity_hash_value_for(Handle obj) {
return FastHashCode (Thread::current(), obj()) ;
}
intptr_t ObjectSynchronizer::FastHashCode (Thread * Self, oop obj) {
if (UseBiasedLocking) {
if (obj->mark()->has_bias_pattern()) {
// Box and unbox the raw reference just in case we cause a STW safepoint.
Handle hobj (Self, obj) ;
// Relaxing assertion for bug 6320749.
assert (Universe::verify_in_progress() ||
!SafepointSynchronize::is_at_safepoint(),
"biases should not be seen by VM thread here");
BiasedLocking::revoke_and_rebias(hobj, false, JavaThread::current());
obj = hobj() ;
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
}
ObjectMonitor* monitor = NULL;
markOop temp, test;
intptr_t hash;
// 获取调用hashCode() 方法的对象的对象头中的mark word
markOop mark = ReadStableMark (obj);
// object should remain ineligible for biased locking
assert (!mark->has_bias_pattern(), "invariant") ;
if (mark->is_neutral()) { //普通对象
hash = mark->hash(); // this is a normal header
//如果mark word 中已经保存哈希值,那么就直接返回该哈希值
if (hash) { // if it has hash, just return it
return hash;
}
// 如果mark word 中还不存在哈希值,那就调用get_next_hash(Self, obj)方法计算该对象的哈希值
hash = get_next_hash(Self, obj); // allocate a new hash code
// 将计算的哈希值CAS保存到对象头的mark word中对应的bit位,成功则返回,失败的话可能有几下几种情形:
// (1)、其他线程也在install the hash并且先于当前线程成功,进入下一轮while获取哈希即可
// (2)、有可能当前对象作为监视器升级成了轻量级锁或重量级锁,进入下一轮while走其他case;
temp = mark->copy_set_hash(hash); // merge the hash code into header
// use (machine word version) atomic operation to install the hash
test = (markOop) Atomic::cmpxchg_ptr(temp, obj->mark_addr(), mark);
if (test == mark) {
return hash;
}
// If atomic operation failed, we must inflate the header
// into heavy weight monitor. We could add more code here
// for fast path, but it does not worth the complexity.
} else if (mark->has_monitor()) { // 重量级锁
// 果对象是一个重量级锁monitor,那对象头中的mark word保存的是指向ObjectMonitor的指针,
// 此时对象非加锁状态下的mark word保存在ObjectMonitor中,到ObjectMonitor中去拿对象的默认哈希值:
monitor = mark->monitor();
temp = monitor->header();
assert (temp->is_neutral(), "invariant") ;
hash = temp->hash();
// (1)如果已经有默认哈希值,则直接返回;
if (hash) {
return hash;
}
// Skip to the following code to reduce code size
} else if (Self->is_lock_owned((address)mark->locker())) { //轻量级锁锁
// 如果对象是轻量级锁状态并且当前线程持有锁,那就从当前线程栈中取出mark word:
temp = mark->displaced_mark_helper(); // this is a lightweight monitor owned
assert (temp->is_neutral(), "invariant") ;
hash = temp->hash(); // by current thread, check if the displaced
//(1)如果已经有默认哈希值,则直接返回;
if (hash) { // header contains hash code
return hash;
}
}
// Inflate the monitor to set hash code
monitor = ObjectSynchronizer::inflate(Self, obj);
// Load displaced header and check it has hash code
mark = monitor->header();
assert (mark->is_neutral(), "invariant") ;
hash = mark->hash();
// 计算默认哈希值并保存到mark word中后再返回
if (hash == 0) {
hash = get_next_hash(Self, obj);
temp = mark->copy_set_hash(hash); // merge hash code into header
assert (temp->is_neutral(), "invariant") ;
test = (markOop) Atomic::cmpxchg_ptr(temp, monitor, mark);
if (test != mark) {
hash = test->hash();
assert (test->is_neutral(), "invariant") ;
assert (hash != 0, "Trivial unexpected object/monitor header usage.");
}
}
// We finally get the hash
return hash;
}ObjectSynchronizer :: FastHashCode()也是通过调用identity_hash_value_for方法返回值的,调用了get_next_hash()方法生成hash值,源码如下:
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) { // 随机数 openjdk6、openjdk7 采用的是这种方式
// This form uses an unguarded global Park-Miller RNG,
// so it's possible for two threads to race and generate the same RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random() ;
} else
if (hashCode == 1) { // 基于对象内存地址的函数
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addrBits = cast_from_oop<intptr_t>(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else
if (hashCode == 2) { // 恒等于1(用于敏感性测试)
value = 1 ; // for sensitivity testing
} else
if (hashCode == 3) { // 自增序列
value = ++GVars.hcSequence ;
} else
if (hashCode == 4) { // 将对象的内存地址强转为int
value = cast_from_oop<intptr_t>(obj) ;
} else {
// 生成hash值的方式六: Marsaglia's xor-shift scheme with thread-specific state
//(基于线程具体状态的Marsaglias的异或移位方案) openjdk8之后采用的就是这种方式
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD ;
assert (value != markOopDesc::no_hash, "invariant") ;
TEVENT (hashCode: GENERATE) ;
return value;
}到底用的哪一种计算方式,和参数hashCode有关系,在src/share/vm/runtime/globals.hpp中配置了默认: openjdk6:
product(intx, hashCode, 0, \
"(Unstable) select hashCode generation algorithm") \
openkjdk8:
product(intx, hashCode, 5, \
"(Unstable) select hashCode generation algorithm") \
也可以通过虚拟机启动参数-XX:hashCode=n来做修改。
哈希表因为其本身结构使得查找对应的值变得方便快捷,但是也带来了一些问题,问题就是无论使用哪种方式生成hash值,总有产生相同值的时候。接下来我们就来看下如何解决hash值相同的问题。
hash 碰撞(哈希冲突)
对于两个不同的数据元素通过相同哈希函数计算出来相同的哈希地址(即两不同元素通过哈希函数取模得到了同样的模值),这种现象称为哈希冲突或哈希碰撞。
一般来说,哈希冲突是无法避免的。如果要完全避免的话,那么就只能一个字典对应一个值的地址,这样一来, 空间就会增大,甚至内存溢出。减少哈希冲突的原因是Hash碰撞的概率就越小,map的存取效率就会越高。 常见的哈希冲突的解决方法有开放地址法和链地址法:
开放地址法
开放地址法又叫开放寻址法、开放定址法,当冲突发生时,使用某种探测算法在散列表中寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到。开放地址法需要的表长度要大于等于所需要存放的元素。
按照探测序列的方法,可以细分为线性探查法、平法探查法、双哈希函数探查法等。这里为了更好的展示三种方法的效果,我们用例子来看看:
设关键词序列为{47,7,29,11,9,84,54,20,30},哈希表长度为13,装载因子=9/13=0.69,哈希函数为f(key)=key%p=key%11
| 关键词(key) | 47 | 7 | 29 | 11 | 9 | 84 | 54 | 20 | 30 |
|---|---|---|---|---|---|---|---|---|---|
| 散列地址k(key) | 3 | 7 | 7 | 0 | 9 | 7 | 10 | 9 | 8 |
(1)线性探测法
当我们的所需要存放值的位置被占了,我们就往后面一直加1并对m取模直到存在一个空余的地址供我们存放值,取模是为了保证找到的位置在0~m-1的有效空间之中。
公式:fi=(f(key)+i) % m ,0 ≤ i ≤ m-1i会逐渐递增加1)
具体做法: 探查时从地址d开始,首先探查T[d],然后依次探查T[d+1]....直到T[m-1],然后又循环到T[0]、T[1],...直到探查到有空余的地址或者直到T[d-1]为止。
用线性探测法处理冲突得到的哈希表如下
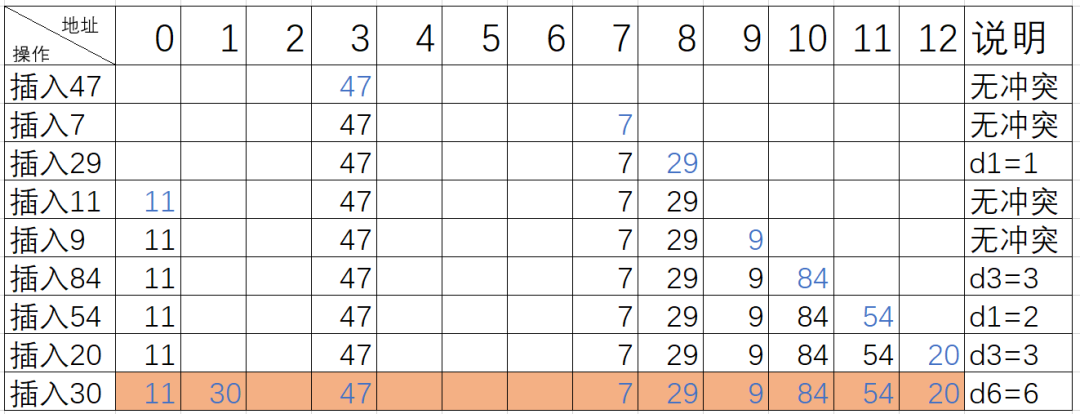
缺点:需要不断处理冲突,无论是存入还是査找效率都会大大降低。
(2)平方探查法
当我们的所需要存放值的位置被占了,会前后寻找而不是单独方向的寻找。
公式:fi=(f(key)+di) % m,0 ≤ i ≤ m-1
具体操作:探查时从地址 d 开始,首先探查 T[d],然后依次探查 T[d+di],di 为增量序列12、-12,22、-22, ……,q2、-q2 且q≤1/2 (m-1) ,直到探查到 有空余地址或者到 T[d-1]为止。
用平方探查法处理冲突得到的哈希表如下
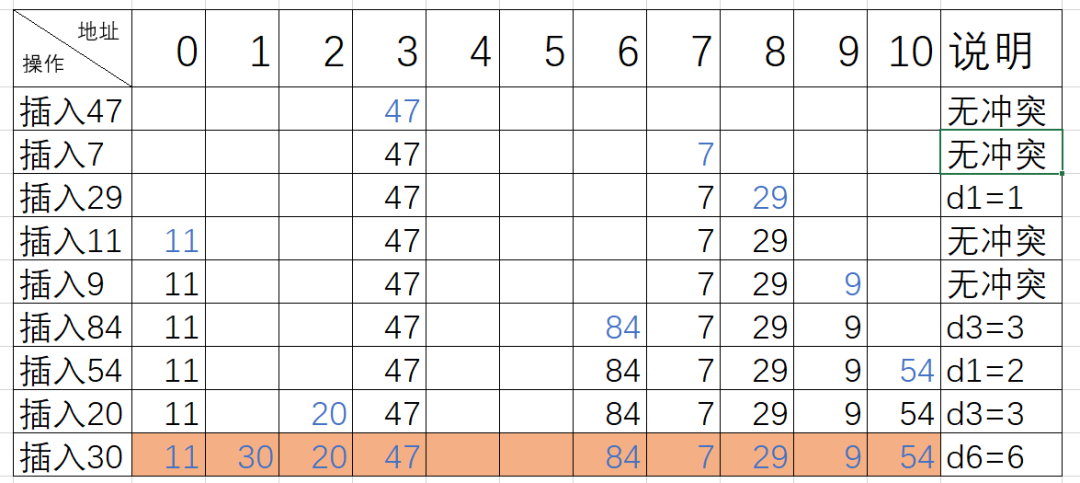
(3)双哈希函数探查法
公式:fi=(f(key)+i*g(key)) % m (i=1,2,……,m-1) 其中f(key) 和g(key) 是两个不同的哈希函数,m为哈希表的长度。
具体步骤: 双哈希函数探测法,先用第一个函数f(key)对关键码计算哈希地址,一旦产生地址冲突,再用第二个函数 g(key)确定移动的步长因子,最后通过步长因子序列由探测函数寻找空的哈希地址。
开发地址法,通过持续的探测,最终找到空的位置。为了解决这个问题,引入了链地址法。
链地址法
在哈希表每一个单元中设置链表,某个数据项对的关键字还是像通常一样映射到哈希表的单元中,而数据项本身插入到单元的链表中.
链地址法简单理解如下:
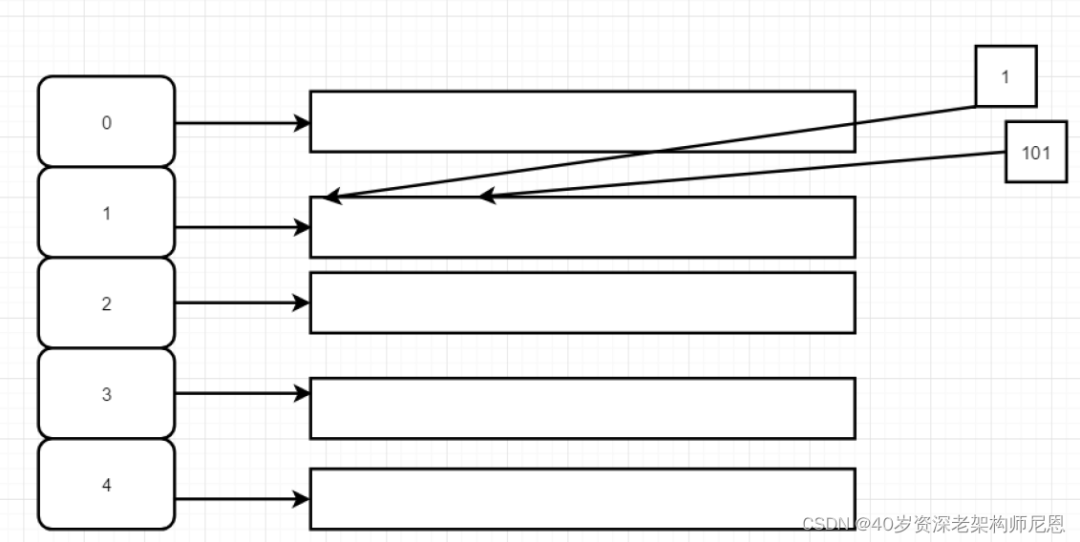
来一个相同的数据,就将它插入到单元对应的链表中,在来一个相同的,继续给链表中插入。链地址法解决哈希冲突的例子如下:
(1)采用除留余数法构造哈希函数,而 冲突解决的方法为 链地址法。
(2)具体的关键字列表为(19,14,23,01,68,20,84,27,55,11,10,79),则哈希函数为f(key)=key MOD 13。则采用除留余数法和链地址法后得到的预想结果应该为:
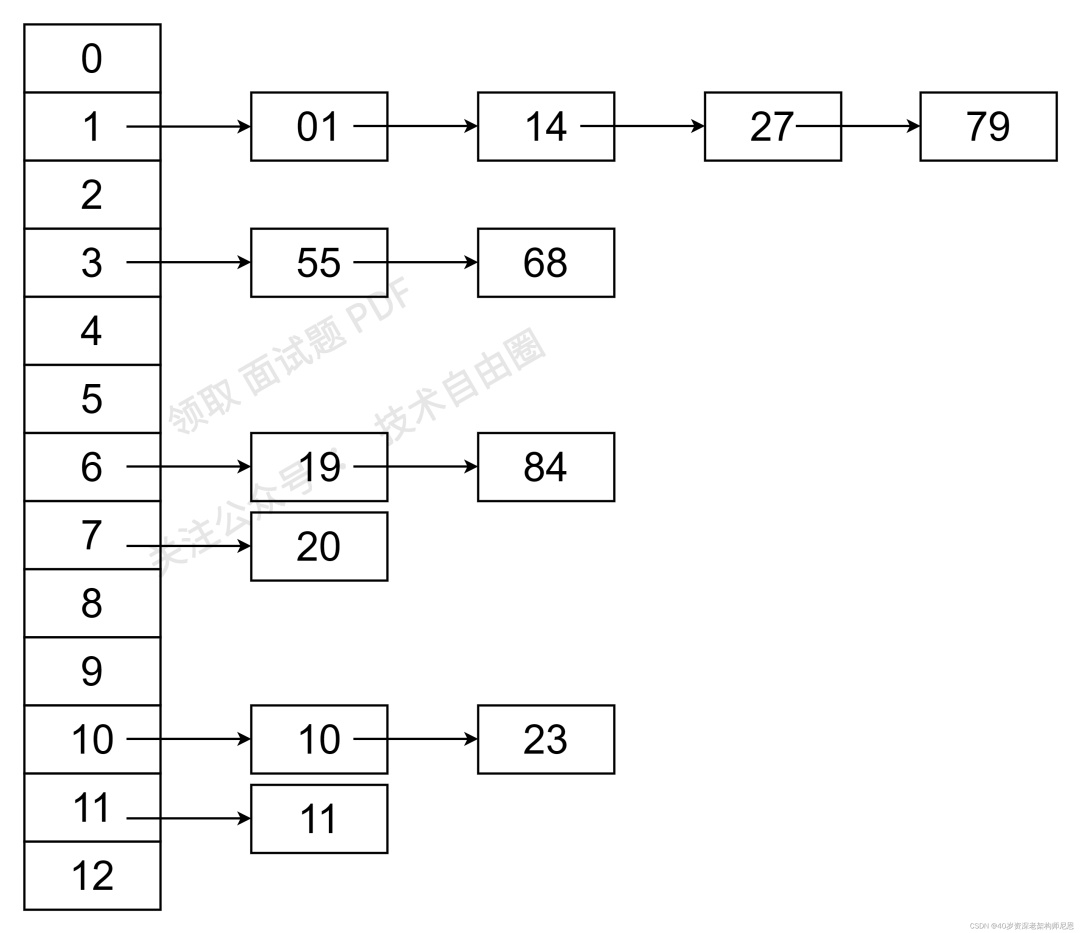
链地址法解放哈希冲突
哈希造表完成后,进行查找时,首先是根据哈希函数找到关键字的位置链,然后在该链中进行搜索,如果存在和关键字值相同的值,则查找成功,否则若到链表尾部仍未找到,则该关键字不存在。
哈希表作为一个非常常用的查找数据结构,它能够在O(1)的时间复杂度下进行数据查找,时间主要花在计算hash值上。在Java中,典型的Hash数据结构的类是HashMap。
然而也有一些极端的情况,最坏的就是hash值全都映射在同一个地址上,这样哈希表就会退化成链表,例如下面的图片:
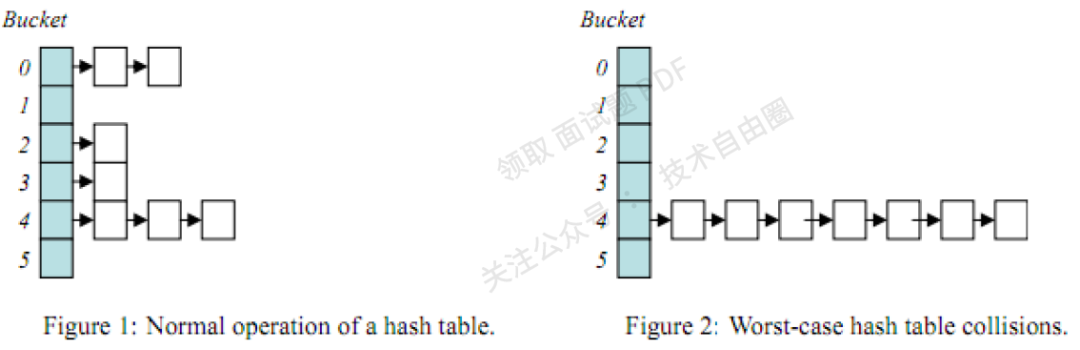
hash表特殊情况
当hash表变成图2的情况时,查找元素的时间复杂度会变为O(n),效率瞬间低下,所以,设计一个好的哈希表尤其重要,如HashMap在jdk1.8后引入的红黑树结构就很好的解决了这种情况。
HashMap table桶的扩容机制
哈希桶数组的大小, 在空间成本和时间成本之间权衡,时间和空间之间进行权衡:
-
如果哈希桶数组很大,即使较差的Hash算法也会比较分散, 空间换时间
-
如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞, 时间换空间
其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。
在剖析table扩容之前,我们先来了解hashMap中几个比较重要的属性。
HashMap中有两个比较重要的属性:加载因子(loadFactor)和边界值(threshold),在HashMap时,就会涉及到这两个关键初始化参数,loadFactor和threshold的源码如下:
final float loadFactor;
int threshold;
Node[] table的初始化长度length(默认值是16),length大小必须为2的n次方,主要是为了方便扩容。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
loadFactor 为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node 个数。threshold 、length 、loadFactor 三者之间的关系:
threshold = length * Load factor
默认情况下 threshold = 16 * 0.75 =12。
threshold就是允许的哈希数组最大元素数目,超过这个数目就重新resize(扩容),扩容后的哈希数组 容量length 是之前容量length 的两倍。
threshold是通过初始容量和LoadFactor计算所得,在初始HashMap不设置参数的情况下,默认边界值 为12。
如果HashMap中Node的数量超过边界值,HashMap就会调用resize()方法重新分配table数组。这将会导致HashMap的数组复制,迁移到另一块内存中去,从而影响HashMap的效率。
loadFactor默认值是0.75,官方给的解释如下:

loadFactor默认值是0.75的原因
大概意思是:作为一般规则,默认负载因子 (.75) 在时间和空间成本之间提供了良好的折衷。较高的值会减少空间开销,但会增加查找成本(反映在HashMap类的大多数操作中,包括get和put )。在设置其初始容量时,应考虑映射中的预期条目数及其负载因子,以尽量减少重新哈希操作的次数。 如果初始容量大于最大条目数除以负载因子,则不会发生重新哈希操作。
loadFactor 也是可以调整的,建议大家尽量不要修改,除非在时间和空间比较特殊的情况:
-
如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;
-
如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以 大于1
接下来我们再来看一个size属性。
size属性是HashMap中实际存在的键值对数量;而length是哈希桶数组table的长度。
当HashMap中的元素越来越多的时候,碰撞的几率也就越来越高,所以为了提高查询的效率,就要对HashMap的数组进行扩容,其实数组扩容这个操作在ArrayList中也出现了,所以这是一个通用的操作,
table是一个Node<K,V>类型的数组,其定义如下:
transient Node<K,V>[] table;
Node 类作为 HashMap 中的一个内部类,除了 key、value 两个属性外,还定义了一个next 指针,当有哈希冲突时,HashMap 会用之前数组当中相同哈希值对应存储的 Node 对象,通过指针指向新增的相同哈希值的Node 对象的引用。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
}
table在首次使用put的时候初始化,并根据需求调整大小。
当table中的Node<K,V>个数超过数组大小*loadFactor时,就会触发扩容机制。每次扩容的容量都是之前容量的 2 倍。HashMap 的容量是有上限的,必须小于 1<<30,即 1073741824。如果容量超出了这个数,则不再增长,且阈值会被设置为 Integer.MAX_VALUE。
JDK7 中的扩容机制(1)空参数的构造函数:以默认容量、默认负载因子、默认阈值初始化数组。内部数组是空数组。 (2)有参构造函数:根据参数确定容量、负载因子、阈值等。 (3)第一次 put 时会初始化数组,其容量变为不小于指定容量的 2 的幂数,然后根据负载因子确定阈值。 (4)如果不是第一次扩容,则 新容量=旧容量 x 2 ,新阈值=新容量 x 负载因子 。
JDK8 的扩容机制(1)空参数的构造函数:实例化的 HashMap 默认内部数组是 null,即没有实例化。第一次调用 put 方法时,则会开始第一次初始化扩容,长度为 16。 (2)有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的 2 的幂数,
哈希桶数组table的扩容核心是resize()方法。在resize的时候会将原来的数组rehash重新计算hash值转移到新数组上。在HashMap数组扩容之后,最消耗性能的点是原数组中的数据必须重新计算其在新数组中的位置,并放进去。
微服务架构
微服务框架的优势
-
模块化和可扩展性:微服务框架将应用程序拆分成多个独立的服务,每个服务可以独立开发、部署和扩展,提高了系统的灵活性和可伸缩性。
-
技术多样性:微服务框架支持使用不同的技术栈和编程语言来构建不同的服务,使团队可以根据具体需求选择最合适的技术。
-
高可用性和容错性:微服务框架通过服务注册与发现、负载均衡和容错机制,提供了高可用性和容错性,保证了系统的稳定性和可靠性。
-
独立部署和快速迭代:每个服务可以独立部署,使团队可以快速迭代和发布新功能,提高了开发和交付的效率。
设计微服务框架的基本原则
在设计微服务框架时,我们需要遵循一些基本原则,以确保系统的可扩展性、可维护性和可靠性。以下是设计微服务框架的基本原则:
1.解耦和独立性
微服务架构的核心概念之一是服务的解耦和独立性。每个微服务应该具有清晰的边界,它们可以独立开发、部署和扩展。在设计框架时,要保证各个微服务之间的解耦,使其可以独立演化而不会对其他服务产生过多的影响。
2.可伸缩性和容错性
微服务架构的另一个重要目标是实现可伸缩性和容错性。框架应该能够根据负载的增加或减少,自动扩展或缩减服务实例的数量。同时,要考虑到服务的容错能力,当某个服务出现故障时,框架应该能够自动将请求路由到其他可用的服务实例上。
3.简化开发和部署过程
微服务框架应该能够简化开发和部署的过程。提供一套标准化的开发模式和工具链,使开发人员可以快速构建和部署微服务。自动化的构建、测试和部署流程能够提高开发效率,减少人为错误。
4.兼容性和可扩展性
框架应该具备良好的兼容性和可扩展性,能够与其他技术和组件进行集成。例如,能够无缝地与现有的数据存储、消息队列、认证授权系统等进行整合。此外,框架本身也应该是可扩展的,可以根据需求灵活地添加新的功能模块。
设计微服务框架时,需要综合考虑这些原则,并根据实际情况进行权衡和取舍。合理的框架设计能够提高开发效率、降低系统复杂度,并为微服务架构的可持续发展打下坚实的基础。在后续的章节中,我们将深入探讨如何应用这些原则,结合Spring Cloud、Nacos、Spring Cloud Gateway、Feign等组件,构建一套高效可靠的Java微服务框架。
微服务接口协议
JPA(Java Persistence API)是Java EE的一部分,是一种用于对象持久化的规范。它提供了一种以面向对象的方式进行数据库操作的方式,通过简化数据库访问和数据对象之间的映射,提高了开发效率。
JPA使用注解来描述实体类和数据库表之间的映射关系,可以轻松地进行增删改查等常见数据库操作。它支持各种关系型数据库,并提供了事务管理、缓存等功能。
实现服务注册与发现
服务注册与发现是微服务架构中非常重要的一部分,它允许我们动态地注册和发现微服务实例,从而实现微服务之间的通信。在这一节中,我们将详细介绍服务注册与发现的工作原理和实现方式。
-
服务注册
服务注册是指将微服务实例的信息(例如主机名、端口号、服务名称等)注册到服务注册中心,使得其他服务可以发现和调用它。下面是服务注册的步骤:
-
微服务启动时,它会向服务注册中心发送注册请求,提供自己的信息。
-
服务注册中心收到注册请求后,将微服务的信息保存起来,并为其生成一个唯一的标识符(例如服务ID)。
-
其他微服务可以通过服务注册中心查询和获取已注册的微服务实例列表。
-
服务发现
服务发现是指在需要调用其他微服务时,通过服务注册中心来获取可用的微服务实例信息。下面是服务发现的步骤:
-
微服务需要调用其他服务时,它向服务注册中心发送发现请求,指定需要调用的服务名称。
-
服务注册中心根据服务名称查询已注册的微服务实例列表,并返回给调用方。
-
调用方根据负载均衡策略选择一个可用的微服务实例进行调用。
-
实现方式
服务注册与发现可以采用不同的实现方式,常见的有以下几种:
-
基于服务注册中心的实现:使用独立的服务注册中心,例如Netflix Eureka、Consul或Nacos。微服务在启动时将自己注册到注册中心,其他微服务可以通过查询注册中心获取可用的微服务实例信息。
-
基于DNS的实现:每个微服务使用自己的主机名和端口号,其他微服务通过域名解析来发现和调用它们。这种方式通常用于较小规模的微服务架构。
-
基于边车代理的实现:使用边车代理(例如Zuul或Spring Cloud Gateway)来代理所有的微服务请求,并在代理层进行服务发现和负载均衡。
通过服务注册与发现,可以实现微服务架构的弹性、可扩展和高可用性,使得微服务之间的通信更加灵活和可靠。
实现服务调用和负载均衡
-
服务调用的概念
服务调用是指一个微服务向另一个微服务发起请求,获取所需的数据或执行特定的操作。在微服务架构中,服务调用可以跨越多个微服务实例,因此需要一种机制来管理和处理服务之间的通信。
-
使用Feign与Nacos实现服务调用和负载均衡
-
Feign是一个声明式的Web服务客户端,它可以与多种服务注册中心集成,包括Nacos。通过使用Feign,我们可以通过简单的接口定义来调用其他微服务,并且不需要手动编写具体的HTTP请求代码。
-
Nacos作为服务注册中心,提供了服务发现和负载均衡的功能。它可以自动维护微服务实例列表,并根据负载均衡策略选择合适的实例进行调用。
Feign将负责处理底层的HTTP通信细节,而Nacos将负责维护微服务实例列表和选择合适的实例进行调用,从而实现了服务调用和负载均衡的功能。
实现服务监控和日志管理
服务监控是指对微服务架构中的各个服务进行实时监控和管理,以确保系统的稳定性和可靠性。通过监控服务的运行状态、性能指标和异常情况,可以及时发现问题并采取相应措施,以提高系统的可用性和响应能力。
日志管理是指对微服务架构中生成的日志进行收集、存储、分析和展示的过程。日志是系统运行的重要记录,通过对日志进行管理和分析,可以了解系统的运行状况、故障信息和异常情况,以便于问题排查和系统优化。
服务监控和日志管理对于微服务架构具有重要的必要性和优势:
-
实时监控和管理:通过服务监控,可以实时监测服务的运行状态、性能指标和异常情况,及时发现问题并采取措施,保证系统的稳定性和可靠性。
-
故障排查和问题定位:通过日志管理,可以收集和分析系统生成的日志信息,帮助快速定位问题、排查故障,提高故障处理的效率。
-
性能优化和系统优化:通过监控和分析服务的性能指标,可以发现性能瓶颈和优化空间,以提升系统的性能和响应能力。
-
数据分析和业务洞察:通过对日志进行分析和挖掘,可以获得有价值的业务洞察,帮助优化业务流程和决策制定。
Spring Boot Admin 服务监控
Spring Boot Admin是一个开源的服务监控和管理工具,它提供了一个Web界面,用于监控和管理基于Spring Boot的应用程序。通过Spring Boot Admin,可以实时监控和管理应用程序的运行状态、健康状况、性能指标等,并提供了强大的可视化和告警功能。
ELK 日志监控
ELK是一个流行的日志管理和分析解决方案,由Elasticsearch、Logstash和Kibana三个项目组成,常用于日志收集和分析。
日志主要包括系统日志、应用程序日志和安全日志。运维和开发人员可以通过日志了解服务器运行过程中发生的错误及错误产生的原因。定期分析日志可以了解服务器的运行情况、性能、安全性等。
每台服务器或应用程序都会产生日志,如果每次都登录这些服务器查看日志并分析会耗费大量时间,而且效率低下,这时我们就需要思考如何将日志汇总起来统一查看。日志集中管理之后又会产生新的问题,日志量太大,日志统计和检索又成为新的问题,如何能实现高性能的检索统计呢?ELK能完美解决我们的问题。
-
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
-
Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用。
-
kibana 也是一个开源和免费的工具,它可以为 Logstash 和 Elasticsearch 提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。
https://www.cnblogs.com/crazymakercircle/p/16732034.html
保护服务安全
在微服务架构中,服务安全保护是至关重要的,它们可以保护微服务免受未经授权的访问,并确保只有经过身份验证和授权的用户才能访问受保护的资源。
Spring Cloud Gateway是一个基于Spring Framework 5、Project Reactor和Spring Boot 2构建的轻量级网关服务,用于构建和管理微服务架构中的API网关。API网关在微服务架构中安全方面扮演着重要的角色,它作为系统的入口,它可以提供以下安全功能:
-
访问控制:API网关可以对传入的请求进行访问控制,确保只有经过身份验证和授权的用户能够访问受保护的资源。它可以验证请求中的身份验证令牌或证书,并根据配置的权限规则进行访问控制。
-
安全认证和授权:API网关可以与认证和授权中间件(如OAuth2)集成,实现对微服务的安全认证和授权。它可以验证请求中的访问令牌,并将认证和授权信息传递给后端的微服务,以确保只有具有足够权限的用户能够访问特定的资源。
-
保护后端服务:API网关可以隐藏后端的微服务架构,只暴露必要的接口给外部客户端,从而降低了被恶意攻击的风险。它可以阻止未经授权的请求直接访问后端服务,并提供请求的限流和缓冲功能,以保护后端服务免受过载或恶意攻击。
-
安全审计和日志记录:API网关可以记录请求和响应的详细信息,包括访问时间、来源IP、请求内容等,以便进行安全审计和故障排查。它可以将日志记录到集中的日志管理系统中,方便监控和分析。
-
攻击防护:API网关可以实施一些安全防护措施,如防止跨站脚本攻击(XSS)、跨站请求伪造(CSRF)和注入攻击等。它可以对传入的请求进行验证和过滤,以识别和阻止潜在的恶意行为。
综上所述,API网关在安全方面具有重要的作用。它可以提供访问控制、安全认证和授权、保护后端服务、安全审计和日志记录以及攻击防护等功能,帮助确保微服务架构的安全性和可靠性。通过合理配置和使用适当的安全机制,API网关可以成为微服务架构中的首道防线,保护系统免受潜在的安全威胁。
Spring Cloud Gateway作为微服务架构的入口,除了提供了路由转发,还提供了负载均衡、过滤器、安全认证、请求限流和监控等功能
https://www.cnblogs.com/crazymakercircle/p/11704077.html
实现持续集成和部署
持续集成(Continuous Integration)是一种软件开发实践,旨在频繁地将代码集成到主干版本控制系统中。持续部署(Continuous Deployment)是持续集成的延伸,自动将通过持续集成构建的可部署软件包发布到生产环境。
以下是一种基本的实现方式:
-
版本控制:使用版本控制系统(如Git)管理代码,确保团队成员可以协同开发,并且每个更改都有明确的记录。
-
自动化构建:使用构建工具(如Maven)配置构建脚本,定义项目的编译、打包、测试等步骤。
-
持续集成服务器:使用持续集成服务器(如Jenkins)来触发构建,并执行自动化构建过程。
-
自动化测试:编写并执行自动化测试脚本,包括单元测试、集成测试和端到端测试等,以确保代码质量和功能稳定性。
-
自动化部署:使用容器化技术(如Docker)打包应用程序,并将其部署到预先定义的环境中,如开发环境、测试环境和生产环境。
1.Jenkins
Jenkins是一个开源的持续集成工具,它提供了一系列功能和插件,用于自动化构建、测试和部署软件。以下是Jenkins的基本概念和特点:
-
作业(Job):Jenkins中的最小单位,代表一个构建或部署任务。
-
构建(Build):Jenkins执行的一次构建过程,包括编译代码、运行测试、生成构建报告等。
-
插件(Plugin):Jenkins提供了丰富的插件生态系统,用于扩展其功能,例如集成不同的版本控制系统、构建工具和部署平台等。
2.Docker
Docker是一个开源的容器化平台,它可以将应用程序及其依赖项打包到容器中,提供了一致、可重复和可移植的部署环境。以下是Docker的基本概念和特点:
-
镜像(Image):Docker容器的基础组件,包含了完整的操作系统和应用程序的运行环境。
-
容器(Container):基于镜像创建的运行实例,每个容器都是相互隔离的,拥有自己的文件系统、进程空间和网络接口。
-
仓库(Repository):用于存储和分享镜像的中央注册表,Docker Hub是最常用的公共仓库
3.配置步骤
-
微服务应用新增Dockerfile文件
FROM openjdk:8-jre
RUN mkdir /app
COPY students-service-exec.jar /app/app.jar
ENTRYPOINT ["java", "-Djava.security.egd=file:/dev/./urandom", "-jar", "/app/app.jar"]
EXPOSE 8180
-
安装和配置Jenkins:
-
下载Jenkins:访问Jenkins官方网站(Jenkins download and deployment)下载适合您操作系统的Jenkins安装包。
-
安装Jenkins:按照官方文档提供的步骤,安装Jenkins并完成初始化配置。
-
安装插件:通过Jenkins的插件管理界面,安装必要的插件,如Git插件、Maven插件、docker插件等。
安装过程可参考 https://zhuanlan.zhihu.com/p/566398364
-
-
配置Jenkins构建任务:
-
创建新任务:在Jenkins主界面,选择"新建任务",输入任务名称,并选择自由风格的软件项目。
-
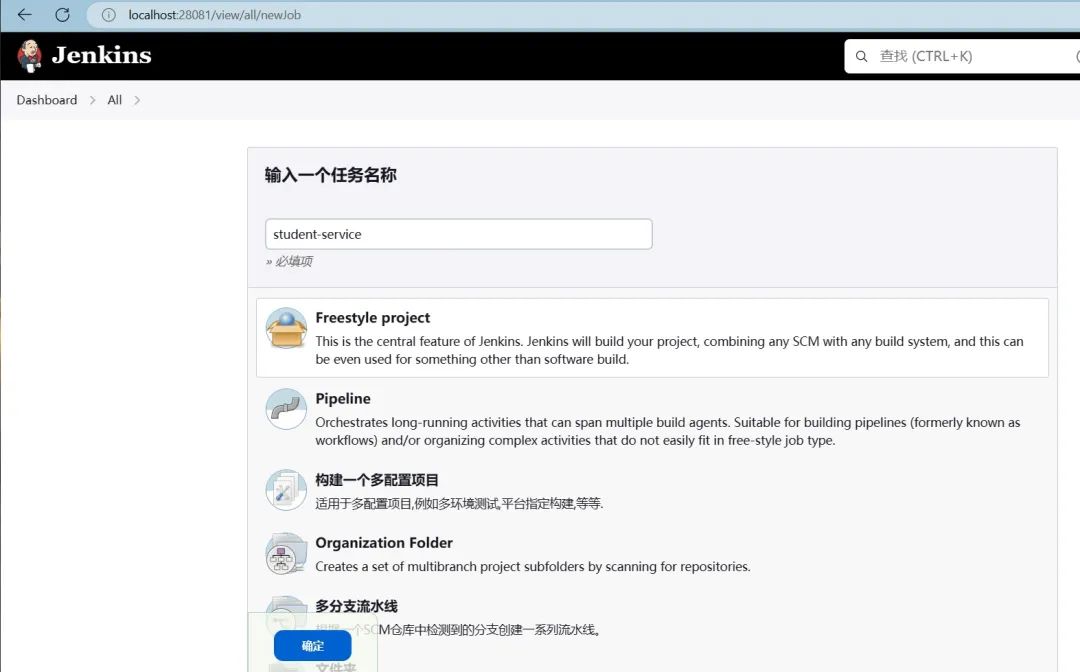
-
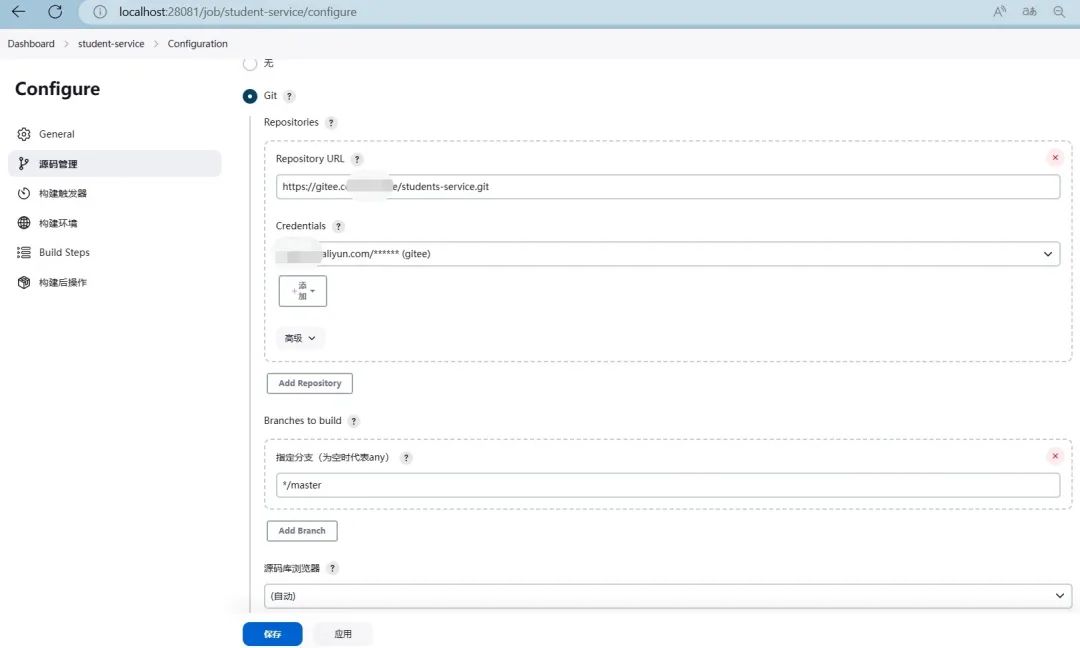
配置源代码管理:在任务配置界面,选择Git作为源代码管理工具,提供代码仓库的URL和凭据。
-
配置构建步骤:在构建步骤中,可以定义构建脚本,如编译代码、运行测试、打包构建等。
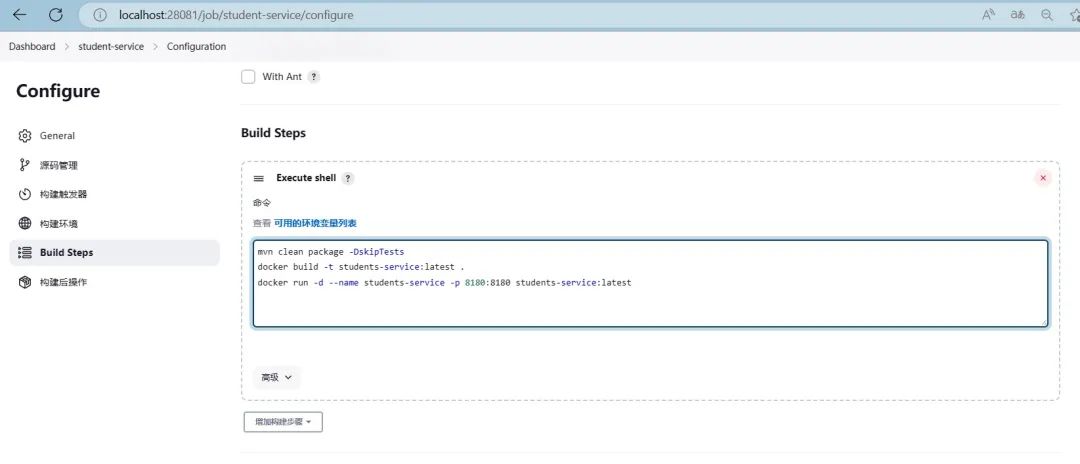
-
安装和配置Docker:
-
安装Docker:根据您的操作系统,参考Docker官方文档(https://docs.docker.com/get-docker/)进行Docker的安装。
-
配置Docker构建环境:在Jenkins任务配置界面,选择"添加构建步骤",选择"Execute shell"或"Execute Windows batch command",然后在脚本中使用Docker命令构建和发布镜像。
-
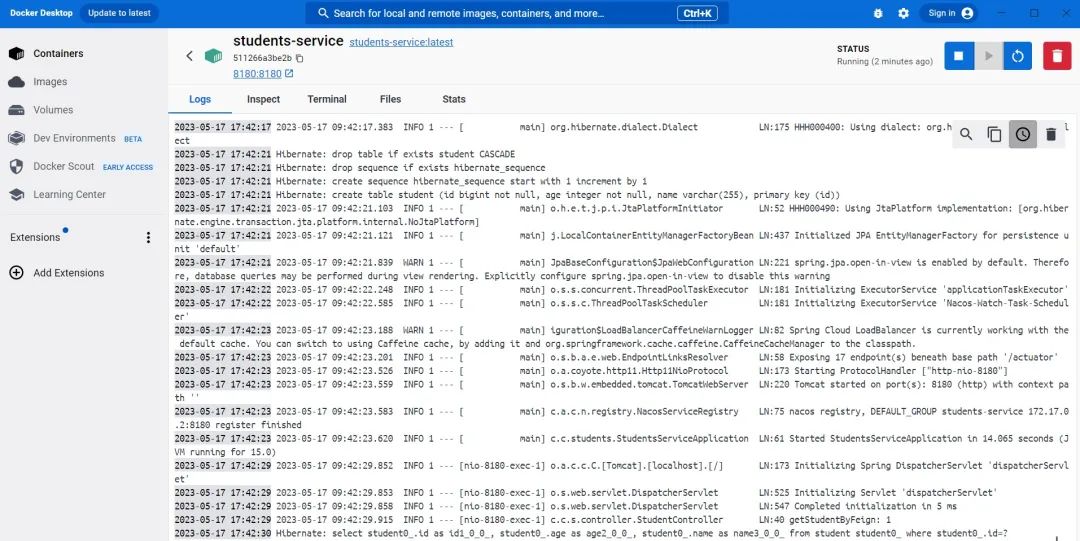
构建成功后,我们可以在docker桌面端看到students-service服务已启动,
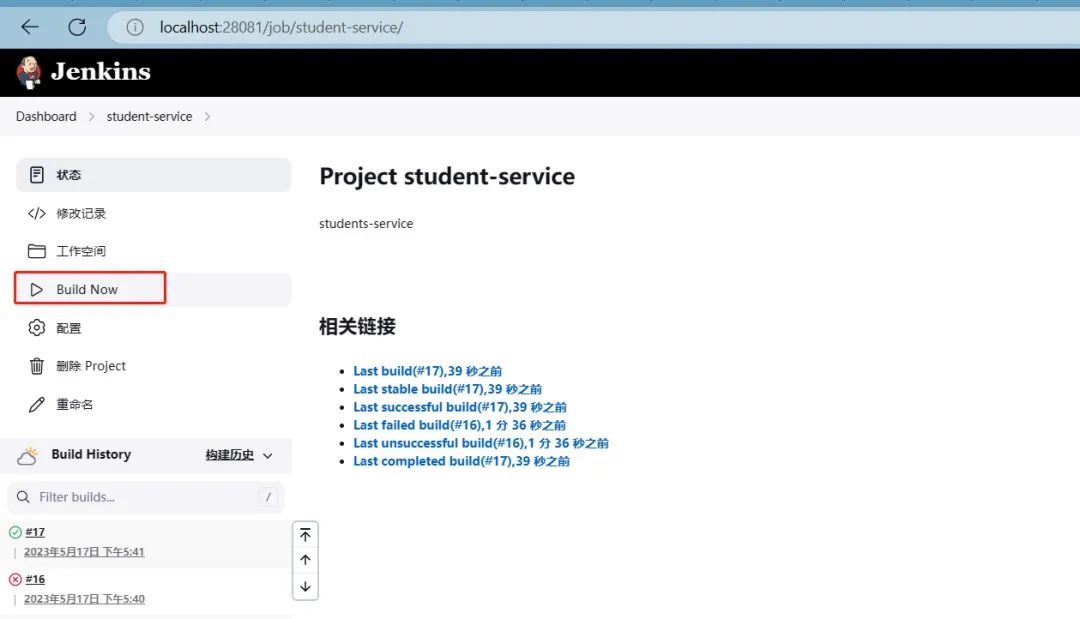
通过以上步骤,您可以使用Jenkins和Docker实现持续集成和部署。
Jenkins将根据配置的触发器自动执行构建任务,通过Docker构建和发布镜像,实现持续集成和部署的流程。
总结
不足和改进的方向如下:
-
性能监控和报警:在服务监控和日志管理部分,我们可以进一步改进,引入Prometheus和Grafana来实现更全面的性能监控和报警功能。Prometheus是一个开源的监控系统,可以收集和存储各种指标数据,并提供强大的查询和报警功能。Grafana是一个数据可视化工具,可以将Prometheus收集的数据以图表的形式展示出来,帮助我们更直观地了解系统的性能状况。通过使用Prometheus和Grafana,我们可以实时监控系统的指标,并设置报警规则,及时发现并解决潜在的性能问题。
-
为了保障微服务系统的稳定性和可靠性,你还需要考虑服务的熔断、限流、降级等策略。可以使用 Hystrix 或者 Resilience4j 等库来实现这些功能。
-
容器化部署:在持续集成和部署部分,我们可以进一步改进,引入Kubernetes(K8s)来实现容器化部署。Kubernetes是一个开源的容器编排平台,可以简化和自动化应用程序的部署、扩展和管理。通过使用Kubernetes,我们可以将微服务框架中的各个服务容器化,并通过K8s进行部署、伸缩和管理,提供更高效、可靠和弹性的部署方案。
-
自动化和流程改进:在持续集成和部署部分,我们可以进一步改进和优化自动化流程。通过使用更先进的CI/CD工具和技术,如Jenkins Pipeline、GitOps等,可以实现更高度的自动化和流程改进。例如,可以通过编写自动化的流水线脚本,实现代码的构建、测试、打包和部署的自动化,并与版本控制系统(如Git)进行集成,实现代码的自动触发和持续交付。
通过上述改进,我们可以进一步提升微服务框架的性能监控、报警能力,以及部署和管理的效率和可靠性。这将有助于更好地满足不断变化的业务需求,并提升系统的可靠性和稳定性。















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









