







说说 cookie 和 session
Cookie 和 Session 是 Web 开发中常用的两种技术,它们都可以用来在客户端和服务端之间传递数据。但是它们的作用范围、实现方式以及使用场景等方面有很大的区别。
Cookie与使用场景
Cookie 是一种浏览器存储技术,注意,这里强调的是客户端。Cookie 可以为用户在 客户端 (主要是浏览器)存储一些键值对数据,以便在用户下次访问同一网站时发送给服务器。Cookie 可以设置过期时间,也可以设置 HttpOnly 属性,从而保护用户的隐私安全。
Cookie 的使用场景:
-
网站登录:通过在客户端存储一个唯一的标识符来验证用户身份,实现单点登录。
-
网站跟踪:通过在客户端存储一些统计信息来了解用户的行为习惯,从而优化网站的性能。
-
网站设置:通过在客户端存储一些偏好设置来实现个性化推荐等功能。
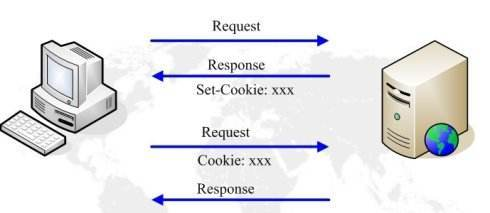
Cookie 是在HTTP协议下,服务器或脚本可以维护客户工作站上信息的一种方式。Cookie 是由 Web 服务器保存在用户浏览器内存或用户本地硬盘(客户端)上的小文本文件(内容通常经过加密),它可以包含有关用户的信息。
无论何时用户链接到服务器,Web站点都可以访问 Cookie 信息
Session与使用场景
Session 是一种服务器端存储技术,注意,这里强调的是服务器端。Session 可以在同一台服务器上为每个用户创建一个独立的会话,从而实现用户的不同请求之间的数据共享。Session 可以存储一些键值对数据,也可以设置过期时间。
Session 的使用场景:
-
购物车功能:当用户将商品添加到购物车中时,将商品信息存储在 Session 中,以便用户在下一次访问购物车页面时能够继续使用之前的操作。
-
会员系统:当用户注册成为会员时,将用户的信息存储在 Session 中,以便在后续的访问中能够识别用户身份并提供相应的服务。
-
论坛系统:当用户发表帖子或回复帖子时,将用户的信息存储在 Session 中,以便在后续的访问中能够显示用户的发帖记录或回复记录。
-
其他需要 为 同一用户 共享数据的场景
Cookie 和 Session 的区别
-
作用范围不同:Cookie 是浏览器存储技术,只能在客户端存储数据;Session 是服务器端存储技术,只能在同一台服务器上为每个用户创建一个独立的会话。
-
实现方式不同:Cookie 是浏览器自动发送给服务器的数据;Session 是服务器端创建的一个对象,可以通过编程的方式进行管理。
-
安全性不同:Cookie 可以设置 HttpOnly 属性来保护用户的隐私安全;Session 可以设置加密算法来保护用户的敏感信息安全。
-
数据大小限制不同:Cookie 的大小限制为 4KB;Session 的大小限制没有明确的限制,但是受到服务器内存和硬盘空间的限制。
-
过期时间控制不同:Cookie 可以设置过期时间来控制数据的有效期;Session 可以设置过期时间来控制会话的有效期。
-
使用场景不同:Cookie 可以用于网站登录、网站跟踪、网站设置等场景;Session 可以用于购物车功能、会员系统、论坛系统等场景。
Session机制如何实现 用户的多个请求,或者多次请求,能共享数据呢?
服务器收到请求,首先检查这个客户端里的请求里是否已包含了一个session标识–sessionID,如果已经包含一个sessionID,则说明以前已经为此客户端创建过session,服务器就按照sessionID把这个session检索出来使用(检索不到,可能会新建一个),
如果客户端请求不包含sessionID,则为此客户端创建一个session并且声称一个与此session相关联的sessionID,sessionID的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串(服务器会自动创建),这个sessionID将被在本次响应中返回给客户端保存。
Redis 的数据结构和持久化方式
Redis 支持多种数据结构,包括字符串、哈希表、列表、集合和有序集合等。
具体的说明如下:
-
字符串类型:Redis 中最基本的数据类型,它可以存储字符串、散列、列表、集合和有序集合等。
-
Hash 类型:Redis 中的哈希表,它使用哈希表的数据结构来存储键值对,其中每个键都是唯一的。
-
List 类型:Redis 中的列表,它使用链表的数据结构来存储一系列的值。
-
Set 类型:Redis 中的集合,它使用集合的数据结构来存储一系列不重复的值。
-
Sorted Set 类型:Redis 中的有序集合,它使用集合的数据结构来存储一系列有序的值。
字符串是最基本的数据类型,可以存储任何类型的数据,包括二进制数据。
哈希表可以看作是字符串到字符串值的映射,列表是一个有序的字符串列表,集合是一个无序的字符串集合,而有序集合则是一个有序的字符串集合,其中每个字符串都关联着一个分值。
Redis 支持两种持久化方式:RDB 和 AOF。
RDB持久化
RDB 是一种快照持久化方式,可以将 Redis 的数据保存到硬盘上,以便在 Redis 重启时恢复数据。
RDB 持久化的优点是文件体积较小,但缺点是需要定期执行备份操作,且在备份期间无法对数据库进行读写操作。
RDB持久化配置
Redis会将数据集的快照dump到dump.rdb文件中。
此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
AOF 持久化
AOF 则是一种追加式日志持久化方式,可以将 Redis 的所有写操作以追加的方式写入一个日志文件中,以便在 Redis 重启时重新执行这些写操作来恢复数据。
将每次对数据库的操作以日志的形式记录下来,可以在服务器重启时以日志文件的方式恢复数据集。
AOF 持久化的优点是可以实现实时备份,不需要定期执行备份操作,但缺点是文件体积较大,写入性能较低。
AOF持久化配置
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
两种持久化方式各有优缺点,可以根据具体的应用场景选择合适的方式。
Linux 常用的 shell 命令
Linux 是一种自由和开放源代码的类 Unix 操作系统,它被广泛用于服务器、桌面电脑、移动设备等各种场合。Linux 的核心思想是“一切皆文件”,这意味着所有的硬件设备、文件系统、应用程序都可以用文件的形式进行访问和管理。
Linux是其主要特点包括:
-
开放源代码:Linux的源代码可以在互联网上自由获取和修改,这使得用户可以根据自己的需求对其进行定制和修改。
-
免费使用:Linux是一种免费的操作系统,用户可以在不用支付任何费用的情况下使用和分发。
-
稳定可靠:Linux经过了长时间的实践和测试,已经被证明是一种非常稳定可靠的操作系统,适用于各种环境下的应用。
-
安全性高:Linux具有严格的权限管理和安全机制,可以有效地保护系统不受恶意攻击和非法访问。
-
应用广泛:Linux可以运行在各种硬件平台上,从服务器到桌面都可以使用,同时也有大量的开源应用程序和工具可供使用。
Linux的应用范围非常广泛,包括但不限于:
-
服务器操作系统:Linux是最流行的服务器操作系统之一,广泛应用于各种互联网服务和应用。
-
桌面操作系统:Linux也可以作为桌面操作系统使用,例如Ubuntu、KDE等。
-
嵌入式系统:Linux可以用于各种嵌入式设备,如物联网设备、机器人等。
-
工作站和个人计算机:Linux也可以用于个人计算机和工作站,作为操作系统和工具使用。
常用的shell 命令:
mkdir
cd
ls
pwd
ps -ef
jps
....
消息中间件的作用
消息中间件是一种用于在分布式系统中传递消息的中间件软件。
它的作用是将消息从一个应用程序传递到另一个应用程序,同时提供了异步通信、解耦、可靠性、消息持久化、消息分发等功能。
通过消息中间件,应用程序可以实现解耦,即发送者和接收者不需要知道彼此的存在,从而提高系统的可维护性和扩展性。
消息中间件的作用:
-
解耦系统:
消息中间件可以将不同应用程序之间的通信解耦,使得它们可以独立地扩展和部署。这意味着一个应用程序的故障不会影响到其他应用程序的正常运行。
-
异步调用:
消息中间件支持异步调用,这意味着发送方和接收方可以在不等待对方响应的情况下继续执行自己的代码。这种方式可以提高系统的吞吐量和性能。
-
可靠性保证:
消息中间件提供了一些机制来保证消息的可靠性,例如消息持久化、消息重试、消息确认等。这些机制可以确保消息不会丢失或被错误处理。
-
灵活性:
消息中间件通常具有高度的灵活性,可以与不同的编程语言和操作系统集成。此外,它们还提供了一些高级功能,例如主题、队列、路由等,以满足不同的应用场景。
在了解中间件之前,先介绍一下什么是同步?
首先我们想一下,两个公司之间如果有互相调用接口的业务需求,如果没有引入中间件技术,是怎么实现的呢?
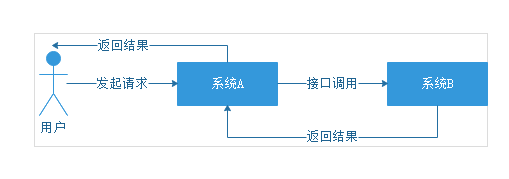
用户发起请求给系统A,系统A接到请求直接调用系统B,系统B返回结果后,系统A才能返回结果给用户,这种模式就是同步调用。
所谓同步调用就是各个系统之间互相依赖,一个系统发送请求,其他系统也会跟着依次进行处理,只有所有系统处理完成后对于用户来讲才算完成了一次请求。只要其他系统出现故障,就会报错给用户。
那么引入中间件后,是如何做到异步调用的呢?
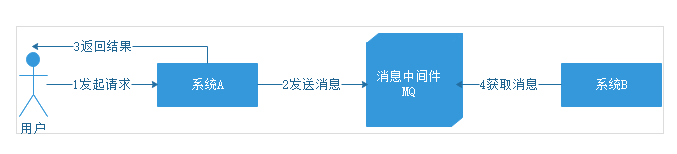
用户发起请求给系统A,此时系统A发送消息给MQ,然后就返回结果给用户,不去管系统B了。然后系统B根据自己的情况,去MQ中获取消息,获取到消息的时候可能已经过了1分钟甚至1小时,再根据消息的指示执行相应的操作。
那么想一想,系统A和系统B互相之间是否有通信?这种调用方式是同步调用吗?
系统A发送消息给中间件后,自己的工作已经完成了,不用再去管系统B什么时候完成操作。而系统B拉去消息后,执行自己的操作也不用告诉系统A执行结果,所以整个的通信过程是异步调用的。
说到这里,我们可以做个总结,消息中间件到底是什么呢?
其实消息中间件就是一个独立部署的系统。可以实现各个系统之间的异步调用。当然它的作用可不止这些,通过它可以解决大量的技术痛点,我们接下来会进行介绍。
消息中间件,总结起来作用有三个:异步化提升性能、降低耦合度、流量削峰。
异步化提升性能
先来说说异步化提升性能,上边我们介绍中间件的时候已经解释了引入中间件后,是如何实现异步化的,但没有解释具体性能是怎么提升的,我们来看一下下边的图。
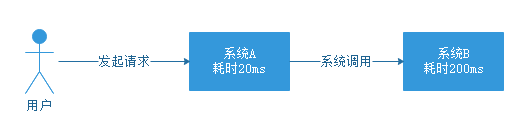
没有引入中间件的时候,用户发起请求到系统A,系统A耗时20ms,接下来系统A调用系统B,系统B耗时200ms,带给用户的体验就是,一个操作全部结束一共耗时220ms。
如果引入中间件之后呢?看下边的图。
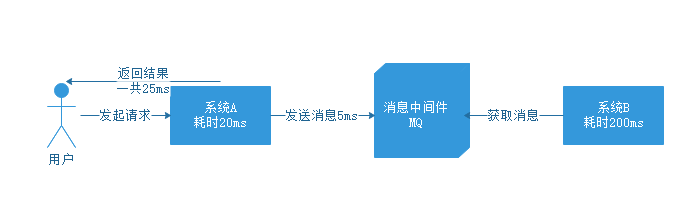
用户发起请求到系统A,系统A耗时20ms,发送消息到MQ耗时5ms,返回结果一共用了25ms,用户体验一个操作只用了25ms,而不用管系统B什么时候去获取消息执行对应操作,这样比较下来,性能自然大大提高
再详细介绍一下,消息中间件具体如何降低耦合度
再来聊聊解耦的场景,看下图。
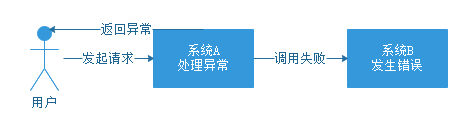
如果没有引入中间件,那么系统A调用系统B的时候,系统B出现故障,导致调用失败,那么系统A就会接到异常信息,接到异常信息后肯定要再处理一下,返回给用户失败请稍后再试,这时候就得等待系统B的工程师解决问题,一切都解决好后再告知用户可以了,再重新操作一次吧。
这样的架构,两个系统耦合再一起,用户体验极差。
那么我们引入中间件后是什么样的场景呢,看下面的流程:
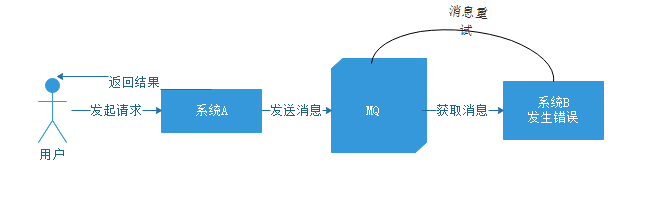
对于系统A,发送消息后直接返回结果,不再管系统B后边怎么操作。
而系统B故障恢复后重新到MQ中拉取消息,重新执行未完成的操作,这样一个流程,系统之间没有影响,也就实现了解耦。
最后详细介绍一下,什么是流量削峰
下面我们再聊聊最后一个场景,流量削峰
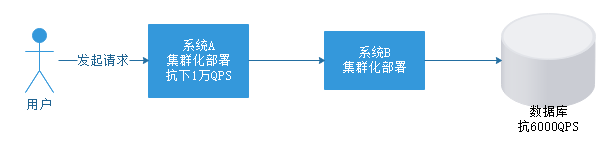
假如我们的系统A是一个集群,不连接数据库,这个集群本身可以抗下1万QPS
系统B操作的是数据库,这个数据库只能抗下6000QPS,这就导致无论系统B如何扩容集群,都只能抗下6000QPS,它的瓶颈在于数据库。
假如突然系统QPS达到1万,就会直接导致数据库崩溃,那么引入MQ后是怎么解决的呢,见下图:
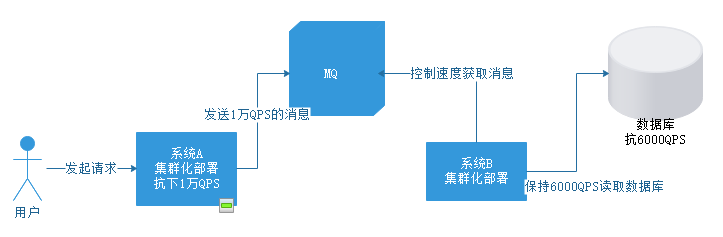
引入MQ后,对于系统A没有什么影响,给MQ发送消息可以直接发送1万QPS。
此时对于系统B,可以自己控制获取消息的速度,保持在6000QPS一下,以一个数据库能够承受的速度执行操作。这样就可以保证数据库不会被压垮。
当然,这种情况MQ中可能会积压大量消息。
但对于MQ来说,是允许消息积压的,等到系统A峰值过去,恢复成1000QPS时,系统B还是在以6000QPS的速度去拉取消息,自然MQ中的消息就慢慢被释放掉了。
这就是流量削峰的过程。
在电商秒杀、抢票等等具有流量峰值的场景下可以使用这么一套架构。
如何设计一个高并发高可用的方案?
设计高并发高可用的方案需要考虑多个方面,包括硬件基础设施、网络架构、应用软件架构和中间件高可用高并发架构等。
硬件基础设施
1.服务器选择
为了实现高可用性,我们需要使用多台服务器。
首先,我们需要选择服务器的配置。服务器的配置应该足够强大,以处理高并发请求。
我们建议使用至少8核CPU和16GB内存的服务器,并且每台服务器应该有至少2个网卡。
此外,我们建议使用固态硬盘(SSD)而不是机械硬盘,因为SSD可以提供更快的读写速度。
2.负载均衡器
为了分发请求并提高系统的可用性,我们需要使用负载均衡器。
负载均衡器可以将请求分发到多个服务器上,以实现负载均衡。我们建议使用硬件负载均衡器,因为它可以提供更好的性能和可靠性。如果使用云服务提供商的负载均衡器,则需要考虑其性能和可靠性。
3.虚拟化技术
为了实现快速部署和扩展,我们建议使用虚拟化技术。
虚拟化技术可以将一台物理服务器划分为多个虚拟服务器,每个虚拟服务器都可以运行独立的操作系统和应用程序。这使得我们可以快速部署和扩展服务器,同时提高了资源的利用率。
网络架构
1.CDN
为了加速静态资源的传输并减轻服务器的负担,我们建议使用CDN(内容分发网络)。CDN可以将静态资源缓存到离用户更近的节点上,以提高资源的传输速度。我们建议使用全球性的CDN服务提供商,例如阿里云CDN、腾讯云CDN等。
2.防火墙和DDoS防护系统
为了保障网络安全,我们需要使用防火墙和DDoS防护系统。防火墙可以阻止未经授权的访问,保护系统免受攻击。DDoS防护系统可以识别和阻止DDoS攻击,保障系统的可用性。我们建议使用专业的防火墙和DDoS防护系统,例如阿里云安全组、腾讯云安全组等。
应用高可用架构
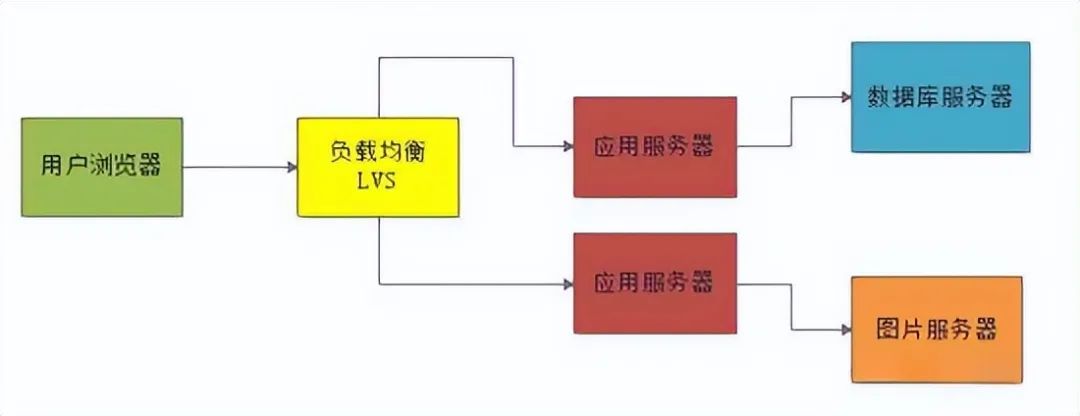
为了实现应用高可用,一般会集群化部署。
当然所谓的集群化部署,在初期用户量很少的情况下,其实一般也就是部署两台应用服务器而已,然后前面会放一台服务器部署负载均衡设备,比如说LVS,均匀的把用户请求打到两台应用服务器上去。
如果此时某台应用服务器故障了,还有另外一台应用服务器是可以使用的,这样就避免了单点故障问题。
如下图所示:
应用微服务的高并发架构
这个假设这个网站预估的用户数是1000万,那么根据28法则,每天会来访问这个网站的用户占到20%,也就是200万用户每天会过来访问。
通常假设平均每个用户每次过来会有30次的点击,那么总共就有6000万的点击(PV)。
每天24小时,根据28法则,每天大部分用户最活跃的时间集中在(24小时 * 0.2)≈ 5小时内,而大部分用户指的是(6000万点击 * 0.8 ≈ 5000万点击)
也就是说,在5小时内会有5000万点击进来。
换算下来,在那5小时的活跃访问期内,大概每秒钟会有3000左右的请求量,然后这5小时中可能又会出现大量用户集中访问的高峰时间段。
比如在集中半个小时内大量用户涌入形成高峰访问。
根据线上经验,一般高峰访问是活跃访问的2~3倍。假设我们按照3倍来计算,那么5小时内可能有短暂的峰值会出现每秒有10000左右的请求。
大概知道了高峰期每秒钟可能会有1万左右的请求量之后,来看一下系统中各个服务器的压力预估。
一般来说一台虚拟机部署的应用服务器,上面放一个Tomcat,也就支撑最多每秒几百的请求。
按每秒支撑500的请求来计算,那么支撑高峰期的每秒1万访问量,需要部署20台应用服务。
而且应用服务器对数据库的访问量又是要翻几倍的,因为假设一秒钟应用服务器接收到1万个请求,但是应用服务器为了处理每个请求可能要涉及到平均3~5次数据库的访问。
按照3次数据库访问来算,那么每秒会对数据库形成3万次的请求。
按照一台数据库服务器最高支撑每秒5000左右的请求量,此时需要通过6台数据库服务器才能支撑每秒3万左右的请求。
图片服务器的压力同样会很大,因为需要大量的读取图片展示页面,这个不太好估算,但是大致可以推算出来每秒至少也会有几千次请求,因此也需要多台图片服务器来支撑图片访问的请求。
业务垂直拆分
一般来说在这个阶段要做的第一件事儿就是 业务的垂直拆分。
因为如果所有业务代码都混合在一起部署,会导致多人协作开发时难以维护。
在网站到了千万级用户的时候,研发团队一般都有几十人甚至上百人。
所以这时如果还是在一个单块系统里做开发,是一件非常痛苦的事情,此时需要做的就是进行业务的垂直拆分,把一个单块系统拆分为多个业务系统,然后一个小团队10个人左右就专门负责维护一个业务系统。
如下图
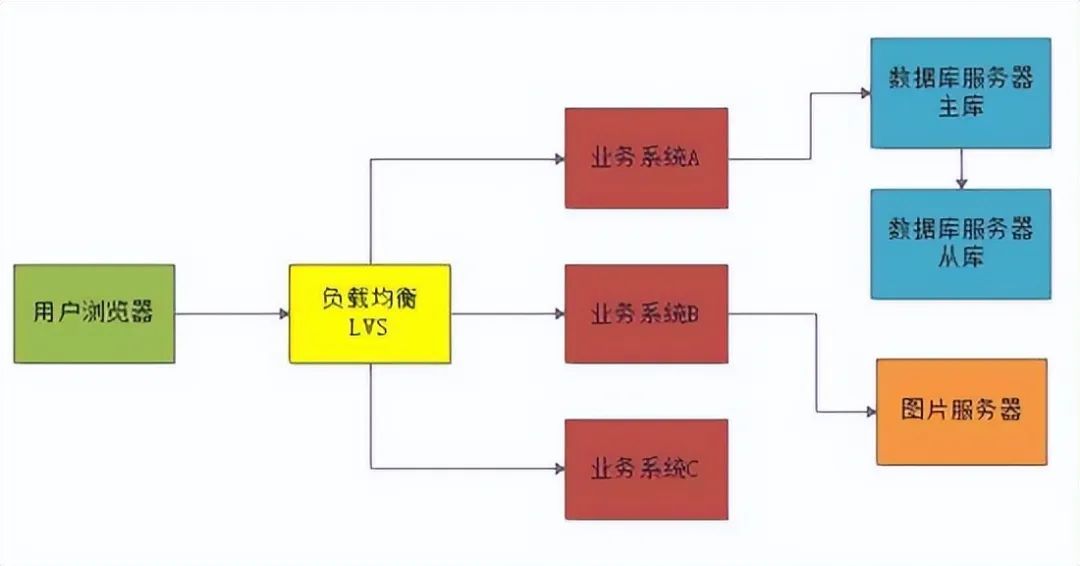
中间件的高可用高并发架构
分布式缓存高可用高并发架构
这个时候应用服务器层面一般没什么大问题,因为无非就是加机器就可以抗住更高的并发请求。
现在估算出来每秒钟是1万左右的请求,部署个二三十台机器就没问题了。
但是目前上述系统架构中压力最大的,其实是 数据库层面 ,因为估算出来可能高峰期对数据库的读写并发会有3万左右的请求。
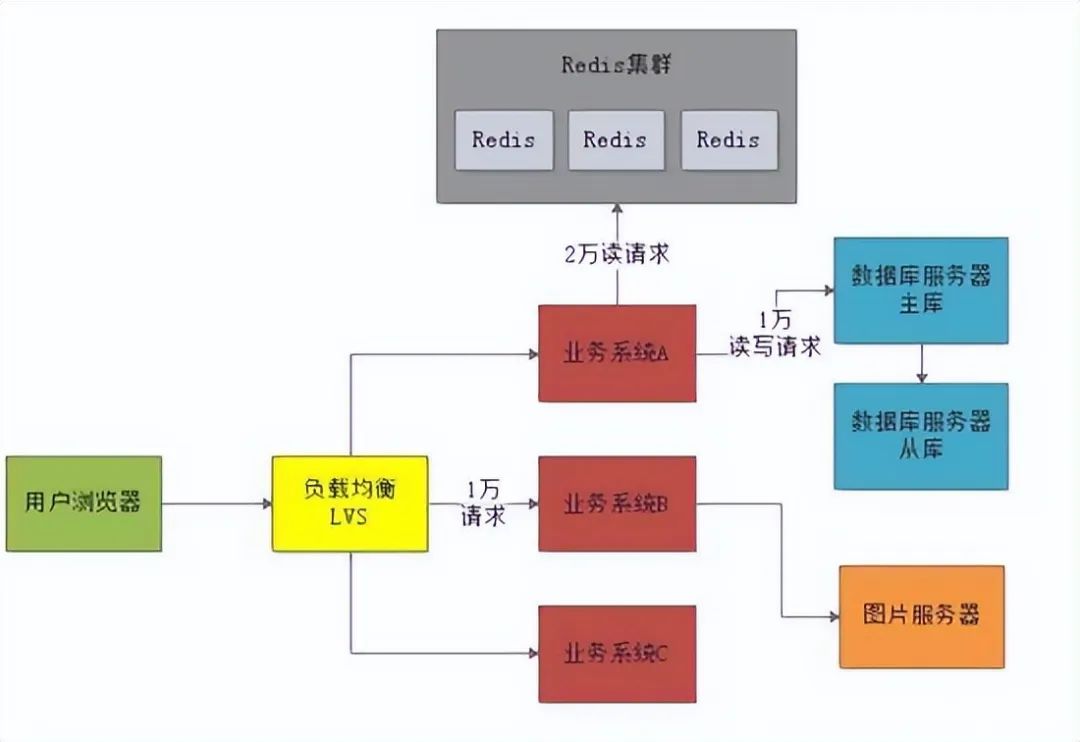
此时就需要引入 分布式缓存 来抗下对数据库的读请求压力了,也就是引入Redis集群。
一般来说对数据库的读写请求也大致遵循28法则,所以每秒3万的读写请求中,大概有2.4万左右是读请求。
这些读请求基本上90%都可以通过分布式缓存集群来抗下来,也就是大概2万左右的读请求可以通过 Redis集群来抗住。
我们完全可以把热点的、常见的数据都在Redis集群里放一份作为缓存,然后对外提供缓存服务。
在读数据的时候优先从缓存里读,如果缓存里没有,再从数据库里读取。这样2万读请求就落到Redis上了,1万读写请求继续落在数据库上。
Redis一般单台服务器抗每秒几万请求是没问题的,所以Redis集群一般就部署3台机器,抗下每秒2万读请求是绝对没问题的。如下图所示:
数据库主从架构做读写分离
对于数据库服务器而言,此时一般也会使用主从架构,部署一台从库来从主库同步数据,
如下图:
这样一旦主库出现问题,可以迅速使用从库继续提供数据库服务,避免数据库故障导致整个系统都彻底故障不可用。
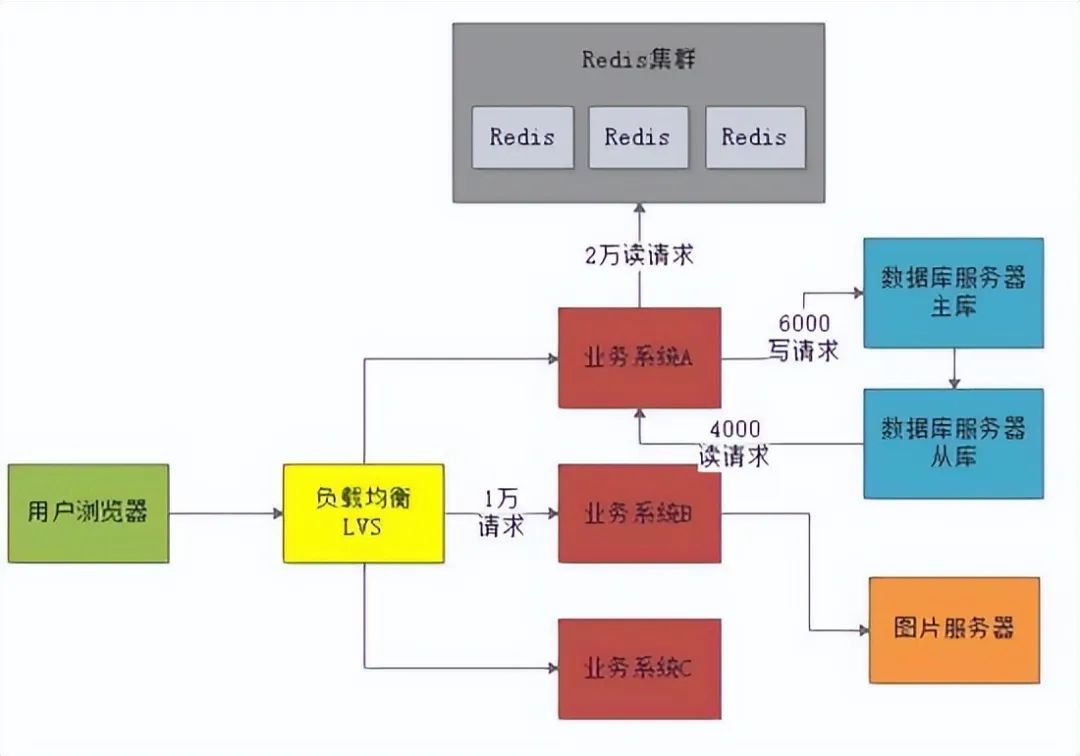
此时数据库服务器还是存在每秒1万的请求,对于单台服务器来说压力还是过大。
但是数据库一般都支持主从架构,也就是有一个从库一直从主库同步数据过去。此时可以基于主从架构做 读写分离 。
也就是说,每秒大概6000写请求是进入主库,大概还有4000个读请求是在从库上去读,这样就可以把1万读写请求压力分摊到两台服务器上去。
这么分摊过后,主库每秒最多6000写请求,从库每秒最多4000读请求,基本上可以勉强把压力给抗住。如下图:
总结
大型网站架构中共涉及的技术远远不止这些,还包括了MQ、CDN、静态化、分库分表、NoSQL、搜索、分布式文件系统、反向代理,等等很多话题,但是本文不能一一涉及,
说说限流算法,漏桶、令牌桶和计数
为什么要限流
限流在很多场景中用来限制并发和请求量,比如说秒杀抢购,保护自身系统和下游系统不被巨型流量冲垮等。
以微博为例,例如某某明星公布了恋情,访问从平时的50万增加到了500万,系统的规划能力,最多可以支撑200万访问,那么就要执行限流规则,保证是一个可用的状态,不至于服务器崩溃,所有请求不可用。
限流的思想
在保证可用的情况下尽可能多增加进入的人数,其余的人在排队等待,或者返回友好提示,保证里面的进行系统的用户可以正常使用,防止系统雪崩。
日常生活中,有哪些需要限流的地方?
像我旁边有一个国家景区,平时可能根本没什么人前往,但是一到五一或者春节就人满为患,这时候景区管理人员就会实行一系列的政策来限制进入人流量, 为什么要限流呢?
假如景区能容纳一万人,现在进去了三万人,势必摩肩接踵,整不好还会有事故发生,这样的结果就是所有人的体验都不好,如果发生了事故景区可能还要关闭,导致对外不可用,这样的后果就是所有人都觉得体验糟糕透了。
限流的算法
限流算法很多,常见的有三类,分别是计数器算法、漏桶算法、令牌桶算法,下面逐一讲解。
限流的手段通常有计数器、漏桶、令牌桶。注意限流和限速(所有请求都会处理)的差别,视 业务场景而定。
(1)计数器:
在一段时间间隔内(时间窗/时间区间),处理请求的最大数量固定,超过部分不做处理。
(2)漏桶:
漏桶大小固定,处理速度固定,但请求进入速度不固定(在突发情况请求过多时,会丢弃过多的请求)。
(3)令牌桶:
令牌桶的大小固定,令牌的产生速度固定,但是消耗令牌(即请求)速度不固定(可以应对一些某些时间请求过多的情况);每个请求都会从令牌桶中取出令牌,如果没有令牌则丢弃该次请求。
计数器算法
计数器限流定义
在一段时间间隔内(时间窗/时间区间),处理请求的最大数量固定,超过部分不做处理。
简单粗暴,比如指定线程池大小,指定数据库连接池大小、nginx连接数等,这都属于计数器算法。
计数器算法是限流算法里最简单也是最容易实现的一种算法。
举个例子,比如我们规定对于A接口,我们1分钟的访问次数不能超过100个。
那么我们可以这么做:
-
在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个请求的间隔时间还在1分钟之内,那么说明请求数过多,拒绝访问;
-
如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,就是这么简单粗暴。
计算器限流的实现
package com.crazymaker.springcloud.ratelimit;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
// 计速器 限速
@Slf4j
public class CounterLimiter
{
// 起始时间
private static long startTime = System.currentTimeMillis();
// 时间区间的时间间隔 ms
private static long interval = 1000;
// 每秒限制数量
private static long maxCount = 2;
//累加器
private static AtomicLong accumulator = new AtomicLong();
// 计数判断, 是否超出限制
private static long tryAcquire(long taskId, int turn)
{
long nowTime = System.currentTimeMillis();
//在时间区间之内
if (nowTime < startTime + interval)
{
long count = accumulator.incrementAndGet();
if (count <= maxCount)
{
return count;
} else
{
return -count;
}
} else
{
//在时间区间之外
synchronized (CounterLimiter.class)
{
log.info("新时间区到了,taskId{}, turn {}..", taskId, turn);
// 再一次判断,防止重复初始化
if (nowTime > startTime + interval)
{
accumulator.set(0);
startTime = nowTime;
}
}
return 0;
}
}
//线程池,用于多线程模拟测试
private ExecutorService pool = Executors.newFixedThreadPool(10);
@Test
public void testLimit()
{
// 被限制的次数
AtomicInteger limited = new AtomicInteger(0);
// 线程数
final int threads = 2;
// 每条线程的执行轮数
final int turns = 20;
// 同步器
CountDownLatch countDownLatch = new CountDownLatch(threads);
long start = System.currentTimeMillis();
for (int i = 0; i < threads; i++)
{
pool.submit(() ->
{
try
{
for (int j = 0; j < turns; j++)
{
long taskId = Thread.currentThread().getId();
long index = tryAcquire(taskId, j);
if (index <= 0)
{
// 被限制的次数累积
limited.getAndIncrement();
}
Thread.sleep(200);
}
} catch (Exception e)
{
e.printStackTrace();
}
//等待所有线程结束
countDownLatch.countDown();
});
}
try
{
countDownLatch.await();
} catch (InterruptedException e)
{
e.printStackTrace();
}
float time = (System.currentTimeMillis() - start) / 1000F;
//输出统计结果
log.info("限制的次数为:" + limited.get() +
",通过的次数为:" + (threads * turns - limited.get()));
log.info("限制的比例为:" + (float) limited.get() / (float) (threads * turns));
log.info("运行的时长为:" + time);
}
}
计数器限流的严重问题
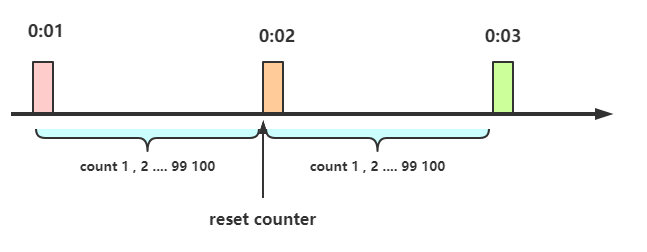
这个算法虽然简单,但是有一个十分致命的问题,那就是临界问题,我们看下图:
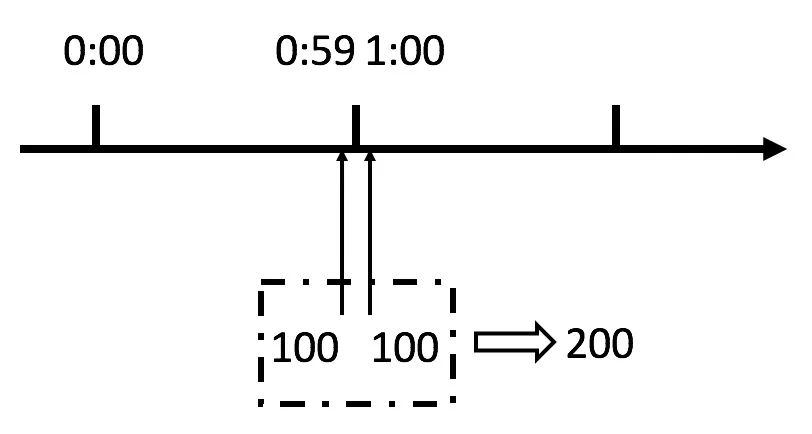
从上图中我们可以看到,假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。
我们刚才规定的是1分钟最多100个请求(规划的吞吐量),也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求, 可以瞬间超过我们的速率限制。
用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
漏桶算法
漏桶算法限流的基本原理为:水(对应请求)从进水口进入到漏桶里,漏桶以一定的速度出水(请求放行),当水流入速度过大,桶内的总水量大于桶容量会直接溢出,请求被拒绝,如图所示。大致的漏桶限流规则如下:(1)进水口(对应客户端请求)以任意速率流入进入漏桶。(2)漏桶的容量是固定的,出水(放行)速率也是固定的。(3)漏桶容量是不变的,如果处理速度太慢,桶内水量会超出了桶的容量,则后面流入的水滴会溢出,表示请求拒绝。
漏桶算法原理
漏桶算法思路很简单:
水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会超过桶可接纳的容量时直接溢出。
可以看出漏桶算法能强行限制数据的传输速率。
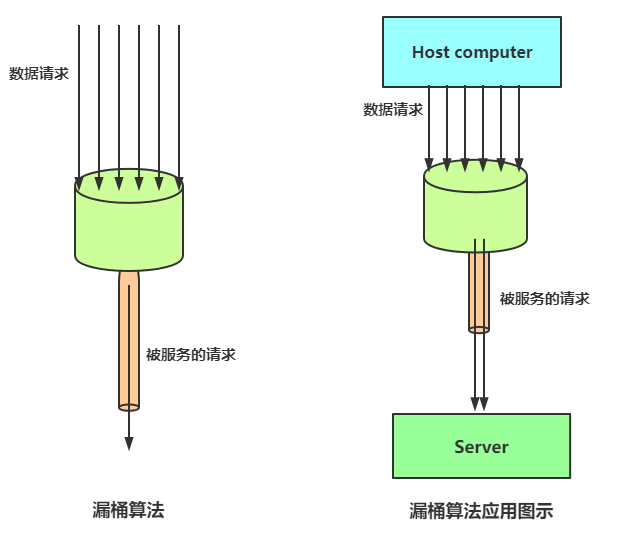
漏桶算法其实很简单,可以粗略的认为就是注水漏水过程,往桶中以任意速率流入水,以一定速率流出水,当水超过桶容量(capacity)则丢弃,因为桶容量是不变的,保证了整体的速率。
以一定速率流出水
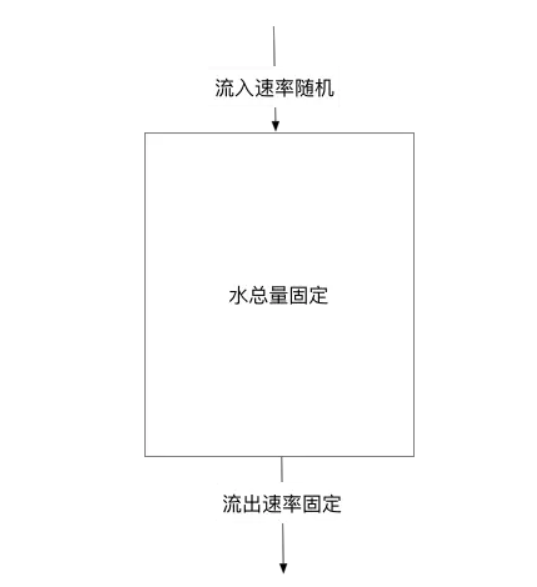
削峰:有大量流量进入时,会发生溢出,从而限流保护服务可用
缓冲:不至于直接请求到服务器, 缓冲压力
消费速度固定 因为计算性能固定
漏桶算法实现
package com.crazymaker.springcloud.ratelimit;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
// 漏桶 限流
@Slf4j
public class LeakBucketLimiter {
// 计算的起始时间
private static long lastOutTime = System.currentTimeMillis();
// 流出速率 每秒 2 次
private static int leakRate = 2;
// 桶的容量
private static int capacity = 2;
//剩余的水量
private static AtomicInteger water = new AtomicInteger(0);
//返回值说明:
// false 没有被限制到
// true 被限流
public static synchronized boolean isLimit(long taskId, int turn) {
// 如果是空桶,就当前时间作为漏出的时间
if (water.get() == 0) {
lastOutTime = System.currentTimeMillis();
water.addAndGet(1);
return false;
}
// 执行漏水
int waterLeaked = ((int) ((System.currentTimeMillis() - lastOutTime) / 1000)) * leakRate;
// 计算剩余水量
int waterLeft = water.get() - waterLeaked;
water.set(Math.max(0, waterLeft));
// 重新更新leakTimeStamp
lastOutTime = System.currentTimeMillis();
// 尝试加水,并且水还未满 ,放行
if ((water.get()) < capacity) {
water.addAndGet(1);
return false;
} else {
// 水满,拒绝加水, 限流
return true;
}
}
//线程池,用于多线程模拟测试
private ExecutorService pool = Executors.newFixedThreadPool(10);
@Test
public void testLimit() {
// 被限制的次数
AtomicInteger limited = new AtomicInteger(0);
// 线程数
final int threads = 2;
// 每条线程的执行轮数
final int turns = 20;
// 线程同步器
CountDownLatch countDownLatch = new CountDownLatch(threads);
long start = System.currentTimeMillis();
for (int i = 0; i < threads; i++) {
pool.submit(() ->
{
try {
for (int j = 0; j < turns; j++) {
long taskId = Thread.currentThread().getId();
boolean intercepted = isLimit(taskId, j);
if (intercepted) {
// 被限制的次数累积
limited.getAndIncrement();
}
Thread.sleep(200);
}
} catch (Exception e) {
e.printStackTrace();
}
//等待所有线程结束
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
float time = (System.currentTimeMillis() - start) / 1000F;
//输出统计结果
log.info("限制的次数为:" + limited.get() +
",通过的次数为:" + (threads * turns - limited.get()));
log.info("限制的比例为:" + (float) limited.get() / (float) (threads * turns));
log.info("运行的时长为:" + time);
}
}
漏桶的问题
漏桶的出水速度固定,也就是请求放行速度是固定的。
网上抄来抄去的说法:
漏桶不能有效应对突发流量,但是能起到平滑突发流量(整流)的作用。
实际上的问题:
漏桶出口的速度固定,不能灵活的应对后端能力提升。比如,通过动态扩容,后端流量从1000QPS提升到1WQPS,漏桶没有办法。
令牌桶限流
令牌桶算法以一个设定的速率产生令牌并放入令牌桶,每次用户请求都得申请令牌,如果令牌不足,则拒绝请求。令牌桶算法中新请求到来时会从桶里拿走一个令牌,如果桶内没有令牌可拿,就拒绝服务。当然,令牌的数量也是有上限的。令牌的数量与时间和发放速率强相关,时间流逝的时间越长,会不断往桶里加入越多的令牌,如果令牌发放的速度比申请速度快,令牌桶会放满令牌,直到令牌占满整个令牌桶,如图所示。
令牌桶限流大致的规则如下:(1)进水口按照某个速度,向桶中放入令牌。(2)令牌的容量是固定的,但是放行的速度不是固定的,只要桶中还有剩余令牌,一旦请求过来就能申请成功,然后放行。(3)如果令牌的发放速度,慢于请求到来速度,桶内就无牌可领,请求就会被拒绝。
总之,令牌的发送速率可以设置,从而可以对突发的出口流量进行有效的应对。
令牌桶算法
令牌桶与漏桶相似,不同的是令牌桶桶中放了一些令牌,服务请求到达后,要获取令牌之后才会得到服务,举个例子,我们平时去食堂吃饭,都是在食堂内窗口前排队的,这就好比是漏桶算法,大量的人员聚集在食堂内窗口外,以一定的速度享受服务,如果涌进来的人太多,食堂装不下了,可能就有一部分人站到食堂外了,这就没有享受到食堂的服务,称之为溢出,溢出可以继续请求,也就是继续排队,那么这样有什么问题呢?
如果这时候有特殊情况,比如有些赶时间的志愿者啦、或者高三要高考啦,这种情况就是突发情况,如果也用漏桶算法那也得慢慢排队,这也就没有解决我们的需求,对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。如图所示,令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
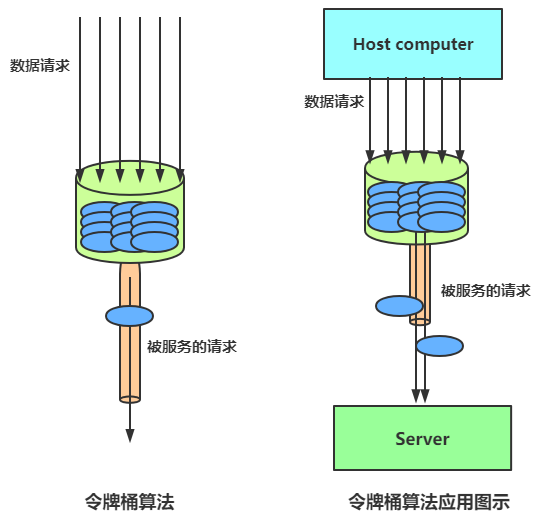
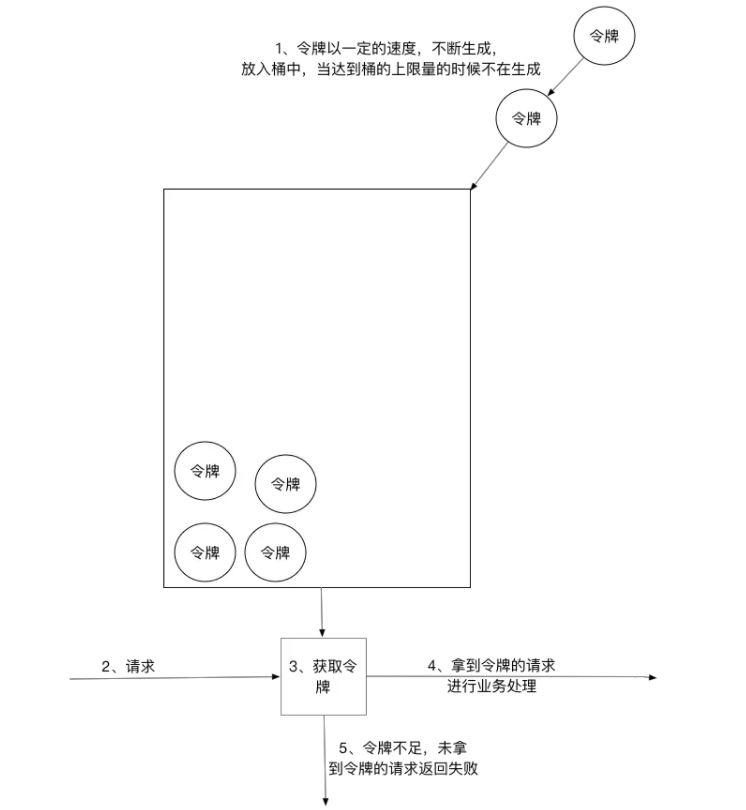
令牌桶算法实现
package com.crazymaker.springcloud.ratelimit;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
// 令牌桶 限速
@Slf4j
public class TokenBucketLimiter {
// 上一次令牌发放时间
public long lastTime = System.currentTimeMillis();
// 桶的容量
public int capacity = 2;
// 令牌生成速度 /s
public int rate = 2;
// 当前令牌数量
public AtomicInteger tokens = new AtomicInteger(0);
;
//返回值说明:
// false 没有被限制到
// true 被限流
public synchronized boolean isLimited(long taskId, int applyCount) {
long now = System.currentTimeMillis();
//时间间隔,单位为 ms
long gap = now - lastTime;
//计算时间段内的令牌数
int reverse_permits = (int) (gap * rate / 1000);
int all_permits = tokens.get() + reverse_permits;
// 当前令牌数
tokens.set(Math.min(capacity, all_permits));
log.info("tokens {} capacity {} gap {} ", tokens, capacity, gap);
if (tokens.get() < applyCount) {
// 若拿不到令牌,则拒绝
// log.info("被限流了.." + taskId + ", applyCount: " + applyCount);
return true;
} else {
// 还有令牌,领取令牌
tokens.getAndAdd( - applyCount);
lastTime = now;
// log.info("剩余令牌.." + tokens);
return false;
}
}
//线程池,用于多线程模拟测试
private ExecutorService pool = Executors.newFixedThreadPool(10);
@Test
public void testLimit() {
// 被限制的次数
AtomicInteger limited = new AtomicInteger(0);
// 线程数
final int threads = 2;
// 每条线程的执行轮数
final int turns = 20;
// 同步器
CountDownLatch countDownLatch = new CountDownLatch(threads);
long start = System.currentTimeMillis();
for (int i = 0; i < threads; i++) {
pool.submit(() ->
{
try {
for (int j = 0; j < turns; j++) {
long taskId = Thread.currentThread().getId();
boolean intercepted = isLimited(taskId, 1);
if (intercepted) {
// 被限制的次数累积
limited.getAndIncrement();
}
Thread.sleep(200);
}
} catch (Exception e) {
e.printStackTrace();
}
//等待所有线程结束
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
float time = (System.currentTimeMillis() - start) / 1000F;
//输出统计结果
log.info("限制的次数为:" + limited.get() +
",通过的次数为:" + (threads * turns - limited.get()));
log.info("限制的比例为:" + (float) limited.get() / (float) (threads * turns));
log.info("运行的时长为:" + time);
}
}
令牌桶的好处
令牌桶的好处之一就是可以方便地应对 突发出口流量(后端能力的提升)。
比如,可以改变令牌的发放速度,算法能按照新的发送速率调大令牌的发放数量,使得出口突发流量能被处理。
Guava RateLimiter
Guava是Java领域优秀的开源项目,它包含了Google在Java项目中使用一些核心库,包含集合(Collections),缓存(Caching),并发编程库(Concurrency),常用注解(Common annotations),String操作,I/O操作方面的众多非常实用的函数。Guava的 RateLimiter提供了令牌桶算法实现:平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)实现。
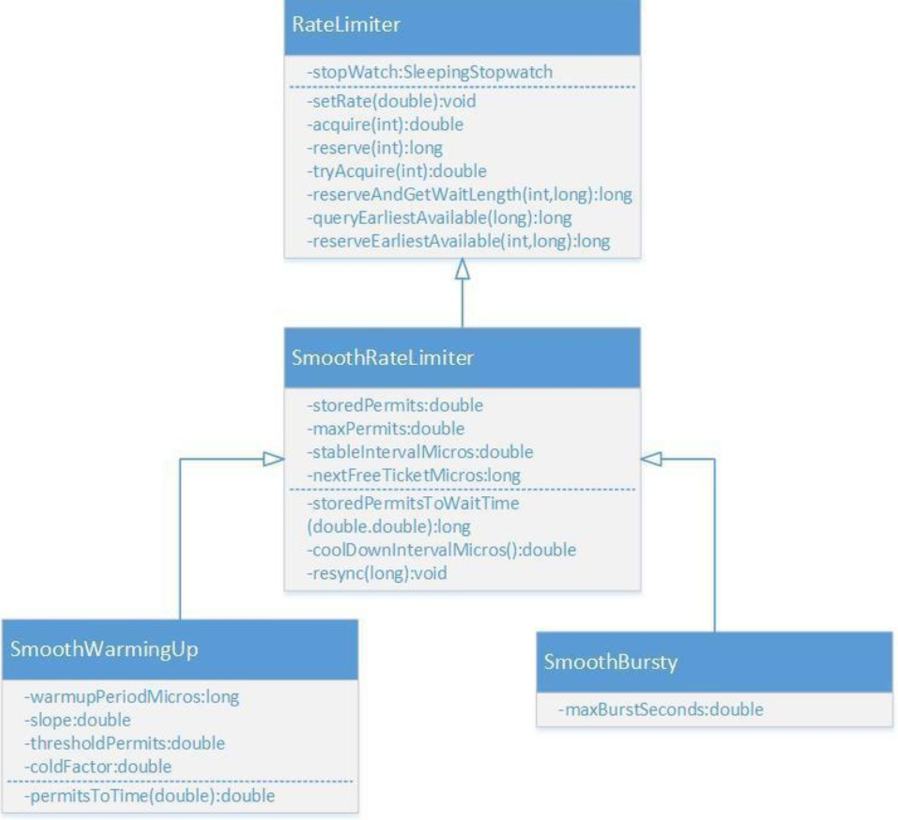
RateLimiter的类图如上所示,
Nginx漏桶限流
Nginx限流的简单演示
每六秒才处理一次请求,如下
limit_req_zone $arg_sku_id zone=skuzone:10m rate=6r/m;
limit_req_zone $http_user_id zone=userzone:10m rate=6r/m;
limit_req_zone $binary_remote_addr zone=perip:10m rate=6r/m;
limit_req_zone $server_name zone=perserver:1m rate=6r/m;
从请求参数里边,提前参数做限流
这是从请求参数里边,提前参数,进行限流的次数统计key。
在http块里边定义限流的内存区域 zone。
limit_req_zone $arg_sku_id zone=skuzone:10m rate=6r/m;
limit_req_zone $http_user_id zone=userzone:10m rate=6r/m;
limit_req_zone $binary_remote_addr zone=perip:10m rate=6r/m;
limit_req_zone $server_name zone=perserver:1m rate=10r/s;
在location块中使用 限流zone,参考如下:
# ratelimit by sku id
location = /ratelimit/sku {
limit_req zone=skuzone;
echo "正常的响应";
}
测试
[root@cdh1 ~]# /vagrant/LuaDemoProject/sh/linux/openresty-restart.sh
shell dir is: /vagrant/LuaDemoProject/sh/linux
Shutting down openrestry/nginx: pid is 13479 13485
Shutting down succeeded!
OPENRESTRY_PATH:/usr/local/openresty
PROJECT_PATH:/vagrant/LuaDemoProject/src
nginx: [alert] lua_code_cache is off; this will hurt performance in /vagrant/LuaDemoProject/src/conf/nginx-seckill.conf:90
openrestry/nginx starting succeeded!
pid is 14197
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
正常的响应
root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
正常的响应
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
正常的响应
从Header头部提前参数
1、nginx是支持读取非nginx标准的用户自定义header的,但是需要在http或者server下开启header的下划线支持:
underscores_in_headers on;
2、比如我们自定义header为X-Real-IP,通过第二个nginx获取该header时需要这样:
$http_x_real_ip; (一律采用小写,而且前面多了个http_)
underscores_in_headers on;
limit_req_zone $http_user_id zone=userzone:10m rate=6r/m;
server {
listen 80 default;
server_name nginx.server *.nginx.server;
default_type 'text/html';
charset utf-8;
# ratelimit by user id
location = /ratelimit/demo {
limit_req zone=userzone;
echo "正常的响应";
}
location = /50x.html{
echo "限流后的降级内容";
}
error_page 502 503 =200 /50x.html;
}测试
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
正常的响应
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER_ID:2" http://cdh1/ratelimit/demo
正常的响应
[root@cdh1 ~]# curl -H "USER_ID:2" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]#
[root@cdh1 ~]# curl -H "USER_ID:2" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:3" http://cdh1/ratelimit/demo
正常的响应
[root@cdh1 ~]# curl -H "USER-ID:3" http://cdh1/ratelimit/demo
限流后的降级内容
Nginx漏桶限流的三个细分类型,即burst、nodelay参数详解
每六秒才处理一次请求,如下
limit_req_zone $arg_user_id zone=limti_req_zone:10m rate=10r/m;
不带缓冲队列的漏桶限流
`limit_req zone=limti_req_zone;``
-
严格依照在limti_req_zone中配置的rate来处理请求
-
超过rate处理能力范围的,直接drop
-
表现为对收到的请求无延时
假设1秒内提交10个请求,可以看到一共10个请求,9个请求都失败了,直接返回503,
接着再查看 /var/log/nginx/access.log,印证了只有一个请求成功了,其它就是都直接返回了503,即服务器拒绝了请求。

带缓冲队列的漏桶限流
`limit_req zone=limti_req_zone burst=5;``
-
依照在limti_req_zone中配置的rate来处理请求
-
同时设置了一个大小为5的缓冲队列,在缓冲队列中的请求会等待慢慢处理
-
超过了burst缓冲队列长度和rate处理能力的请求被直接丢弃
-
表现为对收到的请求有延时
假设1秒内提交10个请求,则可以发现在1s内,在服务器接收到10个并发请求后,先处理1个请求,同时将5个请求放入burst缓冲队列中,等待处理。而超过(burst+1)数量的请求就被直接抛弃了,即直接抛弃了4个请求。burst缓存的5个请求每隔6s处理一次。
接着查看 /var/log/nginx/access.log日志

带瞬时处理能力的漏桶限流
limit_req zone=req_zone burst=5 nodelay;
如果设置nodelay,会在瞬时提供处理(burst + rate)个请求的能力,请求数量超过(burst + rate)的时候就会直接返回503,峰值范围内的请求,不存在请求需要等待的情况。
假设1秒内提交10个请求,则可以发现在1s内,服务器端处理了6个请求(峰值速度:burst+10s内一个请求)。对于剩下的4个请求,直接返回503,在下一秒如果继续向服务端发送10个请求,服务端会直接拒绝这10个请求并返回503。
接着查看 /var/log/nginx/access.log日志

可以发现在1s内,服务器端处理了6个请求(峰值速度:burst+原来的处理速度)。对于剩下的4个请求,直接返回503。
但是,总数额度和速度 * 时间保持一致, 就是额度用完了,需要等到一个有额度的时间段,才开始接收新的请求。如果一次处理了5个请求,相当于占了30s的额度,
6*5=30。因为设定了6s处理1个请求,所以直到30 s 之后,才可以再处理一个请求,即如果此时向服务端发送10个请求,会返回9个503,一个200
分布式限流组件
但是Nginx的限流指令只能在同一块内存区域有效,而在生产场景中秒杀的外部网关往往是多节点部署,所以这就需要用到分布式限流组件。
高性能的分布式限流组件可以使用Redis+Lua来开发,京东的抢购就是使用Redis+Lua完成的限流。并且无论是Nginx外部网关还是Zuul内部网关,都可以使用Redis+Lua限流组件。
理论上,接入层的限流有多个维度:
(1)用户维度限流:在某一时间段内只允许用户提交一次请求,比如可以采取客户端IP或者用户ID作为限流的key。
(2)商品维度的限流:对于同一个抢购商品,在某个时间段内只允许一定数量的请求进入,可以采取秒杀商品ID作为限流的key。
什么时候用nginx限流:
用户维度的限流,可以在ngix 上进行,因为使用nginx限流内存来存储用户id,比用redis 的key,来存储用户id,效率高。
什么时候用redis+lua分布式限流:
商品维度的限流,可以在redis上进行,不需要大量的计算访问次数的key,另外,可以控制所有的接入层节点的访问秒杀请求的总量。
redis+lua分布式限流组件
--- 此脚本的环境:redis 内部,不是运行在 nginx 内部
---方法:申请令牌
--- -1 failed
--- 1 success
--- @param key key 限流关键字
--- @param apply 申请的令牌数量
local function acquire(key, apply)
local times = redis.call('TIME');
-- times[1] 秒数 -- times[2] 微秒数
local curr_mill_second = times[1] * 1000000 + times[2];
curr_mill_second = curr_mill_second / 1000;
local cacheInfo = redis.pcall("HMGET", key, "last_mill_second", "curr_permits", "max_permits", "rate")
--- 局部变量:上次申请的时间
local last_mill_second = cacheInfo[1];
--- 局部变量:之前的令牌数
local curr_permits = tonumber(cacheInfo[2]);
--- 局部变量:桶的容量
local max_permits = tonumber(cacheInfo[3]);
--- 局部变量:令牌的发放速率
local rate = cacheInfo[4];
--- 局部变量:本次的令牌数
local local_curr_permits = 0;
if (type(last_mill_second) ~= 'boolean' and last_mill_second ~= nil) then
-- 计算时间段内的令牌数
local reverse_permits = math.floor(((curr_mill_second - last_mill_second) / 1000) * rate);
-- 令牌总数
local expect_curr_permits = reverse_permits + curr_permits;
-- 可以申请的令牌总数
local_curr_permits = math.min(expect_curr_permits, max_permits);
else
-- 第一次获取令牌
redis.pcall("HSET", key, "last_mill_second", curr_mill_second)
local_curr_permits = max_permits;
end
local result = -1;
-- 有足够的令牌可以申请
if (local_curr_permits - apply >= 0) then
-- 保存剩余的令牌
redis.pcall("HSET", key, "curr_permits", local_curr_permits - apply);
-- 为下次的令牌获取,保存时间
redis.pcall("HSET", key, "last_mill_second", curr_mill_second)
-- 返回令牌获取成功
result = 1;
else
-- 返回令牌获取失败
result = -1;
end
return result
end
--eg
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , acquire 1 1
-- 获取 sha编码的命令
-- /usr/local/redis/bin/redis-cli -a 123456 script load "$(cat /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua)"
-- /usr/local/redis/bin/redis-cli -a 123456 script exists "cf43613f172388c34a1130a760fc699a5ee6f2a9"
-- /usr/local/redis/bin/redis-cli -a 123456 evalsha "cf43613f172388c34a1130a760fc699a5ee6f2a9" 1 "rate_limiter:seckill:1" init 1 1
-- /usr/local/redis/bin/redis-cli -a 123456 evalsha "cf43613f172388c34a1130a760fc699a5ee6f2a9" 1 "rate_limiter:seckill:1" acquire 1
--local rateLimiterSha = "e4e49e4c7b23f0bf7a2bfee73e8a01629e33324b";
---方法:初始化限流 Key
--- 1 success
--- @param key key
--- @param max_permits 桶的容量
--- @param rate 令牌的发放速率
local function init(key, max_permits, rate)
local rate_limit_info = redis.pcall("HMGET", key, "last_mill_second", "curr_permits", "max_permits", "rate")
local org_max_permits = tonumber(rate_limit_info[3])
local org_rate = rate_limit_info[4]
if (org_max_permits == nil) or (rate ~= org_rate or max_permits ~= org_max_permits) then
redis.pcall("HMSET", key, "max_permits", max_permits, "rate", rate, "curr_permits", max_permits)
end
return 1;
end
--eg
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , init 1 1
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua "rate_limiter:seckill:1" , init 1 1
---方法:删除限流 Key
local function delete(key)
redis.pcall("DEL", key)
return 1;
end
--eg
-- /usr/local/redis/bin/redis-cli --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , delete
local key = KEYS[1]
local method = ARGV[1]
if method == 'acquire' then
return acquire(key, ARGV[2], ARGV[3])
elseif method == 'init' then
return init(key, ARGV[2], ARGV[3])
elseif method == 'delete' then
return delete(key)
else
--ignore
end
在redis中,为了避免重复发送脚本数据浪费网络资源,可以使用script load命令进行脚本数据缓存,并且返回一个哈希码作为脚本的调用句柄,
每次调用脚本只需要发送哈希码来调用即可。
分布式令牌限流实战
可以使用redis+lua,实战的简单案例:
令牌按照1个每秒的速率放入令牌桶,桶中最多存放2个令牌,那系统就只会允许持续的每秒处理2个请求,
或者每隔2 秒,等桶中2 个令牌攒满后,一次处理2个请求的突发情况,保证系统稳定性。
商品维度的限流
当秒杀商品维度的限流,当商品的流量,远远大于涉及的流量时,开始随机丢弃请求。
Nginx的令牌桶限流脚本getToken_access_limit.lua执行在请求的access阶段,但是,该脚本并没有实现限流的核心逻辑,仅仅调用缓存在Redis内部的rate_limiter.lua脚本进行限流。
getToken_access_limit.lua脚本和rate_limiter.lua脚本的关系,具体如图10-17所示。
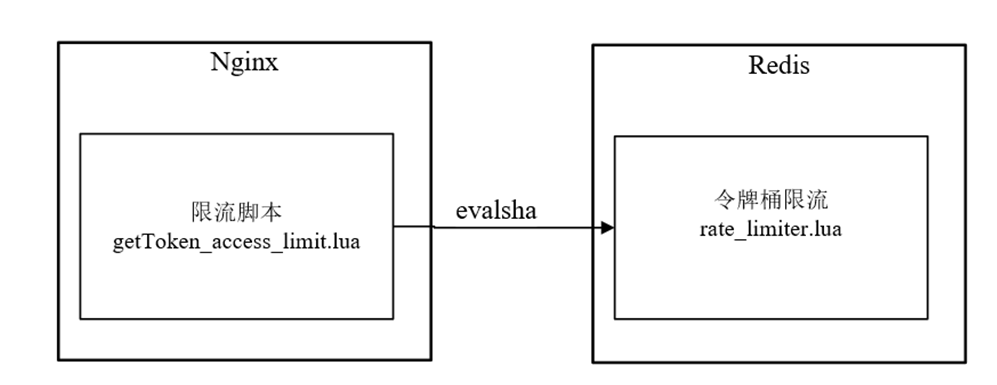
图10-17 getToken_access_limit.lua脚本和rate_limiter.lua脚本关系
什么时候在Redis中加载rate_limiter.lua脚本呢?
和秒杀脚本一样,该脚本是在Java程序启动商品秒杀时,完成其在Redis的加载和缓存的。
还有一点非常重要,Java程序会将脚本加载完成之后的sha1编码,去通过自定义的key(具体为"lua:sha1:rate_limiter")缓存在Redis中,以方便Nginx的getToken_access_limit.lua脚本去获取,并且在调用evalsha方法时使用。
注意:使用redis集群,因此每个节点都需要各自缓存一份脚本数据
/**
* 由于使用redis集群,因此每个节点都需要各自缓存一份脚本数据
* @param slotKey 用来定位对应的slot的slotKey
*/
public void storeScript(String slotKey){
if (StringUtils.isEmpty(unlockSha1) || !jedisCluster.scriptExists(unlockSha1, slotKey)){
//redis支持脚本缓存,返回哈希码,后续可以继续用来调用脚本
unlockSha1 = jedisCluster.scriptLoad(DISTRIBUTE_LOCK_SCRIPT_UNLOCK_VAL, slotKey);
}
}
常见的限流组件
redission分布式限流采用令牌桶思想和固定时间窗口,trySetRate方法设置桶的大小,利用redis key过期机制达到时间窗口目的,控制固定时间窗口内允许通过的请求量。
spring cloud gateway集成redis限流,但属于网关层限流
参考链接
系统架构知识图谱
https://www.processon.com/view/link/60fb9421637689719d246739
秒杀系统的架构
https://www.processon.com/view/link/61148c2b1e08536191d8f92f
面向对象的优点有哪些
面向对象是一种编程方法论,它通过将数据和行为封装在对象中,使得代码更易于理解、扩展和维护。
在面向对象的方法中,程序被视为对象的集合,对象之间互相通信和协作,实现系统的功能。
面向对象方法与传统的结构化方法有着显著区别。该思想提倡运用人类的思维方式,从现实世界中存在的事物出发来构造软件系统,
面向对象方法建立在“对象”概念基础上,以对象为中心,以类和继承为构造机制来设计和构造软件系统。
面向对象的优点有:
1.可重用性好
面向对象方法具有的继承性和封装性支持软件复用。有两种方法可以重复使用一个对象类。一是创建类的实例,从而直接使用它;二是从它派生出一个满足需要的新类,子类可以重用其父类的数据结构和程序代码,并且可以在父类的基础上方便地修改和扩充,而且子类的修改并不影响父类的使用。
2.可扩展性好
面向对象的程序可以随着需求的增加而扩展,因为对象可以添加新的属性和方法来满足新的需求。
3.与人类习惯的思维方法一致
传统的结构化软件开发方法是面向过程的,以算法为核心,数据和过程作为相互独立的部分,数据和过程分离,忽略了数据和操作之间的内在的联系,问题空间和解空间并不是一致的。
面向对象的方法是以对象为核心,尽可能接近人类习惯的抽象思维方法,并尽量一致地描述问题空间和解空间,从而自然而然地解决问题。
4.系统的稳定性好
面向对象方法用对象模拟问题域中的实体,以对象间的联系刻画实体间联系。当系统的功能需求变化时,不会引起软件结构的整体变化,仅需做一些局部的修改。
由于现实世界中的实体是相对稳定的,因此,以对象为中心构造的软件系统也会比较稳定。
5.较易于开发大型软件产品
用面向对象方法开发大型软件时,把大型软件产品看作是一系列相互独立的小产品,采用RUP(统一开发过程)的迭代开发模型,可以降低开发时的技术难度和开发工作管理的难度。
6.可维护性好
由于面向对象的软件稳定性比较好,容易修改、容易理解、易于测试和调试,因而软件的可维护性就会比较好。
聊一下数据结构
数据结构是计算机科学中用于组织、存储和操作数据的方法。在编程中,选择正确的数据结构可以极大地提高代码的效率和性能。常见的数据结构包括:
-
数组(Array):线性结构,通过下标访问元素。
-
链表(Linked List):线性结构,通过指针连接元素。
-
栈(Stack):线性结构,先进后出(LIFO)的数据结构。
-
队列(Queue):线性结构,先进先出(FIFO)的数据结构。
-
树(Tree):非线性结构,由节点和边组成。
-
图(Graph):非线性结构,由节点和边组成。
-
堆(Heap):非线性结构,可以快速找到最大或最小值的数据结构。
-
哈希表(Hash Table):根据关键码值(Key Value)进行访问的数据结构。
-
散列表(Hash Map):根据关键码值(Key Value)进行访问并且可以自动排序的数据结构。
-
元组树(Trie Tree):用于字符串搜索和匹配的数据结构。
说一下数组、链表 的特点和使用场景
数组和链表是常见的数据结构,它们在很多编程语言中都有着广泛的应用。下面分别简述它们的特点和应用场景。
数组

数组是一种线性数据结构,它由一组按顺序排列的元素组成。
数组中的每个元素都有一个唯一的索引,可以使用索引来访问和修改该元素。
数组通常用于数值计算、图像处理等需要高效地访问和操作元素的场景。
数组是一种线性数据结构,它是由同一种数据类型组成的一系列元素的集合。
数组的大小是在定义时确定的,一旦大小确定,就不能再改变。
数组的主要特点包括:
-
固定大小:数组的大小是在定义时确定的,一旦大小确定,就不能再改变。
-
随机访问:数组中的元素可以通过一个唯一的索引值来访问,因此可以进行随机访问。
-
简单高效:数组的操作比较简单,例如插入、删除、查找等操作都可以在 O(1) 的时间复杂度内完成。
下面是一个简单的数组实现:
javaCopy codepublic class Array {
private int size;
private int[ ] data;
public Array(int size) {
this.size = size;
this.data = new int[size];
}
public int get(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException("Index out of range");
}
return data[index];
}
public void set(int index, int value) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException("Index out of range");
}
data[index] = value;
}
public int length() {
return size;
}
}
数组的优缺点
-
插入数据:时间复杂度O(1),当我们在数组某个位置需要插入元素时,首先我们可以查询到数组的第一个元素的内存地址,由于内存地址是连续的,比如我们需要在第8个位置插入,则可以直接找到索引为8的内存地址即可,但是如果是在中间插入则需要把后面的数据向后移动,比较耗时
-
查询第几个数据:时间复杂度O(1),和插入的原理一致,基于第一个内存地址即可快速查询
-
查询某个值的数据:时间复杂度O(n),查询某个值的数据时,只能从头到尾遍历数据再进行对比,需要遍历所有数据
链表
链表也是一种线性数据结构。

链表是一种动态数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。链表可以在任意位置插入和删除节点,因此它非常灵活。链表通常用于实现程序的数据结构、网络编程等场景。
链表的主要特点包括:
-
动态大小:链表的大小是在运行时确定的,可以随时添加或删除节点。
-
插入删除方便:链表的操作相对于数组来说更加灵活,例如插入、删除、查找等操作都可以在 O(1) 的时间复杂度内完成。
-
内存占用相对较大:由于链表需要额外的指针来指向下一个节点,因此它的内存占用相对较大。
总之,数组和链表都有各自的优缺点,在实际应用中需要根据具体情况选择合适的数据结构。
下面是一个简单的链表实现:
javaCopy codepublic class LinkedList {
private Node head;
public LinkedList() {
this.head = null;
}
public void append(int value) {
Node newNode = new Node(value);
if (head == null) {
head = newNode;
return;
}
Node current = head;
while (current.next != null) {
current = current.next;
}
current.next = newNode;
}
public void prepend(int value) {
Node newNode = new Node(value);
newNode.next = head;
head = newNode;
}
public void insertAfterNode(Node prevNode, int value) {
if (prevNode == null) {
System.out.println("Previous node is not in the list");
return;
}
Node newNode = new Node(value);
newNode.next = prevNode.next;
prevNode.next = newNode;
}
public void deleteNode(int value) {
Node curNode = head;
if (curNode == null) {
System.out.println("Previous node is not in the list");
return;
}
while (curNode.next != null) {
curNode = curNode.next;
}
if (curNode.value == value) {
curNode.next = curNode.next.next;
return;
}
Node prevNode = null;
while (curNode != null) {
if (curNode.value == value) {
prevNode = curNode;
curNode = curNode.next;
} else {
prevNode = curNode;
curNode = curNode.next;
}
}
if (prevNode != null) {
prevNode.next = curNode.next;
} else {
head = curNode.next;
}
}
}
链表的优缺点
-
插入数据:时间复杂度O(1),比如在某个数据后面插入数据,则需要把插入前数据的指针指向要插入的数据,把要插入的数据的指针指向下一个数据即可,不需要数据进行移动
-
查询第几个数据:时间复杂度O(n),需要遍历链表查询,因为内存地址是不连续的
-
查询某个值的数据:时间复杂度O(n),需要遍历链表查询
二者的区别
-
数组适合用于需要高效地访问和操作元素的场景,如数值计算、图像处理等;
-
而链表适合用于需要频繁插入和删除元素的场景,如网络编程等。
-
在实际编写代码时,需要根据具体的场景和需求选择合适的数据结构。
说一下线程池
线程池(Thread Pool)是一种多线程处理方式,它可以提高程序的并发性和效率。线程池中维护着一组已经创建好的线程,当有任务需要执行时,直接从线程池中取出一个空闲的线程来执行任务,如果没有空闲的线程可用,则将任务放入任务队列中等待执行。
Java中可以通过Executor框架实现线程池,具体步骤如下:
-
创建一个ExecutorService对象,可以使用Executors工厂类的静态方法获取一个具有指定线程数的ExecutorService对象。
-
将任务提交给ExecutorService对象,可以使用submit()方法将Runnable或Callable对象提交给ExecutorService对象。
-
使用ExecutorService对象的execute()方法执行任务,该方法会返回一个Future对象,通过该Future对象可以获取任务执行的结果。
-
当不再需要使用ExecutorService对象时,调用 shutdown()方法关闭线程池。
Java中常用的线程池实现类有ThreadPoolExecutor和ScheduledThreadPoolExecutor。
ThreadPoolExecutor是一个基于线程池的执行器,它可以存储和重用线程,并且可以设置线程的优先级、队列大小、拒绝策略等。
ScheduledThreadPoolExecutor是一个支持延时或周期性执行任务的线程池。它可以设置任务的延时时间、执行周期和执行次数等。
通过使用这些线程池实现类,可以轻松地创建和管理线程池,并执行任务。以下是一个使用ThreadPoolExecutor实现简单计算器的示例代码:
javaCopy codeimport java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Calculator {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(5);
for(int i=0; i<5; i++) {
executor.execute(new CalculatorTask());
}
executor.shutdown();
}
}
class CalculatorTask implements Runnable {
public void run() {
int num1 = 5;
int num2 = 10;
int sum = num1 + num2;
System.out.println("The sum of " + num1 + " and " + num2 + " is " + sum);
}
}
这个示例创建了一个包含5个线程的线程池,并使用submit()方法将5个CalculatorTask对象提交到线程池中执行。每个线程执行完毕后,线程池会自动调用shutdown()方法,以关闭线程池。这样就可以轻松地实现一个简单的计算器了。
说一下 MySQL 索引
一、索引简介
1、索引是什么?
MySQL官方对索引的定义:索引(Index)是帮助MySQL高效获取数据的数据结构,这些数据结构以某种方式引用(指向)数据。索引的本质是:数据结构。可以简单理解为“排好序的快速查找数据结构”
一个非常恰当的比喻就是书的目录页与书的正文内容之间的关系,为了方便查找书中的内容,通过对内容建立索引形成目录。因此,首先你要明白的一点就是,索引它也是一个文件,它是要占据物理空间的。
比如对于MyISAM存储引擎来说:
.frm 后缀的文件存储的是表结构。
.myd 后缀的文件存储的是表数据。
.myi 后缀的文件存储的就是索引文件。
对于InnoDB 存储引擎来说:
.frm 后缀的文件存储的是表结构。
.ibd 后缀的文件存放索引文件和数据(需要开启innodb_file_per_table 参数)
因此,当你对一张表建立索引时,索引文件的大小也会改变,当你数据表中的数据因为增删改变化时,索引文件也会变化的,只不过MySQL会自动维护索引,这个过程不需要你介入,这也是为什么不恰当的索引会影响MySQL性能的原因。
下面是一种可能的索引方式示例:
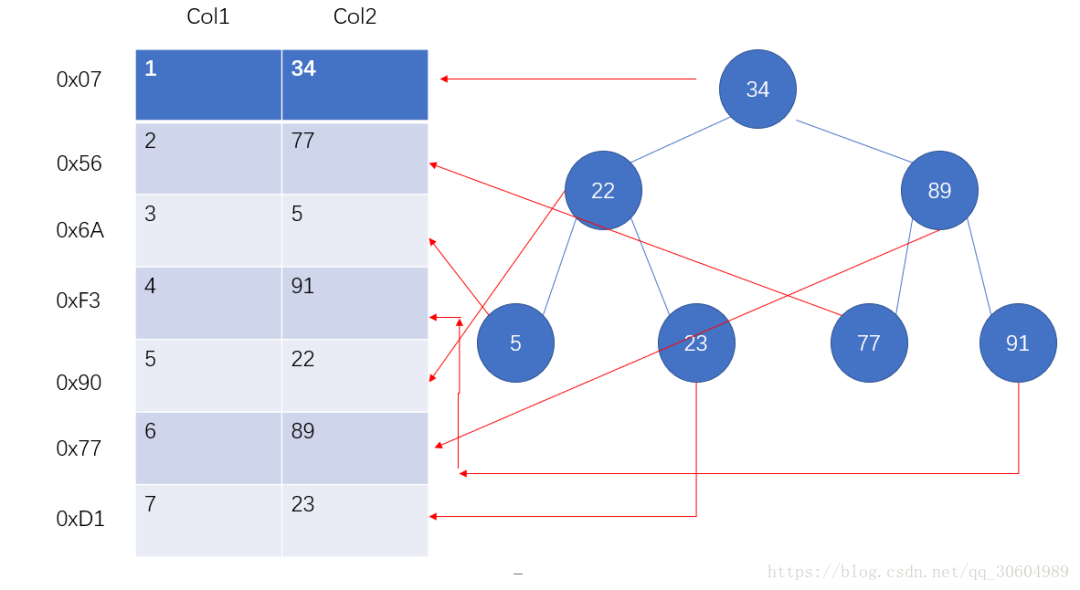
左边是数据表,最左边是数据记录的物理地址。
为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针。这样就可以运用二叉查找在一定复杂度内找到相应的数据,从而快速的检索出符合条件的记录。
2、索引的优点和缺点
优势:
-
建立索引可以大大提高检索的数据,以及减少表的检索行数
-
在表连接的连接条件 可以加速表与表直接的相连
劣势:
-
索引存在于磁盘中,会占据物理空间。
-
提高了查询速度,同时却会降低更新表的速度,如对表进行UPDATE、INSERT和DELETE。因为更新表的时候MySQL不仅要保存数据,还要更新索引文件每次更新添加了索引列的字段。
3、不同表中的索引名可以重复建立
mysql中不同表的相同字段索引是可以重名的,因为索引文件一表一个;
命名规则:
普通索引:idx_字段名
唯一索引:ux_字段名
-
索引是按照特定查找算法的数据结构把数据表中的数据放在索引文件中,以便于快速查找;
-
索引存在于磁盘中,会占据物理空间。
我们平时说的索引,如果没有特别指明,都是B树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚簇索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。当然,除了B+树这种类型的索引外,还有哈希索引(hash index)等 。
二、索引分类
1、普通索引
这是这基本的索引,它没有任何限制,MyISAM 中默认的 B-tree 类型的索引,基本的索引类型,没有唯一性的限制,允许为NULL值。
# 直接创建索引
CREATE INDEX index_name ON table(column(length))
# 修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name (column(length))
# 创建表的时候同时创建索引
CREATE TABLE table_name ( \*,INDEX index_name title(length))
# 删除索引
DROP INDEX index_name ON table
2、唯一索引
与普通索引一致,不同的是索引值必须唯一,允许有空值
# 直接创建索引
CREATE UNIQUE INDEX index_name ON table(column(length))
# 修改表结构的方式添加索引
ALTER TABLE table_name ADD UNIQUE INDEX index_name (column(length))
# 创建表的时候同时创建索引
CREATE TABLE table_name ( \*,UNIQUE index_name title(length))
3、全文索引
FULLTEXT 索引仅 MyISAM 引擎支持 他们可以从CHAR、VARCHAR或TEXT列中作为CREATE TABLE语句的一部分被创建,或是随后使用ALTER TABLE 或CREATE INDEX被添加,不过切记对于大容量的数据表,生成全文索引是一个非常消耗时间非常消耗硬盘空间的做法
# 直接创建索引
CREATE FULLTEXT INDEX index_content ON article(content)
# 修改表结构的方式添加索引
ALTER TABLE article ADD FULLTEXT index_content(content)
# 创建表的时候同时创建索引
CREATE TABLE table_name ( \*,FULLTEXT (content))
4、组合索引(最左前缀,不属于分类)
平时用的SQL查询语句一般都有比较多的限制条件,所以为了进一步榨取MySQL的效率,就要考虑建立组合索引。
ALTER TABLE article ADD INDEX index_titme_time (title(50),time(10))
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
建立这样的组合索引,其实是相当于分别建立了下面两组组合索引:–title,time–title
5、主键索引(不属于分类)
数据列不允许重复,不允许为NULL,一个表只能有一个主键。
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
三、查看索引
show index from 表名
show keys from 表名
desc 表名
四、索引的类型
上面说到,索引文件时按照不同的数据结构来存储的,数据结构的不同也产生了不同的索引类型,常见的索引类型包括
B-Tree索引、哈希索引、空间数据索引(R-Tree) 、全文索引
1、B-tree索引
B-Tree索引是最常用的一种索引,如果没有指定特定的类型,那么多半就是B-Tree索引,事实上,很多搜索引擎使用的是它的变种B+Tree,这是对B-Tree的一个优化
绝大多数的存储引擎,比如MyISAM和InnoDB都支持这种索引,因此说它是应用最广泛,最常用的一种索引方式,但是不同的存储引擎在具体实现时会稍有不同,比如MyISAM会使用前缀压缩的方式对索引进行压缩,InnoDB则不会。B-tree系统,可理解为”排好序的快速查找结构”.
下图展示了B-Tree索引是如何存储被索引的数据的:
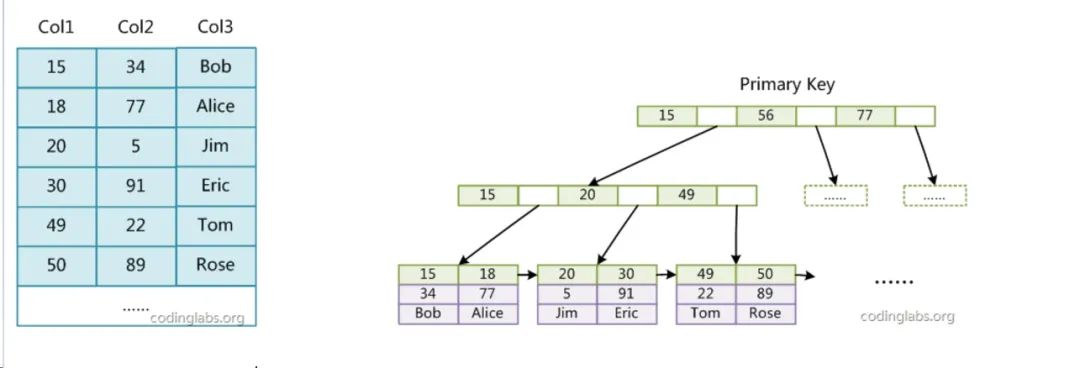
说明:
左图是一个包含三列的数据表,右图则展示了数据是如何被索引的。
可以看出B-Tree是对索引列是按照顺序存储的,每个叶子节点指向被索引的数据,这也是B-Tree索引支持范围查找数据的原因。
2、hash索引
相比于B-Tree索引,哈希索引的实现就比较简单了,它是基于哈希表来实现的,对于要索引的列,存储引擎会计算出一一对应的哈希码,然后把哈希码存放在哈希表中作为key,value值是指向该行数据的指针。
下图是简单的原理展示:

说明:
左边紫色图表示一个二列的数据表。
中间表示对fname列进行哈希索引,计算出哈希值。
右边绿色图表示把生成的哈希值存放于哈希表中。
当我们执行以下查询时:
select * from testTable where fname = "mary";
MySQL会首先计算查询条件mary的哈希值,然后到哈希表中去找该哈希值,如果找到了根据对应的指针也就找到了需要寻找的数据行。
哈希表的优势与限制:
-
优势
在memory表里,默认是hash索引, 只需比对哈希值,因此速度非常快,理论查询时间复杂度为O(1),性能优势明显;
-
限制
-
不支持任何范围查询,比如where price > 150,因为是基于哈希计算,支持等值比较。
-
哈希表是无序存储的,因此索引数据无法用于排序。
-
主流存储引擎不支持该类型,比如MyISAM和InnoDB。哈希索引只有Memory, NDB两种引擎支持。
-
必须回行.就是说 通过索引拿到数据位置,必须回到表中取数据
因此,哈希索引虽然速度快,但其实使用很受限,只适用于某些特殊的场合。
3、空间数据索引(R-Tree)
空间索引可用于地理数据存储,它需要GIS相关函数的支持,由于MySQL的GIS支持并不完善,所以该索引方式在MySQL中很少有人使用。
4、索引总结
-
B-Tree索引使用最广泛,主流引擎都支持。
-
哈希索引性能高,适用于特殊场合。
-
R-Tree不常用。
-
全文索引fulltext 适用于海量数据的关键字模糊搜索,不可能使用like吧,不过对中文貌似没有什么效果,可以使用专业的搜索引擎比如Sphinx或Solr。
五、索引和存储引擎之间的关系
在MySQL中,索引是在存储引擎中实现的,并不是所有的存储引擎都支持所有的索引类型,比如哈希索引,MyISAM和InnoDB是不支持的;同样,即使对于同一类型的索引,不同的存储引擎实现的方式也可能是不同的,比如MyISAM和InnoDB对B-Tree索引,具体的实现是有差别的。
总结:
-
不同的存储引擎可能支持不同的索引类型;
-
不同的存储引擎对同一中索引类型可能有不同的实现方式。
说说索引底层原理 (哈希索引和 B+树)
索引底层原理是指数据库如何实现索引的过程。在 MySQL 中,常见的索引类型有 B-Tree 索引和哈希索引。
B-Tree 索引是一种平衡树形结构,它通过将数据分成多个块来存储索引信息。每个节点都包含一个键值和指向子节点的指针。B-Tree 索引可以保证查询时沿着树形结构向下遍历即可找到目标数据行,因此具有较好的查询性能。
哈希索引则是一种基于哈希表的数据结构,它通过将键值映射到哈希表中的一个位置来存储索引信息。哈希索引适用于等值查询,即查询条件只涉及到键的值而不涉及键的顺序。由于哈希表的查找时间复杂度为 O(1),因此哈希索引具有非常快的查询性能。但是,哈希索引不支持范围查询和排序操作,因此在实际应用中需要根据具体需求进行选择。
无论是 B-Tree 索引还是哈希索引,它们都是通过在内存中创建一个索引结构来加速数据的检索操作。在查询时,数据库会首先检查缓存中的索引结构是否存在,如果存在则直接返回结果;如果不存在,则需要从磁盘中读取数据文件并构建索引结构,然后再进行查询操作。
需要注意的是,索引会对插入、更新和删除操作的性能产生影响。因此,在创建索引时需要根据具体的业务需求和数据特点进行权衡和选择。同时,也需要定期维护索引,删除不必要的索引以及重建不再使用的索引等操作。
说说B+树和红黑树时间复杂度
B+树和红黑树都是常用的数据结构,用于实现索引。它们都具有平衡性,可以保证在进行插入、删除、查找等操作时的复杂度为O(logn)。
下面分别介绍B+树和红黑树的时间复杂度:
B+树
B+树是一种多路搜索树,它通过将数据分成多个块来存储索引信息。每个节点都包含一个键值和指向子节点的指针。B+树的查询、插入和删除操作的时间复杂度均为O(logn),其中查询操作的时间复杂度为O(logn),因为B+树的叶子节点之间有指针相连,可以沿着指针逐个遍历到叶子节点,然后再进行查找操作;插入和删除操作的时间复杂度也为O(logn),因为B+树的节点会根据关键字的大小自动排序,插入或删除操作时需要调整树的结构,以保持平衡性。
红黑树
红黑树也是一种自平衡二叉搜索树,它通过旋转和变色等操作来保持树的平衡性。红黑树的插入、删除和查找操作的时间复杂度均为O(logn),其中查找操作的时间复杂度为O(logn),因为红黑树的节点会根据关键字的大小自动排序,插入或删除操作时需要调整树的结构,以保持平衡性。
需要注意的是,B+树和红黑树的具体实现方式可能会影响它们的性能表现。例如,B+树中每个节点可以存储多个键值和指针,而红黑树中每个节点只存储一个键值。此外,B+树通常适用于范围查询和排序操作,而红黑树适用于单点查询和有序集合。因此,在实际应用中需要根据具体需求选择合适的数据结构。
了解 MySQL 存储引擎吗
为了管理方便,人们把连接管理、查询缓存、语法解析、查询优化这些并不涉及真实数据存储的功能划分为MySQL Server的功能,把真实存取数据的功能划分为存储引擎的功能。所以在MySQL Server完成了查询优化后,只需按照生成的执行计划调用底层存储引擎提供的API,获取到数据后返回给客户端就好了。
MySQL中提到了存储引擎的概念。简而言之,存储引擎就是指表的类型。其实存储引擎以前叫做表处理器,后来改名为存储引擎,它的功能就是接收上层传下来的指令,然后对表中的数据进行提取或写入操作。
一、MySQL支持的引擎
我们可以通过如下命令查看当前数据库服务器支持的存储引擎:
show engines
| Engine | Support | Comment | Transactions | XA | Savepoints |
|---|---|---|---|---|---|
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine |
XA 就是 X/Open DTP 定义的交易中间件与数据库之间的接口规范(即接口函数)。交易中间件用它来通知数据库事务的开始、结束以及提交、回滚等。XA 接口函数由数据库厂商提供,可以理解XA指标表示是否支持分布式事务。
查看当前服务器的存储引擎
show variables like '%storage_engine%'
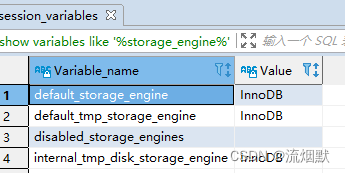
如果在创建表的语句中没有显示指定表的存储引擎的话,那就回默认使用InnoDB作为表的存储引擎。如果我们想改变表的默认存储引擎的话,可以这样写启动服务器的命令行:
set DEFAULT_STORAGE_ENGINE=InnoDB
或者修改my.cnf文件:
default-storage-engine=InnoDB
1)InnoDB引擎
具备外键支持功能的事务存储引擎。MySQL从3.23.34a开始就包含InnoDB存储引擎,5.5之后,默认采用InnoDB引擎。
Innodb引擎 提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。InnoDB是MySQL的默认事务型引擎,它被设计用来处理大量的短期(short-lived)事务。可以确保事务的完整提交(Commit)和回滚(Rollback)。
数据文件结构:
-
表名.frm 存储表结构(MySQL8时合并在 表名.ibd 中)
-
表名.ibd 存储数据和索引
InnoDB是为处理巨大数据量的最大性能设计。在以前的版本中,字典数据以元数据文件、非事务表等来存储。现在这些元数据文件被删除了,比如.frm .par .trn .isl .db .opt 等都在MySQL8中不存在了。
对于MyISAM的存储引擎,InnoDB写的处理效率差一些,并且会占用更多的磁盘空间以保持数据和索引。
MyISAM只缓存索引,不缓存真实数据。InnoDB不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响。
总结: 除了增加和查询外,还需要更新、删除操作那么应该优先选择InnoDB存储引擎。
2)MyISAM引擎
主要的非事务处理存储引擎,其是5.5之前默认的存储引擎。
MyISAM提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM不支持事务、行级锁、外键,有一个毫无疑问的缺陷就是崩溃后无法安全恢复。
优势是访问的速度快,对事务完整性没有要求或者以select、insert为主的应用(只读应用或以读为主的业务)。
针对数据统计有额外的常数存储,故而比如 count(*) 的查询效率很高。
数据文件结构:
-
表名.frm 存储表结构(MySQL8中为 表名.sdi)
-
表名.MYD 存储数据
-
表名.MYI 存储索引
3)Archive引擎
用于数据存档。archive是归档的意思,仅仅支持插入和查询两种功能(行被插入后不能再修改)。在MySQL5.5以后支持索引功能。
拥有很好的压缩机制,使用zlib压缩库,在记录请求的时候实时的进行压缩,经常被用来作为仓库使用。创建ARCHIVE表时,存储引擎会创建名称以表名开头的文件,数据文件的扩展名为.ARZ。
根据英文的测试结论来看,同样数据量下,Archive表比MyISAM表要小大约75%,比支持事务处理的InnoDB表小大于83%。
Archive存储引擎采用了行级锁。该引擎支持AUTO_INCREMENT列属性。AUTO_INCREMENT列可以具有唯一索引或非唯一索引。尝试在任何其他列创建所以会导致错误。
Archive表适合日志和数据采集(档案)类应用,适合存储大量的独立的作为历史记录的数据。拥有很高的插入速度,但是对查询的支持较差。
| 特质 | 支持 |
|---|---|
| B树索引 | NO |
| 备份/时间点恢复(在服务器中实现,而不是在存储引擎中) | Yes |
| 集群数据库支持 | No |
| 聚集索引 | No |
| 压缩数据 | Yes |
| 数据缓存 | No |
| 加密数据(加密功能在服务器中实现) | Yes |
| 外键 | No |
| 全文索引 | No |
| 地理空间数据类型 | Yes |
| 地理空间索引 | No |
| 哈希索引 | No |
| 索引缓存 | No |
| 锁粒度 | 行锁 |
| MVCC | No |
| 存储限制 | 没有任何限制 |
| 事务 | No |
| 更新数据字典的统计信息 | Yes |
4)Blackhole引擎
丢弃写操作,读操作会返回空内容。Blackhole引擎没有实现任何存储机制,它会丢弃所有插入的数据,不做任何保证。但服务器会记录Blackhole表的日志,所以可以用于复制数据到备库,或者简单地记录到日志。但这种应用方式会碰到很多问题,不推荐。
5)CSV引擎
存储数据时,以逗号分隔各个数据项。CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但不支持索引。其可以作为一种数据交换的机制,存储的数据直接可以在操作系统里,用文本编辑器或者Excel读取。对于数据的快速导入、导出是有明显优势的。
创建CSV表时,服务器会创建一个纯文本数据文件,其名称以表名开头并带有.CSV 扩展名。当你将数据存储到表中时,存储引擎将其以逗号分隔值格式保存到数据文件中。
6)Memory引擎
置于内存的表。Memory采用的逻辑介质是内存,响应速度很快,但是当mysqld守护进程崩溃的时候数据会丢失。另外,要求存储的数据是数据长度不变的格式,比如blob/text类型的数据不可用。
Memory同时支持哈希(HASH)索引和B+树索引
-
哈希索引对于等值查询很快,但是对于范围查询慢;
-
默认使用哈希索引
Memory表至少要比MyISAM表要快一个数量级。
memory表的大小是受到限制的。表的大小主要取决于两个参数,分别是 max_rows 和 max_heap_table_size 。其中,max_rows 可以在创建表时指定,max_heap_table_size的 大小默认为16MB,可以按需要进行扩大。
Memory的数据文件和索引文件是分开存储的。
-
每个基于Memory存储引擎的表实际对应一个磁盘文件,该文件的文件名与表名相同,类型为
.frm,该文件中只存储表的结构,而其 数据文件都是存储在内存中的。 -
优点是有利于数据的快速处理,提高整个表的处理效率;
-
缺点是数据易丢失,生命周期短。
Federated引擎,访问远程表。该引擎是访问其他MySQL服务器的一个代理,尽管该引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题,因此默认是禁用的。
Merge引擎,管理多个MyISAM表构成的表集合。
NDB引擎,MySQL集群专用存储引擎。也叫做NDB Cluster存储引擎,主要用于MySQL Cluster 分布式集群环境,类似于Oracle的RAC集群。
二、MyISAM与InnoDB区别
MySQL5.5之前的默认存储引擎是MyISAM,5.5之后修改为了InnoDB。
首先对于InnoDB存储引擎,提供了良好的事务管理、崩溃修复能力和并发控制。因为InnoDB存储引擎支持事务,所以对于要求事务完整性的场合需要选择InnoDB,比如数据操作除了插入和查询以外还包含有很多更新、删除操作像财务系统等。缺点是读写效率较差,占用的数据空间相对比较大。
其次对于MyISAM存储引擎,如果是小型应用,系统以读操作和插入操作为主,只有很少的更新、删除操作,并且对事务的要求没有那么高,则可以选择这个存储引擎。MyISAM存储引擎的优势在于占用空间小,处理速度快。缺点是不支持事务的完整性和并发性。
\ | MyISAM | InnoDB |
|---|---|---|
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引,还缓存真实数据,对内存要求较高。而且内存大小对性能有决定性影响。 |
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 锁 | 表级锁定 | 行级锁定、表级锁定,锁定力度小并发能力高 |
| 索引的实现 | B+树索引,myisam是堆表 | B+树索引,Innodb是索引组织表 |
| 哈希索引 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 记录存储顺序 | 按记录插入顺序保存 | 按主键大小有序插入 |
| 存储空间 | MyISAM可被压缩,存储空间较小 | InnoDB的表需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引 |
| 可移植性、备份及恢复 | 由于MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作 | 免费的方案可以是拷贝数据文件、备份binlog,或者用mysqldump,在数据量达到几十G的时候就相对痛苦了 |
1)在索引上的区别
-
InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
-
InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。
-
MyISAM索引的叶子节点存储的是
行数据地址,需要再寻址一次才能得到数据。 -
InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效。
-
InnoDB的数据文件本身就是主键索引文件,这样的索引被称为“聚簇索引”
InnoDB中primary index(主键索引或者聚簇索引)是和row data存放在一起的,而secondary index(辅助索引)则是单独存放,然后有个指针指向primary key。primary key则主要在扫描索引同时要返回row data时的作用较大。
2)表/行锁差异
MyISAM只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,是在索引上生效的。如果没有命中索引,则锁表。
MyISAM锁的粒度是表级,而InnoDB支持行级锁定。简单来说就是, InnoDB支持数据行锁定,而MyISAM不支持行锁定,只支持锁定整个表。
MyISAM同一个表上的读锁和写锁是互斥的,MyISAM并发读写时如果等待队列中既有读请求又有写请求,默认写请求的优先级高,即使读请求先到,所以MyISAM不适合于有大量查询和修改并存的情况,那样查询进程会长时间阻塞。因为MyISAM是锁表,所以某项读操作比较耗时会使其他写进程饿死。
3)表主键
MyISAM: 允许没有任何索引和主键的表存在,索引都是保存行的地址。
InnoDB: 如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),行数据是主键索引的一部分,二级索引则是单独存放,然后有个指针指向primary key。InnoDB的主键范围更大,最大是MyISAM的2倍。
4)行数统计count
没有where的count()使用MyISAM要比InnoDB快得多。因为MyISAM内置了一个计数器,count()时它直接从计数器中读,而InnoDB必须扫描全表。
所以在InnoDB上执行count()时一般要伴随where,且where中要包含主键以外的索引列。为什么这里特别强调“主键以外”?
因为InnoDB中主键索引是和行数据存放在一起的,而二级索引则是单独存放,然后有个指针指向primary key。所以只是count()的话使用secondary index扫描更快,而primary key则主要在扫描索引同时要返回row data时的作用较大。
三、InnoDB的优势
InnoDB存储引擎在实际应用中拥有诸多优势,比如操作便利、提高了数据库的性能、维护成本低等。如果由于硬件或软件的原因导致服务器崩溃,那么在重启服务器之后不需要进行额外的操作。InnoDB崩溃恢复功能自动将之前提交的内容定型,然后撤销没有提交的进程,重启之后继续从崩溃点开始执行。
InnoDB存储引擎在主内存中维护缓冲池,高频率使用的数据将在内存中直接被处理。这种缓存方式应用于多种信息,加速了处理进程。
在专用服务器上,物理内存中高达80%部分被应用于缓冲池。插入、更新和删除操作通过做改变缓冲自动机制进行优化。InnoDB不仅支持当前读写,也会缓冲改变的数据到数据流磁盘。
如果需要将数据插入不同的表中,可以设置外键加强数据的完整性。更新或者删除数据,关联数据将会被自动更新或删除。如果试图将数据插入从表,但在主表中没有对应的数据,插入的数据将被自动移除。
如果磁盘或内存中的数据出现崩溃,在使用脏数据之前,校验和机制会发出警告。当每个表的主键都设置合理时,与这些列有关的操作会被自动优化。
InnoDB的性能优势不只存在于长时运行查询的大型表。在同一列多次被查询时,自适应哈希索引会提高查询的速度。使用InnoDB可以压缩表和相关索引,可以在不影响性能和可用性的情况下创建或删除索引。
对于大型文本和BLOB数据,使用动态行形式,这种存储布局更高效。即使有些操作系统限制文件大小为2GB,InnoDB仍然可以处理。当处理大数据量时,InnoDB兼顾CPU以达到最大性能。
在同一个语句中,InnoDB表可以与其他存储引擎表混用。
四、InnoDB和ACID模型
ACID模型是一系列数据库设计规则,这些规则着重强调可靠性,而可靠性对于商业数据和任务关键型应用非常重要。MySQL包含类似InnoDB存储引擎的组件,与ACID模型紧密相连,这样出现意外时,数据不会崩溃,结果不会失真。
如果依赖ACID模型,可以不使用一致性检查和崩溃恢复机制。如果拥有额外的软件保护,极可靠的硬件或者应用可以容忍一小部分的数据丢失和不一致,可以将MySQL设置调整为只依赖部分ACID特性,以达到更高的性能。下面给出InnoDB存储引擎和ACID模型相同作用的四个方面。
1)原子方面
ACID的原子方面主要涉及InnoDB事务,与MySQL相关的特性主要包括:
-
自动提交设置
-
Commit语句
-
rollBack语句
-
操作INFORMATION_SCHEMA 库中的表数据
2)一致性方面
ACID模型的一致性主要涉及保护数据不崩溃的内部InnoDB处理过程,与MySQL相关的特性主要包括:
-
InnoDB双写缓存
-
InnoDB崩溃恢复
3)隔离方面
隔离是应用于事务的级别,与MySQL相关的特性主要包括:
-
自动提交设置
-
SET ISOLATION LEVEL语句
-
InnoDB锁的低级别信息
4)耐久性(持久性)方面
ACID模型的耐久性主要涉及与硬件配置相互影响的mysql软件特性。由于硬件复杂度多样化,耐久性方面没有具体的规则可循。与MySQL相关的特性有:
-
InnoDB双写缓存,通过 innodb_doublewrite 配置项配置;
-
配置项 innodb_flush_log_at_trx_commit
-
配置项 sync_binlog
-
配置项 innodb_file_per_table
-
存储设备的写入缓存
-
存储设备的备用电池缓存
-
运行MySQL的操作系统
-
持续的电力供应
-
备份策略
-
对分布式或托管的应用,最主要的在于硬件设备的地点及网络情况
五、InnoDB架构
1)缓冲池
缓冲池是主内存中的一部分空间,用来缓存已使用的表和索引数据。缓冲池使得经常被使用的数据能够直接在内存中获得,从而提高速度。
2)更改缓存
更改缓存是一个特殊的数据结构,当受影响的索引页不在缓存中时,更改缓存会缓存辅助索引页的更改。索引页被其他读取操作时会加载到缓存池,缓存的更改内容就会被合并。不同于集群索引,辅助索引并非独一无二的。
当系统大部分闲置时,清除操作会定期运行,将更新的索引页刷入磁盘。更新缓存合并期间,可能会大大降低查询的性能。在内存中,更新缓存占用一部分InnoDB缓冲池。在磁盘中,更新缓存是系统表空间的一部分。更新缓存的数据类型 由 innodb_change_buffering 配置项管理。
3)自适应哈希索引
自适应哈希索引将负载和足够的内存结合起来,使得InnoDB像内存数据库一样运行,不需要降低事务上的性能或可靠性。这个特性通过 innodb_adaptive_hash_index 选项配置,或者通过 --skip-innodb_adaptive_hash_index 命令行在服务器启动时关闭。
4)重做日志缓存
重做日志缓存存放要放入重做日志的数据。重做日志缓存大小通过 innodb_log_buffer_size 配置项配置。重做日志缓存会定期地将日志文件刷入磁盘。大型的重做日志缓存使得大型事务能够正常运行而不需要写入磁盘。
5)系统表空间
系统表空间包括InnoDB数据字典、双写缓存、更新缓存和撤销日志,同时也包括表和索引数据。多表共享,系统表空间被视为共享表空间。
6)双写缓存
双写缓存位于系统表空间中,用于写入从缓存池刷新的数据页。只有在刷新并写入双写缓存后,InnoDB才会将数据页写入合适的位置。
7)撤销日志(Undo log)
撤销日志是一系列与事务相关的撤销记录的集合,包含如何撤销事务最近的更改。
如果其他事务要查询原始数据,可以从撤销日志记录中追溯未更改的数据。撤销日志存在于撤销日志片段中,这些片段包含于回滚片段中。
8)独立表空间
也就是每个表一个文件的表空间,即每个单独的表空间创建在自身的数据文件中,而不是系统表空间中。这个功能通过 innodb_file_per_table 配置项开启。每个表空间由一个单独的 .ibd 数据文件代表,该文件默认被创建在数据库目录中。
9)通用表空间
使用CREATE TABLESPACE 语法创建共享的InnoDB表空间。通用表空间可以创建在MySQL数据目录之外能够管理多个表并支持所有行格式的表。
10)撤销表空间
撤销表空间由一个或多个包含撤销日志的文件组成,撤销表空间的数量是由 innodb_undo_tablespace 配置项配置。
11)临时表空间
用户创建的临时表空间和基于磁盘的内部临时表都创建于临时表空间。innodb_temp_data_file_path 配置项定义了相关的路径、名称、大小和属性。如果该值为空,默认会在 innodb_data_home_dir变量指定的目录下创建一个自动扩展的数据文件。
12)重做日志(Redo log)
重做日志是基于磁盘的数据结构,在崩溃恢复期间使用,用来修复数据。正常操作期间,重做日志会将请求数据进行编码,这些请求会改变 InnoDB表数据。遇到意外崩溃后,未完成的更改会自动在初始化期间重新进行。
说说 MySQL 集群原理
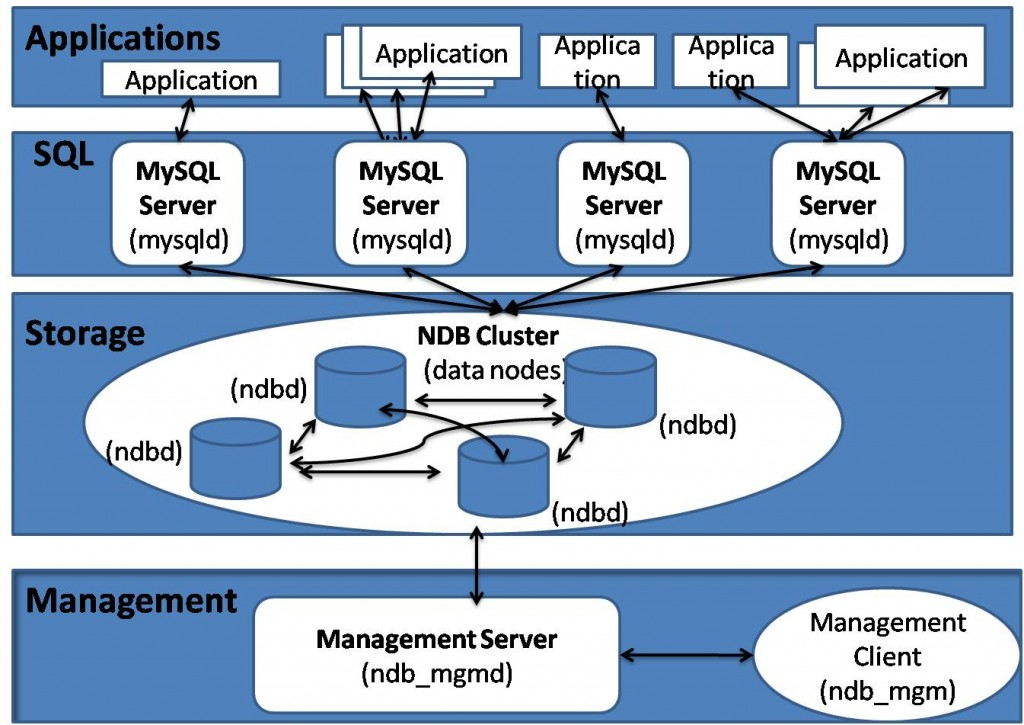
一、什么是MySQL集群
MySQL集群是一个无共享的(shared-nothing)、分布式节点架构的存储方案,其目的是提供容错性和高性能。
数据更新使用读已提交隔离级别(read-committedisolation)来保证所有节点数据的一致性,使用两阶段提交机制(two-phasedcommit)保证所有节点都有相同的数据(如果任何一个写操作失败,则更新失败)。
无共享的对等节点使得某台服务器上的更新操作在其他服务器上立即可见。传播更新使用一种复杂的通信机制,这一机制专用来提供跨网络的高吞吐量。
通过多个MySQL服务器分配负载,从而最大程序地达到高性能,通过在不同位置存储数据保证高可用性和冗余。
二、架构图
三、如何存储数据
1.Mysqlcluster数据节点组内主从同步采用的是同步复制,来保证组内节点数据的一致性。一般通过两阶段提交 协议来实现,一般工作过程如下:
1)Master执行提交语句时,事务被发送到slave,slave开始准备事务的提交。
2)每个slave都要准备事务,然后向master发送OK(或ABORT)消息,表明事务已经准备好(或者无法准备该事务)。
3)Master等待所有Slave发送OK或ABORT消息
如果Master收到所有 Slave的OK消息,它就会向所有Slave发送提交消息,告诉Slave提交该事务;
如果Master收到来自任何一个Slave的ABORT消息,它就向所有 Slave发送ABORT消息,告诉Slave去中止事务。
4)每个Slave等待来自Master的OK或ABORT消息。
如果Slave收到提交请求,它们就会提交事务,并向Master发送事务已提交 的确认;
如果Slave收到取消请求,它们就会撤销所有改变并释放所占有的资源,从而中止事务,然后向Masterv送事务已中止的确认。
5) 当Master收到来自所有Slave的确认后,就会报告该事务被提交(或中止),然后继续进行下一个事务处理。
由于同步复制一共需要4次消息传递,故mysql cluster的数据更新速度比单机mysql要慢。所以mysql cluster要求运行在千兆以上的局域网内,节点可以采用双网卡,节点组之间采用直连方式。
疑问:对cluster进行扩容增加数据节点组时会不 会导致数据更新速度降低?
答:不会,数据更新速度会变快。因为数据是分别处理,每个节点组所保存的数据是不一样的, 也能减少锁定。
2.Mysqlcluster将所有的索引列都保存在主存中,其他非索引列可以存储在内存中或者通过建立表空间存储到磁盘上。如果数据发生改变(insert,update,delete等),mysql 集群将发生改变的记录写入重做日志,然后通过检查点定期将数据定入磁盘。由于重做日志是异步提交的,所以故障期间可能有少量事务丢失。为了减少事务丢失,mysql集群实现延迟写入(默认延迟两秒,可配置),这样就可以在故障发生时完成检查点写入,而不会丢失最后一个检查点。一般单个数据节点故障不会导致任何数据丢失,因为集群内部采用同步数据复制。
四、MySQL集群的横向扩展
1.添加数据节点组来扩展写操作,提高 cluster的存储能力。支持在线扩容,先将新的节点加入到clsuter里,启动后用 ALTER ONLINE TABLE table_name REORGANIZE PARTITION
命令进行数据迁移,把数据平均分配到数据节点上。
2.添加Slave仅仅扩展读,而不能做到写操作的横向扩展。
整个系统的平均负载可以描述为:
AverageLoad=∑readload+ ∑writeload / ∑capacity
假设每个服务器每秒有10000的事务量,而Master每秒的写负载为4000个事务,每秒的读负载为6000,结果就是:
AverageLoad=6000+4000/10000=100%
现在,添加3个slave,每秒的事务量增加到40000。因为写操作也会被复制,每个写操作执行4次,
这样每个slave的写负载就是每秒4000个事务。那么现在的平均负载为:
AverageLoad=6000+4*4000/ 4*10000=55%
五、MySQL集群的优缺点
优点:
1)99.999%的高可用性
2)快速的自动失效切换
3)灵活的分布式体系结构,没有单点故障
4)高吞吐量和低延迟
5)可扩展性强,支持在线扩容
缺点:
1)存在很多限制,比如:不支持外键
2)部署、管理、配置很复杂
3)占用磁盘空间大,内存大
4)备份和恢复不方便
5)重启的时候,数据节点将数据load到内存需要很长时间
说一下进程和线程
进程和线程都是操作系统中的基本执行单元,但是它们之间有一些重要的区别。
进程(Process)是操作系统中正在运行的程序实例,每个进程都有自己的独立内存空间、系统资源和打开的文件等。进程之间相互隔离,一个进程的崩溃不会影响其他进程的运行。进程之间可以通过系统调用进行通信和协作。
线程(Thread)是进程中的一个执行单元,它与同一进程中的其他线程共享进程的内存空间和系统资源。多个线程可以同时执行,它们之间相互协作,共享数据和资源。由于线程共享进程的内存空间,因此线程之间的通信和同步比进程之间更加容易。
区别:
-
内存空间:进程拥有独立的内存空间,而线程共享同一个进程的内存空间。
-
资源占用:进程需要独立的系统资源来运行,如文件句柄、网络连接等,而线程可以共享这些资源。
-
通信方式:进程之间通信需要通过系统调用进行,而线程之间可以通过共享变量或者消息传递等方式进行通信。
-
创建和销毁开销:创建和销毁进程的开销比创建和销毁线程要大得多。
应用:
进程适用于需要独立运行、相互隔离的应用程序,如编译器、数据库管理系统等。在多核处理器上,使用多个进程可以充分利用多核处理器的性能。
线程适用于需要频繁切换、共享资源的应用程序,如图形界面应用程序、网络应用程序等。在单核处理器上,使用多个线程可以提高应用程序的并发性和响应速度。
说说进程通信方式
进程通信是操作系统提供的一种机制,使得多个进程之间可以交换信息和数据。以下是几种常见的进程通信方式:
-
共享内存:共享内存是最常见的进程通信方式之一。它允许两个或多个进程共享同一块内存,这样它们就可以访问同一个数据。共享内存通常用于进程间通信,例如在同一个进程中的两个线程之间共享数据。
-
消息传递:消息传递是另一种进程通信方式,它允许进程之间交换消息。消息可以是任何类型的数据,包括数字、字符串、结构体等。消息传递通常用于进程间通信,例如在操作系统中的进程调度和同步中使用。
-
共享文件:共享文件是一种特殊类型的共享内存,它允许两个或多个进程共享同一个文件。共享文件通常用于文件传输和同步等操作。
-
管道:管道是一种特殊类型的共享内存,它允许一个进程将数据写入管道,而另一个进程可以从管道中读取数据。管道通常用于进程间通信,例如在命令行界面中使用管道来将命令和输出传递给其他进程。
-
信号量:信号量是一种特殊类型的变量,它允许一个进程在另一个进程中等待或响应。信号量通常用于进程间通信,例如在操作系统中使用信号量来实现进程同步和调度。
这些是常见的进程通信方式,每种方式都有其优点和缺点,适用于不同的应用场景。
关于计算机网络:说一下 HTTP HTTPS
HTTP(超文本传输协议)和HTTPS(安全超文本传输协议)都是使用TCP/IP协议进行通信的网络协议。HTTP是一种超文本标准协议,HTTPS是安全的超文本标准协议。
特点:
-
HTTP是一种明文协议,所有的数据包都会明文传输而可能会被黑客窃取。
-
HTTPS是一种加密协议,使用公钥密码学技术来保证数据传输安全,即使数据被截获,也无法解密。
-
HTTPS还具有身份验证、数据加密、重定向等安全机制,确保用户的隐私和数据安全。
-
因此,HTTPS被广泛用于需要传输敏感数据的网站。
应用:
-
HTTP用于公共场所、非敏感信息的传输,允许数据直接传送,速度快,适用于小数据的传递。
-
HTTPS用于需要传输敏感数据的网站,比如在线购物、银行支付等,它可以确保用户的隐私和数据安全。
说说HTTP 完整的请求过程
完整的HTTP请求过程包括以下几个步骤:
-
客户端向服务器发送HTTP请求报文。
-
服务器接收到请求报文后,对报文进行解析,根据报文中的方法(GET,POST等)和请求的资源(文件,数据等)来确定如何处理该请求。
-
服务器向客户端发送响应报文,报文中包含服务器返回的数据和状态信息。
-
客户端接收到响应报文后,解析响应报文中的数据和状态信息,根据响应确定是否成功获取了所需的资源或者是否出现了错误。
需要注意的是,HTTP请求和响应是通过TCP协议进行传输的,因此,在传输过程中需要进行三次握手建立连接,同时需要进行数据的分片和确认,以确保数据的可靠传输。
HTTP(Hypertext Transfer Protocol)是一种用于在Web浏览器和Web服务器之间传输数据的协议。HTTP请求过程可以分为以下几个步骤:
-
建立TCP连接:客户端向服务器发送一个请求,服务器收到请求后会建立与客户端的TCP连接。
-
发送请求头:客户端在建立TCP连接后会发送一个请求头(Request Header),其中包含了请求方法、请求URL、协议版本等信息。
-
发送请求体:如果请求需要携带数据,则客户端会在请求头后面发送一个请求体(Request Body)。
-
服务器响应头:服务器收到请求后会返回一个响应头(Response Header),其中包含了响应状态码、协议版本等信息。
-
发送响应体:服务器在返回响应头后会发送一个响应体(Response Body),其中包含了服务器返回的数据。
-
关闭连接:当客户端接收到服务器的响应后,会关闭TCP连接。
下面是一个简单的HTTP请求过程的示例:
假设有一个Web服务器在IP地址为192.168.1.100上运行,端口号为80,并且当前请求的URL为http://www.example.com/index.html。
客户端使用浏览器向服务器发送一个HTTP GET请求,请求头部包含以下信息:
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.8
Connection: keep-alive
Cookie: userid=12345; sessionid=67890
服务器收到请求后会根据请求头部中的信息进行相应的处理,然后返回一个HTTP响应给客户端。在这个例子中,服务器可能会返回以下内容:
HTTP/1.1 200 OK
Date: Wed, 22 Oct 2021 10:30:00 GMT
Server: Apache/2.4.41 (Unix) OpenSSL/1.1.1f CDH11 x86_64 GNU/Linux
Last-Modified: Tue, 21 Oct 2021 14:25:37 GMT
ETag: "e6d7cbe-f7b8-4a9f-b7c8-e7a9fef5f5e5"
Accept-Ranges: bytes
Content-Length: 32768
Connection: keep-alive
Content-Type: text/html; charset=UTF-8
Cache-Control: no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: -1
Set-Cookie: userid=12345; sessionid=67890; path=/; domain=www.example.com; expires=Wed, 23 Oct 2021 10:30:00 GMT; secure; HttpOnly
X-Frame-Options: SAMEORIGIN
X-XSS-Protection: 1; mode=block
X-Powered-By: PHP/7.4.15 (Apache) with Suhosin-Patch for PHP 7.4.x and PHP API v2 on Apache+PHP7.4.15组合
<!DOCTYPE html> <html> <head> <title>Hello World</title> </head> <body> <h1>Hello World!</h1> </body> </html>
说说 http 报文请求行、请求头、请求正文
HTTP(Hypertext Transfer Protocol)是一种用于在Web浏览器和Web服务器之间传输数据的协议。HTTP请求由三部分组成:请求行、请求头和请求正文。
一、请求行
包含以下信息:
-
HTTP方法(Get、Post等)
-
目标URL
-
HTTP版本号
例如,一个GET请求的请求行可能如下所示:
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.8
Connection: keep-alive
Cookie: userid=12345; sessionid=67890
二、请求头
请求头包含了一些元数据,用于描述客户端发送的请求。它包含以下字段:
-
Host:目标服务器的主机名或IP地址。
-
User-Agent:客户端的标识信息,通常包括浏览器类型和版本号。
-
Accept:客户端可接受的内容类型列表。
-
Accept-Encoding:客户端可以压缩的内容类型列表。
-
Accept-Language:客户端可接受的语言类型列表。
-
Connection:客户端与服务器之间的连接类型。常见的连接类型有keep-alive和close。
-
Cookie:客户端发送给服务器的Cookie信息。
-
Referer:客户端访问当前页面的前一个页面的URL。
-
If-Modified-Since:如果缓存未过期,则表示客户端希望从缓存中获取资源。
-
If-None-Match:如果缓存未过期且资源没有被修改,则表示客户端希望使用缓存中的资源。
-
Content-Type:客户端发送的数据的类型。常见的数据类型有application/json、application/x-www-form-urlencoded等。
-
Content-Length:客户端发送的数据的长度。
例如,一个POST请求的请求头可能如下所示:
Content-Type: application/json
Content-Length: 25
{"name": "John", "age": 30}
其中,Content-Type指定了发送的数据类型为JSON格式,Content-Length指定了发送的数据长度为25个字节。
三、请求正文
请求正文是客户端发送的实际数据内容。对于GET请求来说,请求正文通常是一个URL参数;对于POST请求来说,请求正文是客户端发送的数据内容。
请求正文是HTTP报文的主体部分,用于描述请求的内容和请求的目标资源。请求正文通常包括以下内容:
-
URI:包含请求资源的地址
-
Method:请求方法,例如GET、POST、PUT等
-
Header:请求头中包含的其他信息
-
Body:请求正文中包含的实际数据或请求参数
在HTTP报文中,请求行和请求正文是分开的,通过回车符或换行符分隔。HTTP报文的格式如下:
Copy codeHTTP/1.1 200 OK
Date: Wed, 25 Feb 2023 10:00:00 GMT
Content-Type: application/json
Content-Length: 123
Connection: keep-alive
其中,HTTP版本和状态码表示请求是否成功,Date表示请求发送的时间,Content-Type和Content-Length表示请求正文的类型和长度,Connection表示连接方式。在请求正文中,JSON格式的数据表示请求参数。
说说 post 和 put 区别
HTTP 的 POST 和 PUT 方法都用于向服务器发送数据,但是它们的作用和使用方式有所不同。POST 方法用于向服务器发送数据,并且数据会被附加到服务器端的请求正文中。当服务器端收到 POST 请求时,它会将请求正文中的数据作为响应的主体部分返回给客户端。PUT 方法用于向服务器发送数据,并且数据会替换服务器端的现有资源。当服务器端收到 PUT 请求时,它会将请求中的数据作为请求正文的一部分附加到服务器端的资源上。然后,服务器端会将资源的内容重新写入客户端请求的地址。下面是一个简单的示例来说明 POST 和 PUT 方法的区别:
Copy code// POST方法
public void postData(String url, String data) {
try {
URL obj = new URL(url);
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
con.setRequestMethod("POST");
con.setRequestProperty("Content-Type", "application/json");
con.setDoOutput(true);
OutputStream os = con.getOutputStream();
os.write(data.getBytes());
os.flush();
os.close();
con.getResponseCode(); // 执行 POST 请求
} catch (Exception e) {
e.printStackTrace();
}
}
// PUT方法
public void putData(String url, String data) {
try {
URL obj = new URL(url);
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
con.setRequestMethod("PUT");
con.setRequestProperty("Content-Type", "application/json");
con.setDoOutput(true);
OutputStream os = con.getOutputStream();
os.write(data.getBytes());
os.flush();
os.close();
con.getResponseCode(); // 执行 PUT 请求
} catch (Exception e) {
e.printStackTrace();
}
}
在以上示例中,postData 方法使用 POST 方法向服务器发送数据,并且将数据附加到请求正文中。putData 方法使用 PUT 方法向服务器发送数据,并且将数据替换服务器端的现有资源。
说一下 DNS 服务器解析原理
DNS(Domain Name System)服务器是一种用于将域名解析为IP地址的计算机系统。当用户在浏览器中输入一个网址时,浏览器会向本地DNS服务器发送一个查询请求,询问该网址对应的IP地址是什么。如果本地DNS服务器没有缓存该网址对应的IP地址,它会向根DNS服务器发送一个查询请求,根DNS服务器会继续向下查询,直到找到对应的权威DNS服务器或者直接返回查询结果。
下面是DNS服务器解析原理的具体步骤:
-
用户在浏览器中输入一个网址,如www.example.com。
-
浏览器向本地DNS服务器发送一个查询请求,请求包含以下信息:目标域名(www.example.com)、查询类型(A记录或MX记录等)、查询方式(默认为正向查询)。
-
如果本地DNS服务器没有缓存目标域名对应的IP地址,它会向根DNS服务器发送一个查询请求,请求包含目标域名、查询类型和查询方式等信息。
-
根DNS服务器收到查询请求后,会查找其缓存中是否已经存在目标域名对应的IP地址。如果存在,则直接返回该IP地址给本地DNS服务器;如果不存在,则继续向下查询。
-
根DNS服务器会继续向下查询,直到找到对应的权威DNS服务器或者直接返回查询结果。在向下查询的过程中,可能会遇到多个权威DNS服务器,每个权威DNS服务器都会根据自己的缓存信息来判断是否需要继续向下查询。
-
当权威DNS服务器收到查询请求后,会查找其缓存中是否已经存在目标域名对应的IP地址。如果存在,则直接返回该IP地址给本地DNS服务器;如果不存在,则继续向上查询。
-
当权威DNS服务器找到目标域名对应的IP地址后,它会将该IP地址返回给本地DNS服务器。本地DNS服务器收到IP地址后,会将其缓存起来,并将该IP地址返回给浏览器。
-
最后,浏览器收到本地DNS服务器返回的IP地址后,就会使用该IP地址来建立与目标网站的连接。
知道 ARP 欺骗吗?
ARP(Address Resolution Protocol)协议是用于将一个IP地址映射到一个MAC地址的协议。ARP欺骗是一种网络攻击技术,攻击者通过发送伪造的ARP响应包来欺骗网络中的其他设备,使其认为攻击者的MAC地址和IP地址是合法的。
具体来说,ARP欺骗可以分为以下两种类型:
-
静态ARP欺骗:攻击者在网络中预先设置一个虚假的ARP响应包,使得网络中的其他设备误认为该响应包是真实的。这样,当其他设备需要与攻击者通信时,它们会将自己的MAC地址和IP地址信息发送给攻击者,从而被攻击者利用进行进一步的攻击。
-
动态ARP欺骗:攻击者在网络中不断地发送伪造的ARP响应包,使得网络中的其他设备不断地更新自己的ARP缓存表。这样,当其他设备需要与攻击者通信时,它们会再次发送ARP请求,而攻击者则会发送伪造的ARP响应包,从而实现欺骗。
ARP欺骗可以被用于多种攻击方式,例如中间人攻击、网络隔离等。为了防止ARP欺骗攻击,网络管理员可以采取一些措施,例如定期更新ARP缓存表、限制ARP广播等。同时,用户也应该注意保护自己的网络安全,避免点击来自陌生人或可疑网站的链接,以及使用安全的网络连接方式。
HTTP 一次请求响应时间过长,怎么分析和解决?
HTTP 一次请求响应时间过长可能是由多种原因引起的,下面是一些可能的分析和解决方法:
-
网络延迟:可以通过 ping 命令或 traceroute 命令来检查网络延迟。如果网络延迟较高,可以考虑更换网络服务提供商或使用 CDN 等技术来加速网络。
-
服务器负载过高:可以通过监控服务器的 CPU、内存、磁盘等指标来判断服务器是否负载过高。如果负载过高,可以考虑优化代码、增加服务器数量或使用负载均衡等技术来分散负载。
-
数据库查询慢:可以通过检查数据库的慢查询日志来分析查询慢的原因。如果查询慢,可以考虑优化数据库索引、优化查询语句或增加缓存等技术来提高查询效率。
-
静态资源加载慢:可以通过使用浏览器的开发者工具来分析静态资源的加载时间。如果加载慢,可以考虑使用 CDN 或优化静态资源的压缩、合并等技术来提高加载速度。
-
程序逻辑复杂:如果程序逻辑过于复杂,可能会导致响应时间过长。可以通过简化程序逻辑、减少数据库查询等方式来优化程序。
总之,要想解决 HTTP 一次请求响应时间过长的问题,需要全面分析问题,找出问题的根本原因,并采取相应的解决方法。
编译原理还记得吗?
编译原理是计算机科学中的一个重要分支,主要研究将高级语言翻译成机器语言的过程。编译器是实现这一过程的工具,它将高级语言的源代码转换成目标代码,使计算机能够理解和执行。
编译器的主要工作包括词法分析、语法分析、语义分析、代码优化和代码生成等。词法分析器将源代码转换成一个个的词法单元,语法分析器将这些词法单元组合成语法树,语义分析器则对语法树进行分析,检查代码是否符合语义规则。代码优化器对代码进行优化,以提高程序的效率和性能。最后,代码生成器将优化后的代码转换成目标代码,使计算机能够执行。
编译原理的研究对于理解计算机的工作原理、提高程序效率和开发高质量的编译器和解释器都具有重要意义。
编译原理包括以下几个主要步骤:
-
词法分析(Lexical Analysis):将源代码分解成一个个有意义的符号,例如关键字、标识符、运算符等。
-
语法分析(Parsing):将符号序列转化为语法树,即一棵表示源代码结构的树形结构。
-
语义分析(Semantic Analysis):对语法树进行静态检查,确定程序是否符合语法规则和语义要求。
-
中间代码生成(Intermediate Code Generation):将语法树转换为中间代码,中间代码是一种低级形式的程序语言,接近于汇编语言。
-
代码优化(Optimization):对中间代码进行优化,以提高生成的目标代码的性能。
-
目标代码生成(Target Code Generation):将中间代码转换为目标代码,即计算机可以执行的机器语言。
在实际编译过程中,通常会使用多种技术来实现这些步骤,例如正则表达式、递归下降解析器、语法分析器、语义分析器、中间代码生成器、优化器等。同时,不同的编程语言也有其独特的编译原理和实现方式。
说说语义语法分析
语义语法分析(Semantic Syntax Analysis,简称SSA)是一种将代码分解为抽象语法树(Abstract Syntax Tree,AST)的方法。它通过将代码分解为更小的、更基本的单元,使得代码更容易理解和优化。
语义语法分析器通过以下步骤分析代码:
-
词法分析:将源代码转换为一个个称为“标记”(token)的小部分,每个标记代表源代码中的一个元素。
-
语法分析:将标记转换为抽象语法树。抽象语法树表示源代码的结构,每个节点代表一个语法单元,例如一个函数、表达式或声明。
-
语义分析:对抽象语法树进行语义分析,将其转换为一个个抽象语义表达式(Abstract Syntax Tree,AST)。AST包含一个节点和一个“值”,节点表示节点的类型,而“值”则包含节点的值。
-
优化:通过AST分析,可以对代码进行优化,例如去除冗余的节点或重构代码结构。
语义语法分析器在编译器和解释器中都很有用。在编译器中,语义语法分析器将源代码转换为AST,然后编译器可以根据AST来生成优化的代码。在解释器中,语义语法分析器可以将AST转换为代码,并将代码解释为机器语言。
说说 JVM 内存模型
Java虚拟机(Java Virtual Machine,简称JVM)有三种内存模型:
-
栈内存模型:此模型中,变量的值存储在栈中,函数调用时,参数和返回值会被压入或弹出栈。如果有多个线程同时访问同一个变量,这些线程都会访问到同一个栈中的变量值。
-
堆内存模型:此模型中,变量的值存储在堆中。当一个线程调用一个函数时,会在堆中分配一块内存空间,该空间被用来存储函数中的变量值。函数调用结束后,这块内存空间可以被释放或重新分配给其他对象。
-
垃圾回收内存模型:此模型中,JVM使用垃圾回收器来管理内存。当程序使用了一个对象之后,如果不再需要它,就会被回收。JVM会跟踪哪些对象正在被使用,哪些对象可以被回收。当对象不再被使用时,JVM会将其回收,以便为其他对象腾出空间。
JVM的内存模型是由垃圾回收机制实现的。JVM使用垃圾回收机制来解决内存分配和垃圾回收的问题,从而支持多线程程序的并发执行。JVM的垃圾回收机制可以分为标记清除、复制算法和标记整理等不同的算法,不同的算法适用于不同的场景。
说说 JVM 垃圾回收算法
JVM(Java 虚拟机)垃圾回收算法主要分为以下几种:
-
标记-清除算法(Mark-Sweep GC):标记出所有需要回收的对象,然后清除所有被标记的对象所占用的内存。标记-清除算法是最基本的垃圾回收算法,但是它会产生大量的内存碎片,碎片化的内存会导致以后的内存分配效率降低。
-
复制算法(Copy-on-Write GC):将内存划分为两部分,每次只使用其中一部分。当一个对象需要进行垃圾回收时,将对象复制到另一部分内存中,然后清除原来的内存。这样可以减少内存碎片的产生,但是复制算法需要额外的开销来复制对象。
-
标记-整理算法(Mark-Compact GC):标记出所有需要回收的对象,然后将所有存活对象移动到一端,清除另一端的内存。标记-整理算法既能减少内存碎片,又能减少复制对象的开销,但是它需要一个较长的时间来进行垃圾回收。
-
G1 算法(G1 Garbage Collector):G1 算法是一种采用增量式垃圾回收的算法,与其他垃圾回收算法不同的是,G1 算法可以预测对象的生命周期,并且可以在对象被使用时进行垃圾回收,而不是等到对象不再被使用时再进行回收。G1 算法具有较好的性能和效率,是目前比较流行的垃圾回收算法之一。
-
其他垃圾回收算法:还有其他一些垃圾回收算法,如 EHCache、Tombstone 算法等,但是它们的应用范围比较有限。
关于 redis,说一下 sorted set 底层原理
Redis 的 sorted set 是一种有序集合,它的底层实现是使用了跳跃表(Skip List)和哈希表(Hash Table)这两种数据结构。跳跃表是一种类似于链表的数据结构,但是它在每个节点上增加了多个指针,可以快速地跳过一些节点,从而提高了查找效率。而哈希表则是一种以键值对形式存储数据的数据结构,可以快速地进行数据的插入、查找和删除操作。
在 Redis 的 sorted set 中,每个元素都有一个分数(score),根据分数的大小来进行排序。使用跳跃表可以快速地进行分数的比较和排序,而使用哈希表可以快速地进行元素的查找和删除操作。同时,Redis 还使用了压缩列表(Ziplist)来优化存储空间,对于一些小的 sorted set,它们的元素可以被存储在一个压缩列表中,从而减少了内存的使用。
sorted set 底层的原理如下:
-
哈希表:每个 sorted set 对象都由一个哈希表和一个分数(score)组成。哈希表用于存储成员的分值和成员的散列值(member),分数用于对成员进行排序。
-
分数计算:sorted set 中的每个成员都有一个分数,该分数是根据其散列值和一个权重因子计算出来的。权重因子是一个介于 0 到 100 之间的整数,用于调整不同成员的分值大小。
-
成员添加和删除:当向 sorted set 中添加或删除成员时,Redis 首先会根据其散列值计算出新的分数,然后将新分数与旧分数进行比较,如果新分数大于旧分数,则更新哈希表中的对应项。
-
范围查询:sorted set 支持范围查询,即可以根据分数范围查找成员。当执行范围查询时,Redis 首先会计算出最小分值和最大分值之间的所有成员的分数范围,然后遍历哈希表,找到所有分数在该范围内的成员。
-
迭代器:sorted set 支持迭代器,可以通过迭代器遍历 sorted set 中的所有成员。迭代器返回每个成员的散列值和分值,但不返回成员本身。
总之,sorted set 底层的原理是基于哈希表和分数计算实现的,它支持添加、删除、范围查询和迭代等操作。由于 sorted set 可以快速地进行范围查询和排序操作,因此在实际应用中被广泛使用。
说说 redis 持久化
Redis 持久化是指将 Redis 中的数据保存到磁盘上,以便在服务器重启或宕机时能够恢复数据。Redis 支持两种持久化方式:RDB(Redis Database)快照和 AOF(Append-Only File)日志。
-
RDB 持久化:RDB 持久化是将 Redis 内存中的数据集快照写入磁盘中,可以设置不同的快照间隔时间和压缩选项。RDB 持久化的优点是可以将快照保存到磁盘中,占用较少的磁盘空间,并且可以快速恢复数据。缺点是如果在备份过程中发生宕机,可能会丢失一部分数据。
-
AOF 持久化:AOF 持久化是将 Redis 执行的所有写操作记录到一个日志文件中,可以在服务器重启时重新执行日志文件中的操作来恢复数据。AOF 持久化的优点是可以保证数据的完整性和可靠性,因为每个写操作都会被记录下来。缺点是相对于 RDB 持久化,AOF 持久化需要更多的磁盘空间,并且在恢复数据时可能会比 RDB 持久化慢一些。
除了以上两种持久化方式外,Redis 还支持主从复制功能,可以将多个 Redis 实例复制到不同的节点上,以实现数据的备份和负载均衡。
总之,Redis 持久化是将 Redis 中的数据保存到磁盘上,以便在服务器重启或宕机时能够恢复数据。Redis 支持 RDB 和 AOF 两种持久化方式,可以根据实际需求选择合适的方式进行配置。
TB 级别的日志文件中存储词汇,找出出现频率最高的十个
对于TB级别的日志文件,如果想要找出出现频率最高的十个词汇,可以考虑使用MapReduce框架来实现。
具体实现可以分为以下几个步骤:
-
将日志文件分割成小文件,每个小文件大小不超过HDFS的块大小。
-
使用MapReduce框架,将每个小文件中的词汇进行统计,并将统计结果输出为键值对(key-value)形式,其中键为词汇,值为该词汇出现的次数。
-
将所有小文件的统计结果进行合并,即将相同键的值进行累加,得到所有词汇的出现次数。
-
对所有词汇的出现次数进行排序,取出出现频率最高的前十个词汇即可。
以下是使用Java实现的示例代码:
import java.io.IOException;
import java.util.StringTokenizer;
import java.util.TreeMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TopTenWords {
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private TreeMap<Integer, String> topTenWords = new TreeMap<Integer, String>();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
topTenWords.put(sum, key.toString());
if (topTenWords.size() > 10) {
topTenWords.remove(topTenWords.firstKey());
}
}
protected void cleanup(Context context) throws IOException, InterruptedException {
for (Integer count : topTenWords.descendingKeySet()) {
context.write(new Text(topTenWords.get(count)), new IntWritable(count));
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "top ten words");
job.setJarByClass(TopTenWords.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
在这个示例代码中,我们定义了一个WordCountMapper类和一个WordCountReducer类,用于实现Map和Reduce操作。其中,WordCountMapper类将输入的文本文件按照空格进行分割,对每个词汇进行计数,并输出为键值对形式。WordCountReducer类将相同键的值进行累加,并将结果存储在一个TreeMap中,最后输出出现频率最高的前十个词汇。
在main函数中,我们定义了一个Job对象,设置输入和输出路径,并启动MapReduce任务。
注意,在实际应用中,还需要根据具体情况进行一些优化,例如设置Combiner、使用压缩等。
说说多模匹配算法
多模匹配算法(Multi-Mode Matching Algorithm)是一种用于在多个模式中查找匹配项的算法。它的基本思想是将每个模式看作一个独立的搜索空间,然后在这些搜索空间中进行匹配。
多模匹配算法通常包括以下几个步骤:
-
初始化:将所有模式中的字符按照其出现的位置进行标记,并将其对应的位置存储在一个二维数组中。
-
第一阶段匹配:在第一个模式中,从左到右依次扫描每个字符,并在第二个模式中查找与之匹配的字符。如果找到了匹配项,则将其位置记录下来。
-
第二阶段匹配:在第一个模式中,从上到下依次扫描每个字符,并在第二个模式中查找与之匹配的字符。如果找到了匹配项,则将其位置记录下来。
-
第三阶段匹配:在第一个模式中,从右到左依次扫描每个字符,并在第二个模式中查找与之匹配的字符。如果找到了匹配项,则将其位置记录下来。
-
第四阶段匹配:在第一个模式中,从下到上依次扫描每个字符,并在第二个模式中查找与之匹配的字符。如果找到了匹配项,则将其位置记录下来。
-
最终匹配:根据记录下来的匹配项位置,在两个模式中找到所有的匹配项,并将它们输出。
多模匹配算法的优点是可以处理多个模式之间的匹配问题,并且可以在不同模式之间进行灵活的选择和组合。缺点是它的时间复杂度较高,因为需要对每个模式进行多次扫描和匹配。此外,由于它需要记录每个模式中字符的位置信息,因此需要较大的内存空间来存储这些信息。
了解 web 容器吗?JBOSS、tomcat
Web容器是一种用于部署和运行Web应用程序的软件。它负责将应用程序的代码和资源打包成一个可执行的、可扩展的和安全的单元。JBOSS是一个流行的Web容器,基于Java EE,它可以运行在不同的操作系统上,如Linux、Windows和Solaris。它提供了许多功能,包括:
-
部署和管理应用程序
-
负载均衡
-
认证和授权
-
缓存和反向代理
-
安全性
-
日志和监控
JBOSS通常用于部署Java EE应用程序,如Web应用程序和EJB应用程序。Tomcat是另一个流行的Web容器,也基于Java EE。它可以运行在不同的操作系统上,如Linux、Windows和Solaris。它提供了许多功能,包括:
-
部署和管理应用程序
-
负载均衡
-
认证和授权
-
缓存和反向代理
-
安全性
-
日志和监控
Tomcat通常用于部署Java EE应用程序,如Web应用程序和EJB应用程序。它是一个开源软件,可以免费使用和自由修改。
说一下 Spring3 优点、缺点
Spring是一个开源的Java企业应用开发框架,它提供了丰富的功能和组件,可以帮助开发人员快速构建高质量的企业级应用程序。Spring3是Spring框架的最新版本之一,它继承了Spring2的优点,并增加了一些新的特性和改进。
Spring3的优点包括
-
更加灵活的配置方式:Spring3引入了基于注解的配置方式,使得配置文件更加简洁、易于维护。同时,Spring3还支持基于XML的配置方式,可以满足不同开发需求。
-
更加模块化的设计:Spring3将框架划分为多个模块,每个模块都有自己的职责和功能。这种模块化的设计使得Spring3更加灵活和可扩展,可以根据不同的需求选择相应的模块进行集成。
-
更加完善的AOP支持:Spring3对AOP的支持更加完善,提供了更加灵活的AOP实现方式,并且支持自定义切面和通知。
-
更加强大的数据访问能力:Spring3提供了更加强大和灵活的数据访问技术,包括JDBC、ORM框架、NoSQL等,可以帮助开发人员更加高效地访问数据。
-
更加安全的认证机制:Spring3引入了基于角色的访问控制(Role-Based Access Control)和基于表单的认证(Form-Based Authentication)等新的认证机制,可以帮助开发人员更好地保护应用程序的安全。
Spring3的缺点包括
-
学习曲线较陡峭:由于Spring3引入了许多新的特性和概念,因此需要较长时间的学习成本来掌握其使用方法和原理。
-
需要更多的内存和CPU资源:由于Spring3的功能和复杂性,它需要更多的内存和CPU资源来运行,这可能会导致应用程序的性能问题。
说说 Struts2 和 SpringMVC 原理和区别
Struts2和Spring MVC都是常见的Java Web框架,它们都提供了丰富的功能和组件,可以帮助开发人员快速构建高质量的Web应用程序。
Struts2的原理
Struts2是一个基于MVC(Model-View-Controller)设计模式的Web框架,它将请求分为三个部分:模型、视图和控制器。其中,模型表示客户端发送的数据,视图表示用户界面,控制器负责处理请求并将数据传递给相应的视图进行渲染。Struts2还提供了拦截器机制,可以在请求到达控制器之前对其进行拦截和处理,从而实现更加灵活的功能扩展。
Spring MVC的原理
Spring MVC是一个基于MVC设计模式的Web框架,它将请求分为五个部分:控制器、模型、视图、处理器和视图解析器。其中,控制器负责处理请求并将数据传递给相应的模型进行处理,模型表示业务数据,视图表示用户界面,处理器负责对模型和视图进行处理,视图解析器负责将处理器返回的结果转换为最终的视图。Spring MVC还提供了拦截器机制,可以在请求到达控制器之前对其进行拦截和处理,从而实现更加灵活的功能扩展。
区别:
-
设计理念不同:Struts2是基于MVC设计模式的Web框架,而Spring MVC则是基于MVC、AOP和IOC(Inversion of Control)设计模式的Web框架。
-
工作流程不同:在Struts2中,请求会先经过拦截器进行处理,然后再由Action处理请求;而在Spring MVC中,请求会先由DispatcherServlet接收,然后再由HandlerMapping找到对应的Controller处理请求。
-
配置方式不同:在Struts2中,配置文件通常以
.xml或.properties格式存在;而在Spring MVC中,配置文件通常以.xml或.java格式存在。 -
功能扩展方式不同:在Struts2中,可以通过编写Interceptor来扩展功能;而在Spring MVC中,可以通过编写HandlerInterceptor或者ControllerAdvice来扩展功能。
说一下 Memcached、Redis 和 MongoDB
Memcached、Redis 和 MongoDB 都是常用的 NoSQL 数据库,但它们的特点、区别和应用场景有所不同。
1. Memcached
Memcached 是一种高性能的分布式内存对象缓存系统,主要用于减轻数据库的负载。它的特点包括:
-
简单:Memcached 只支持键值存储,没有复杂的数据结构。
-
高性能:Memcached 的读写性能非常高,可以轻松处理高并发请求。
-
分布式:Memcached 支持分布式部署,可以通过添加节点来扩展性能。
-
不支持持久化:Memcached 不支持数据持久化,数据只存在于内存中。
应用场景:Memcached 适用于需要高速缓存的场景,如 Web 应用程序中的会话管理、页面缓存等。
2. Redis
Redis 是一种高性能的键值存储系统,支持多种数据结构,包括字符串、哈希、列表、集合、有序集合等。它的特点包括:
-
多种数据结构:Redis 支持多种数据结构,可以满足不同的应用需求。
-
数据持久化:Redis 支持数据持久化,可以将内存中的数据异步地写入磁盘,以保证数据的可靠性。
-
支持事务:Redis 支持事务,可以将多个命令封装成一个事务进行执行,保证数据的一致性。
-
支持分布式:Redis 支持分布式部署,可以通过添加节点来扩展性能。
应用场景:Redis 适用于需要高速缓存和数据存储的场景,如 Web 应用程序中的会话管理、页面缓存、消息队列等。
3. MongoDB
MongoDB 是一种面向文档的 NoSQL 数据库,它采用了类似于 JSON 的文档格式来存储数据。它的特点包括:
-
面向文档:MongoDB 是一种面向文档的数据库,每个文档可以包含不同的字段,非常灵活。
-
支持复杂查询:MongoDB 支持复杂的查询和聚合操作,可以方便地进行数据分析。
-
支持分布式:MongoDB 支持分布式部署,可以通过添加节点来扩展性能。
-
不支持事务:MongoDB 不支持事务,不能保证数据的一致性。
应用场景:MongoDB 适用于需要存储大量非结构化数据的场景,如 Web 应用程序中的日志、用户行为数据等。
对比一下 memcache、redis
Memcache和Redis都是流行的高性能、高可用性的内存缓存系统,它们都提供了多种数据结构和操作模式,可以满足不同场景下的需求。下面是它们的一些对比:
-
数据类型:Memcache支持键值对(key-value)存储,而Redis支持更多的数据类型,包括字符串、哈希表、列表、集合等。
-
性能:Memcache的性能比Redis略高,因为它使用单线程模型和简单的内存结构。但是,Redis通过使用多线程模型和更复杂的数据结构来提高性能。
-
可靠性:Memcache具有较高的可靠性,因为它是基于内存的,并且支持持久化存储。Redis也具有较高的可靠性,但是需要进行数据备份和恢复操作。
-
扩展性:Redis具有更好的扩展性,因为它可以通过集群部署方式来扩展节点数量,从而提高性能和容错能力。Memcache不支持集群部署,只能通过增加服务器数量来扩展。
-
功能:Redis提供了更多的功能,例如发布订阅、Lua脚本支持等,而Memcache则相对较简单。
总之,Memcache适合于简单的缓存场景,而Redis则适合于更复杂的应用场景,例如实时消息传递、排行榜等。选择哪种缓存系统取决于具体的需求和场景。
说说 memcached 默认过期时间
Memcached是一种内存缓存系统,它可以缓存各种类型的数据,如字符串、对象、图像等。在Memcached中,每个缓存条目都有一个过期时间,一旦过期时间到了,该条目就会自动从缓存中删除。
Memcached的默认过期时间是0,即永不过期。这意味着,如果你没有显式地设置过期时间,那么缓存的条目将会一直存在,直到你手动删除它们或者Memcached的内存空间被占满。
当然,你也可以通过设置过期时间来控制缓存的生命周期。在Memcached中,可以通过向set()方法传递第三个参数来设置过期时间,例如:
set('key', 'value', 3600) # 将key-value对缓存1小时
在上面的例子中,缓存的过期时间为3600秒,即1小时。当1小时过去后,该条目就会自动从缓存中删除。
需要注意的是,Memcached的过期时间只是一个估计值,它并不是绝对准确的。如果你的缓存系统非常繁忙,那么可能会出现过期时间延迟的情况。因此,在设计缓存系统时,需要合理设置过期时间,避免出现过期时间延迟导致的缓存不一致问题。
说说 redis 数据结构
Redis支持多种数据结构,包括:
-
字符串(String):Redis的最基本的数据结构,可以存储字符串、整数或者浮点数。
-
列表(List):Redis的列表是一个双向链表,可以在头部或尾部添加或删除元素,支持各种操作,如范围查询、插入、删除等。
-
集合(Set):Redis的集合是无序的字符串集合,可以进行交集、并集、差集等操作。
-
有序集合(ZSet):Redis的有序集合是在集合的基础上增加了一个权重值,可以根据权重值进行排序,支持各种操作,如范围查询、插入、删除等。
-
哈希(Hash):Redis的哈希是一个键值对集合,可以储存多个键值对,支持各种操作,如添加、删除、查找等。
除了这些基本的数据结构,Redis还支持一些高级数据结构,如:
-
布隆过滤器(Bloom Filter):一种概率型数据结构,可以快速判断一个元素是否存在于一个集合中,可以用于快速判断一个URL是否已经被爬取过,或者一个邮箱地址是否已经被注册过。
-
HyperLogLog:一种基数算法,可以用于快速统计一个集合中元素的数量,如统计一个网站的独立访客数量。
-
地理位置(Geo):可以储存地理位置信息,支持各种操作,如查询两个位置之间的距离、查询某个位置周围的其他位置等。
总之,Redis提供了丰富的数据结构,可以满足各种不同的应用场景。
说说全量复制和增量复制
全量复制和增量复制是数据备份和恢复中的两个重要概念。
全量复制指的是将所有数据从一个数据库实例复制到另一个数据库实例中,包括所有的数据、结构和配置信息等。这种方式适用于需要完全一致的数据备份和恢复的情况,比如在进行数据库迁移或者数据库重建时。但是,全量复制的缺点是数据量大、复制时间长,而且对于源数据库和目标数据库之间的差异处理比较困难。
增量复制指的是只复制源数据库中发生变化的数据到目标数据库中。这种方式适用于只需要部分数据备份和恢复的情况,比如在进行数据库更新或者数据同步时。增量复制的优点是速度快、效率高、成本低,而且对于源数据库和目标数据库之间的差异处理比较容易。
总之,全量复制和增量复制都有各自的优缺点,具体使用哪种方式取决于具体的应用场景和需求。
说一下 MongoDB
MongoDB是一种NoSQL数据库,它采用文档存储方式,支持动态查询和索引。下面是MongoDB的特性、优缺点和应用。
特性:
-
支持动态查询和索引:MongoDB使用BSON(Binary JSON)格式存储数据,支持动态查询和索引,可以快速查询和分析数据。
-
支持复制和故障转移:MongoDB支持复制和故障转移,可以保证数据的高可用性和可靠性。
-
支持分片:MongoDB支持自动分片,可以扩展到大规模数据集。
-
支持MapReduce:MongoDB支持MapReduce,可以进行复杂的数据分析和聚合。
-
支持全文搜索:MongoDB支持全文搜索,可以对文本进行高效的搜索和分析。
优点:
-
高性能:MongoDB采用内存映射和预分配空间等技术,可以实现高性能的读写操作。
-
易于扩展:MongoDB支持自动分片和复制,可以方便地进行扩展。
-
灵活性:MongoDB采用文档存储方式,可以方便地存储结构不固定的数据。
-
易于使用:MongoDB使用简单,支持多种编程语言和平台。
缺点:
-
不支持事务:MongoDB不支持多文档事务,只支持单文档事务。
-
存储空间占用较大:MongoDB采用BSON格式存储数据,存储空间占用较大。
-
不支持复杂查询:MongoDB不支持复杂查询,如多表连接等。
应用:
-
Web应用:MongoDB可以用于Web应用的数据存储和查询。
-
大数据分析:MongoDB支持MapReduce,可以用于大数据分析。
-
日志处理:MongoDB可以用于日志处理和分析。
-
移动应用:MongoDB可以用于移动应用的数据存储和查询。
总的来说,MongoDB是一种高性能、易扩展、灵活性强的NoSQL数据库,适用于多种应用场景。















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









