







简介
人工智能好啊,那就做一个系列吧
机器学习,是人工智能的一个分支

开发步骤:
收集数据——爬虫,实际生活的数据
数据格式处理—格式规范化,清洗垃圾数据(有些数据人为制造具有误导性,比如自然语言学习里的种族歧视语言,有些数据残缺不全)
使用算法训练模型----模型会有一个评估函数进行评估,模型在得到数据后不断迭代,最终符合期望的准确率
实际应用模型(明确问题需求,根据问题使用相应算法,使用框架等手段实现具体业务)
Scikit-learn与特征工程
机器学习前,对数据进行预处理
特征抽取
“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,数据决定了机器学到了什么,而算法教给机器怎么学
好的数据有助于机器建立一个准确、简单而高效的模型
大部分直接拿过来的数据都是特征不明显的、没有经过处理的或者说是存在很多无用的数据,那么需要进行一些特征处理,特征的缩放等等,满足训练数据的要求。比如判定一个人的性别,头发颜色,皮肤颜色等等都不是重要数据
同时,原始数据也需要进行转换,变成计算机可读的形式,这意味着一些字符串会变成数值形式等
对于原始数据需要数值化,进行特征工程
数据算法相同,如果特征工程不好,结果也不会很好
安装sklearn
数据来源
机器学习的数据不存储在数据库中,而是⽂件csv
因为数据库有瓶颈,因为历史原因,GIL锁为了保证数据安全,多线程其实是伪的,机器学习动辄数G的数据,数据库表现不好。如今numpy的多线程是真的在并行,读取速度很高
mysql:
1、性能瓶颈,读取速度
2、格式不太符合机器学习要求数据的格式 特征值,目标值
数据处理
机器学习对于重复值不敏感,所以不必去重
但是对于缺失值,需要处理
特征工程中最重要的一个环节就是特征处理,特征处理包含了很多具体的专业技巧
特征预处理
单个特征
归一化
标准化
缺失值
多个特征
降维
PCA
特征抽取,字典类型
字典特征抽取
作用:对字典数据进行特征值化
类:sklearn.feature_extraction.DictVectorizer
DictVectorizer语法
DictVectorizer(sparse=True,…)
为true data返回sparse矩阵,使用toarray可以看到数组矩阵,false返回数组矩阵
DictVectorizer.fit_transform(X)
X:字典或者包含字典的迭代器
返回值:返回sparse矩阵
矩阵如图:
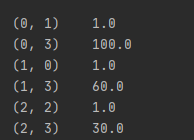
前面是矩阵的坐标,后者是矩阵的值,这种方式十分节约内存
实际矩阵是:
字典数据抽取:把字典中⼀些类别数据,分别进⾏转换成特征,通过这种格式将字典类型的数据,转化为数字,特征成为了一列
数组形式,有类别的这些特征 先要转换字典数据
特征要么存在1,要么不存在0,这种编码方式被称为one-hot编码,这样每一组数据,包含着各自的特征,就容易被计算机理解了
DictVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
DictVectorizer.get_feature_names()
返回类别名称,即矩阵的列名
DictVectorizer.transform(X)
按照原先的标准转换
案例
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
字典数据抽取
:return: None
"""
# 实例化
dict = DictVectorizer(sparse=False)
# 调用fit_transform
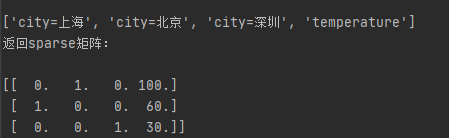
data = dict.fit_transform([{'city': '北京','temperature': 100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature': 30}])
print("列名:\n")
print(dict.get_feature_names())
print("返回sparse矩阵:\n")
print(data)
print("矩阵或者数组转换到新的形式?\n")
print(dict.inverse_transform(data))
if __name__ == '__main__':
dictvec()
特征抽取,文本类型
字符数值化
# 特征抽取
#
# 导入包
from sklearn.feature_extraction.text import CountVectorizer
# 实例化CountVectorizer
vector = CountVectorizer()
# 调用fit_transform输入并转换数据
res = vector.fit_transform(["life is short,i like python","life is too long,i dislike python"])
# 打印结果
print(vector.get_feature_names())
print(res.toarray())
['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too']
[[0 1 1 1 0 1 1 0]
[1 1 1 0 1 1 0 1]]
规律:重复的只统计一次;单个字母不统计;在列表里统计每个词出现的次数
将字符拆分,用矩阵表现了他们的区别
怎么看出来的?
将[‘dislike’, ‘is’, ‘life’, ‘like’, ‘long’, ‘python’, ‘short’, ‘too’]看做列名,下面的0代表未出现此单词,1代表出现
作用:对文本数据进行特征值化,变成数字,这样方便处理
类:sklearn.feature_extraction.text.CountVectorizer
CountVectorizer语法
CountVectorizer(max_df=1.0,min_df=1,…)
返回词频矩阵
CountVectorizer.fit_transform(X,y)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
CountVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
CountVectorizer.get_feature_names()
返回值:单词列表
用途:
文本分类,情感分析,
然而对于中文来说并不可行,英文有空格作为分割单词,中文连续,只有在遇到空格或者逗号等符号的时候才会认为这是一个词,往往把一大段话错误识别成了一个词,因此需要先试用jieba分词器分词,得到词语分组,
再进行转化为矩阵
def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 吧列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def hanzivec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
cv = CountVectorizer()
data = cv.fit_transform([c1, c2, c3])
print(cv.get_feature_names())
print(data.toarray())
return None
结果

就像英文一样,自动过滤了单个词,同时记录了每个词语出现的次数
然而这样就能够根据词语得到文章的类别了吗?
因为有大量介词与中性词的存在,比如因为。。所以,那么如何让机器知道哪些词才是决定性的呢?
Tf:term frequency:词的频率 出现的次数
idf:逆⽂档频率inverse document frequency log(总⽂档数量/该词出现的⽂档数量)
由log确定,词语出现在多个文档中的频率越高,重要性开始下降
tf * idf 以此来衡量词语的重要性程度
TF-IDF
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,
并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分
能力,适合用来分类。
类:sklearn.feature_extraction.text.TfidfVectorizer
TfidfVectorizer语法
TfidfVectorizer(stop_words=None,…)
返回词的权重矩阵
TfidfVectorizer.fit_transform(X,y)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
TfidfVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
TfidfVectorizer.get_feature_names()
返回值:单词列表
案例
def tfidfvec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
tf = TfidfVectorizer()
data = tf.fit_transform([c1, c2, c3])
print(tf.get_feature_names())
print(data.toarray())
return None
结果

如图生成了一个重要性矩阵,在评判文章时可以抽出重要的词进行判别
然而,这个方法并不高明,随着神经网络的展开,有更好的方法对文章进行分类分析















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









