







Abstract
尽管基于深度学习的视频识别模型取得了显著的成功,但它们很容易受到通过在纯净的视频样本上添加人类感觉不到的干扰而产生的对抗样本的影响。正如最近的研究所表明的那样,对抗样本是可迁移的,这使得在现实应用中进行黑盒攻击是可行的。然而,大多数现有的对抗攻击方法在攻击其他视频模型时具有很差的可迁移性,基于迁移的视频模型攻击仍有待探索。为此,我们建议提高视频识别模型中黑盒攻击的视频对抗样本的可迁移性。通过广泛的分析,我们发现不同的视频识别模型依赖于不同的区分时间模式,导致视频对抗样本的可转移性较差。这促使我们引入了一种时态转换攻击方法,它优化了一组时态转换视频剪辑上的对抗性干扰。通过在转换的视频上生成对抗样本,生成的对抗样本对被攻击的白盒模型中存在的时间模式不那么敏感,因此可以更好地迁移。在Kinetics-400数据集和UCF-101数据集上的大量实验表明,我们的方法可以显著提高视频对抗样本的可迁移性。对于针对视频识别模型的基于迁移的攻击,Kinetics-400和UCF-101的平均攻击成功率分别为61.56%和48.60%。代码可从 https://github.com/zhipeng-wei/TT找到。
Introduction
根据威胁模型,对抗性攻击可分为两类:白盒攻击和黑盒攻击。在白盒设置中,对手可以完全控制和访问DNN模型,包括模型架构和参数。在黑盒设置中,对手只能访问DNN的输出。因此,在黑盒环境下攻击模型更具挑战性。最近的研究表明,对抗样本具有可转移性,因此可以使用白盒模型生成的对抗样本执行黑盒攻击。因此,为了提高黑盒攻击的成功率,已经有了提高对抗样本可迁移性的工作(Dong et al.2018;Xie et al.2019)。然而,现有的研究侧重于提高图像对抗样本的可迁移性,而视频对抗样本的可迁移性尚未被探索。
本文研究了视频对抗样本的可迁移性,以实现视频识别模型中的黑盒攻击。这项任务的主要挑战来自这样一个事实,即生成的对抗样本容易过拟合白盒模型,并且对于其他黑盒模型的可转移性较差。与图像相比,视频具有额外的时间维度,赋予视频丰富的时间信息来描述动态线索(例如,运动)。为了捕捉如此丰富的时间信息,设计了各种基于3D卷积神经网络(CNN)的视频识别模型(例如,I3D(Carreira and Zisserman 2017)、SlowFast(Feichtenhofer et al.2019))。直观地说,视频识别模型捕获的区分性时间模式可能因不同的体系结构而异。由于生成的对抗样本与白盒模型的这种模式或梯度高度相关,直接利用白盒模型生成的对抗视频样本攻击其他黑盒视频识别模型可能会导致不满意的结果。
为了提高视频对抗样本的可迁移性,本文提出了一种时间转换方法以生成在不同视频模型中具有良好通用性的对抗样本 。其关键思想是在一组经过时间转换的视频片段上优化对抗样本。这样,视频对抗样本将对白盒模型的鉴别性的时间模式不那么敏感,并且具有更高的可转移性。我们的方法受(Dong等人,2019)的启发,该方法在图像上采用空间转换,以减轻模型之间不同区分区域的影响,并提高图像对抗样本的可迁移性。
目标攻击是指攻击者试图将模型误导到真实类以外的特定类的攻击。 非目标攻击是指攻击者试图误导模型以预测任何错误类的攻击。
Transfer-based的方法可以从以下五个方向来进行分类:
- data augmentation,即对输入做变换,包括旋转、平移等操作
- 修改迭代时的梯度生成方法,比如借助momentum、Nesterov等方法
- 修改loss,比如使用特征空间的loss,而不是输出层对应的loss
- model ensemble,结合多个模型的输出来做攻击
- model specific,对特定的模型结构做分析,修改不同结构的梯度权重
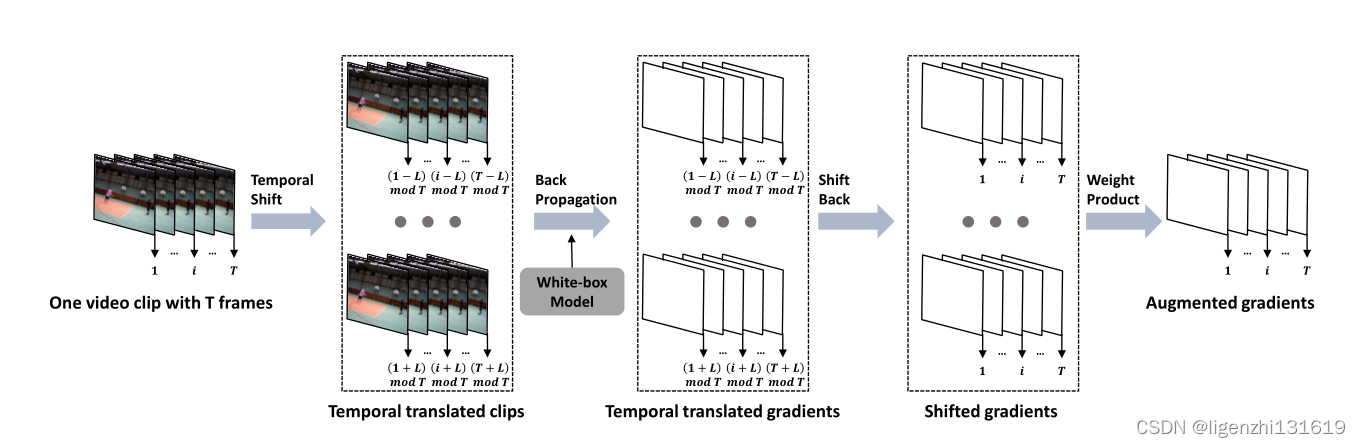
图一:给定一个视频片段,应用时间移位来生成一组视频片段。然后,将从这些时间转换的视频片段中获得的梯度线性组合,形成增强梯度。由于时间转换减轻了视频识别模型之间不同辨别性时间模式的影响,因此由增强梯度生成的对抗视频样本对白盒模型的判别性时间模式不太敏感,因此具有更高的可迁移性。
图1给出了所提出方法的概述。给定一个视频片段,应用具有移位长度L的时间平移来生成一组视频片段。注意,时间平移可以沿时间轴向前和向后执行,因此我们可以获得长度为2L的转换的视频片段。与原始视频片段一起,这些2L+1的视频片段随后被输入到白盒模型中,以获得相应的转换梯度,即损失函数相对于视频片段的梯度。为了获得增强的梯度,将转换后的梯度移回原始时间序列,并通过权重矩阵线性组合。最后,生成的增强梯度用于生成对抗样本,这些对抗样本能够在不同的识别模型中推广。我们简要总结了我们的主要贡献如下:
1、我们研究了视频中基于迁移的攻击,并提出了一种时态转换攻击方法来提高对抗样本的可迁移性。据我们所知,这是关于视频识别模型中基于迁移的黑盒攻击的首次工作。
2、我们对不同模型的判别性时间模式的相关性进行了深入分析,并通过实证证明了视频模型之间的判别性时间模式是不同的。基于这一观察,我们结合时态转换视频的梯度生成具有更高可迁移性的对抗样本。
3、我们使用Kinetics-400 数据集和UCF-101数据集训练的六个视频识别模型进行实证评估。大量实验表明,我们提出的方法有助于大幅度提高视频对抗样本的可迁移性。
Methodolog
给定一个视频样本x ,y为
,y为















 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









