







CS229 Lecture 6
本节课重点
Naive Bayes
神经网络
支持向量机
回顾上节课的内容:
将一封邮件表示成一个向量
[
1
0
⋮
1
⋮
]
\begin{bmatrix}1\\0\\\vdots\\1\\\vdots\end{bmatrix}
⎣⎢⎢⎢⎢⎢⎢⎡10⋮1⋮⎦⎥⎥⎥⎥⎥⎥⎤,这个向量的长度为字典的大小,这个向量中的数字只能为0和1,即存在或者不存在。将其表示为生成学习算法的模型为:
p
(
x
∣
y
)
=
∏
i
=
1
n
p
(
x
i
∣
y
)
a
r
g
  
m
a
x
y
  
p
(
y
∣
x
)
=
a
r
g
  
m
a
x
y
p
(
x
∣
y
)
p
(
y
)
p(x|y)=\prod_{i=1}^{n}p(x_{i}|y)\\ arg\,\, \mathop{max}\limits_{y}\,\,p(y|x)=arg\,\, \mathop{max}\limits_{y} p(x|y)p(y)
p(x∣y)=i=1∏np(xi∣y)argymaxp(y∣x)=argymaxp(x∣y)p(y)
这个模型一般被称为多元伯努利事件模型。
变种1:
上面的模型中由邮件表示的向量,其元素只能为0或者1,现在改为 x i ∈ { 0 , 1 , ⋯   , k } x_i\in\{0,1,\cdots,k\} xi∈{0,1,⋯,k}。那么生成学习模型的 p ( x ∣ y ) = ∏ i = 1 n p ( x i ∣ y ) p(x|y)=\prod_{i=1}^{n}p(x_i|y) p(x∣y)=∏i=1np(xi∣y)。这时的 x i x_i xi属于多项式分布而非原来的伯努利分布。
如果由一个变量属于连续变量如何将其离散化为 k k k个值。比如将房屋居住面积离散为几个值那么:
| l i v i n g    a r e a living\,\,area livingarea | < 500 <500 <500 | 500 ∼ 1000 500\sim1000 500∼1000 | 1000 ∼ 1500 1000\sim1500 1000∼1500 | ⋯ \cdots ⋯ |
|---|---|---|---|---|
| x | 1 | 2 | 3 | - |
变体2:多项式事件模型
因为前面的模型都忽略了每个词出现的次数,词出现的次数可能对于文本的分类,如是否为一封垃圾邮件有很大的影响。现在对于一封邮件将其表示为 { x 1 ( i ) , x 2 ( i ) , x 3 ( i ) , x 4 ( i ) , ⋯ x n i ( i ) } \{x_{1}^{(i)},x_{2}^{(i)},x_{3}^{(i)},x_{4}^{(i)},\cdots x_{n_{i}}^{(i)} \} {x1(i),x2(i),x3(i),x4(i),⋯xni(i)},其中 n i n_{i} ni表示第 i i i封邮件的单词数目。且 x j ∈ { 1 , 2 , 3 , ⋯ 50000 } x_j\in\{1,2,3,\cdots 50000\} xj∈{1,2,3,⋯50000}。这个模型的对应生成学习算法为:
p ( x y ) = ( ∏ i = 1 n p ( x i ∣ y ) ) p ( y ) p(xy)=(\prod_{i=1}^{n}p(x_i|y))p(y) p(xy)=(∏i=1np(xi∣y))p(y)
模型涉及到的参数为:
ϕ
k
∣
y
=
1
=
p
(
x
j
=
k
∣
y
=
1
)
\phi_{k|y=1}=p(x_j=k|y=1)
ϕk∣y=1=p(xj=k∣y=1)
ϕ
k
∣
y
=
0
=
p
(
x
j
=
k
∣
y
=
0
)
\phi_{k|y=0}=p(x_j=k|y=0)
ϕk∣y=0=p(xj=k∣y=0)
ϕ
y
=
p
(
y
=
1
)
\phi_{y}=p(y=1)
ϕy=p(y=1)
关于这些参数的极大似然估计为:
ϕ
k
∣
y
=
1
=
∑
i
=
1
m
1
{
y
i
=
1
}
∑
j
=
1
n
i
1
{
x
j
i
=
k
}
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
n
i
\phi_{k|y=1}=\frac{\sum_{i=1}^{m}1\{y^{i}=1\}\sum_{j=1}^{n_{i}}1\{x_{j}^{i}=k\}}{\sum_{i=1}^{m}1\{y^{(i)}=1\}n_{i}}
ϕk∣y=1=∑i=1m1{y(i)=1}ni∑i=1m1{yi=1}∑j=1ni1{xji=k}
如果对上式子添加Laplace 平滑处理则有:
ϕ k ∣ y = 1 = ∑ i = 1 m 1 { y i = 1 } ∑ j = 1 n i 1 { x j i = k } + 1 ∑ i = 1 m 1 { y ( i ) = 1 } n i + 50000 \phi_{k|y=1}=\frac{\sum_{i=1}^{m}1\{y^{i}=1\}\sum_{j=1}^{n_{i}}1\{x_{j}^{i}=k\}+1}{\sum_{i=1}^{m}1\{y^{(i)}=1\}n_{i}+50000} ϕk∣y=1=∑i=1m1{y(i)=1}ni+50000∑i=1m1{yi=1}∑j=1ni1{xji=k}+1
其中假设字典的大小为 50000 50000 50000
关于Laplace 平滑分母添加的值:
如果说 x i ∈ { 1 , 2 , 3 , ⋯   , l } x_i\in\{1,2,3,\cdots,l\} xi∈{1,2,3,⋯,l},那么 p ( x = k ) = 观 测 到 x = k 的 数 目 + 1 观 测 到 的 x 数 目 + l p(x=k)=\frac{观测到x=k的数目+1}{观测到的x数目+l} p(x=k)=观测到的x数目+l观测到x=k的数目+1。
求解极大似然估计的公式为:
L ( ϕ k ∣ y = 1 , ϕ k ∣ y = 0 , ϕ y ) = l o g ∏ i = 1 m p ( x ( i ) , y ( i ) ; ϕ k ∣ y = 1 , ϕ k ∣ y = 0 , ϕ y ) = l o g ∏ i = 1 m ∏ j = 1 n i p ( x j ( i ) ∣ y ( i ) ; ϕ k ∣ y = 1 , ϕ k ∣ y = 0 ) p ( y ( i ) ; ϕ y ) L(\phi_{k|y=1},\phi_{k|y=0},\phi_{y})=log\prod_{i=1}^{m}p(x^{(i)},y^{(i)};\phi_{k|y=1},\phi_{k|y=0},\phi_{y})=log\prod_{i=1}^{m}\prod_{j=1}^{n_i}p(x_{j}^{(i)}|y^{(i)};\phi_{k|y=1},\phi_{k|y=0})p(y^{(i)};\phi_{y}) L(ϕk∣y=1,ϕk∣y=0,ϕy)=log∏i=1mp(x(i),y(i);ϕk∣y=1,ϕk∣y=0,ϕy)=log∏i=1m∏j=1nip(xj(i)∣y(i);ϕk∣y=1,ϕk∣y=0)p(y(i);ϕy)
非线性分类器
前面学到的逻辑回归只是线性分类器,但是在有些情况下数据并非线性可分的。这时就需要用到非线性分类器。
神经网络
神经网络分为输入层,隐层和输出层。通过反向传播(梯度下降)求解最优参数。
J ( θ ) = 1 2 ∑ i = 1 m ( y ( i ) − h θ ( x ( i ) ) ) 2 J(\theta)=\frac{1}{2}\sum_{i=1}^{m}(y^{(i)}-h_{\theta}(x^{(i)}))^2 J(θ)=21i=1∑m(y(i)−hθ(x(i)))2
SVM
支持向量机算法是一种高效无需定制可以作为线性分类的算法,并且对其进行部分优化后,可以转化为非线性分类算法。
在前面学习的逻辑回归中:
如果 θ T x ≥ 0 \theta^T x\ge0 θTx≥0,那么算法认为预测值为1
如果 θ T x < 0 \theta^T x <0 θTx<0,那么算法认为预测值为0.
如果说 θ T x ≫ 0 \theta^Tx\gg0 θTx≫0,那么我们很确信预测值就是1.
如果说 θ T x ≪ 0 \theta^Tx\ll0 θTx≪0,那么我们很确信预测值就是0。
我们训练一个分类算法,我们认为这个算法训练的好,不仅要求其对数据分类正确,而且要求其对分类结果十分确信。即:
∀
i
  
s
.
t
  
y
(
i
)
=
1
   
h
a
v
e
   
θ
T
x
≫
0
\forall i\,\,s.t\,\,y^{(i)}=1\,\,\,have\,\,\,\theta^Tx\gg0
∀is.ty(i)=1haveθTx≫0
∀
i
  
s
.
t
  
y
(
i
)
=
0
   
h
a
v
e
   
θ
T
x
≪
0
\forall i\,\,s.t\,\,y^{(i)}=0\,\,\,have\,\,\,\theta^Tx\ll0
∀is.ty(i)=0haveθTx≪0
下面假设数据线性可分。
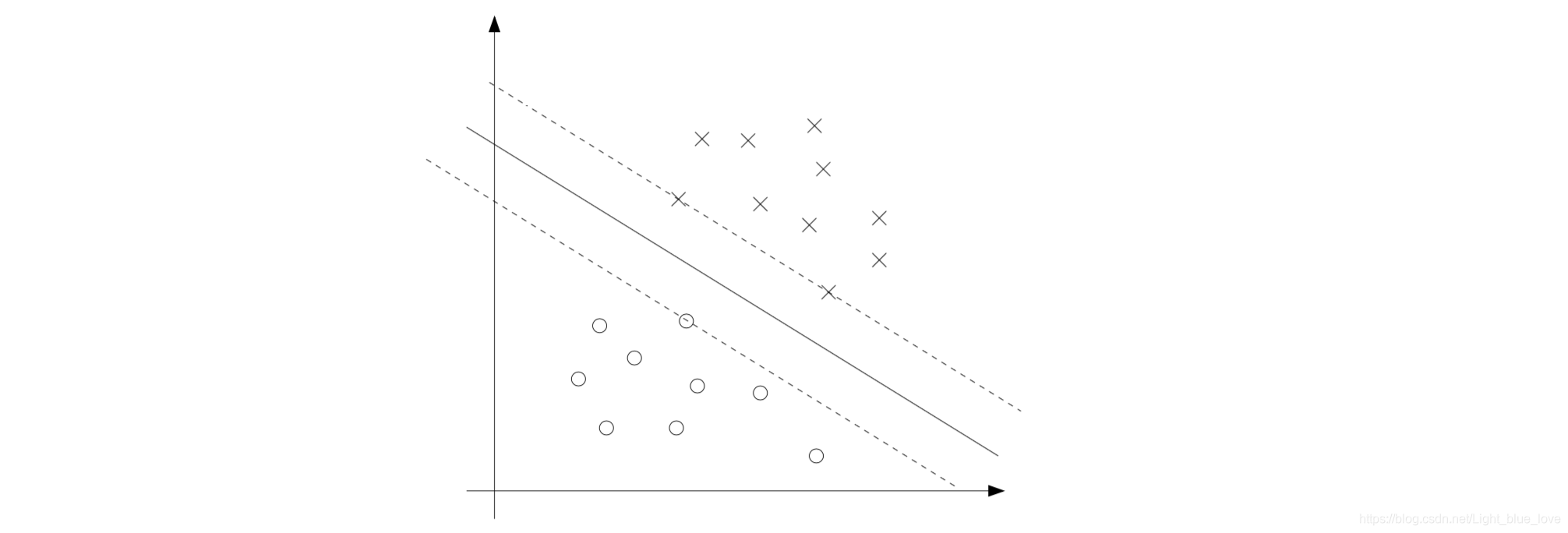
从上面的图片中可以看出有三条线均可以将数据圆和叉分开,但是哪一条线才是最好的呢,很明显当然是中间的那条实线。因为这条线对两类数据都有一定的间隔,而两条虚线均对某类数据太过靠近,以至于只要边界上某个点稍微移动一点点,那么就可能会预测错误。
符号定义
在SVM中 y ∈ { − 1 , 1 } y\in\{-1,1\} y∈{−1,1},因此 h ∈ { − 1 , 1 } h\in\{-1,1\} h∈{−1,1}。且在现在的设定中去掉了 x 0 = 1 x_0=1 x0=1这一项 h w , b ( x ) = g ( w T x + b ) h_{w,b}(x)=g(w^Tx+b) hw,b(x)=g(wTx+b)。现在公式中的 w w w相当于 [ θ 1 θ 2 ⋮ θ n ] \begin{bmatrix}\theta_1\\\theta_2\\\vdots\\\theta_n\end{bmatrix} ⎣⎢⎢⎢⎡θ1θ2⋮θn⎦⎥⎥⎥⎤,而 b b b相当于 θ 0 \theta_0 θ0。其中 g ( z ) = { 1 i f    z ≥    0 − 1 o t h e r w i s e g(z)=\begin{cases}1 & if \,\,z\ge\,\,0\\-1&otherwise\end{cases} g(z)={1−1ifz≥0otherwise。 w w w是 n n n维向量。
函数间隔(Function Margin of hyper plane w,b)
对于一个分类样本 ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i))其对于分类超平面( w , b w,b w,b)的函数间隔的定义为 γ ^ ( i ) = y ( i ) ( w T x ( i ) + b ) \hat\gamma^{(i)}=y^{(i)}(w^Tx^{(i)}+b) γ^(i)=y(i)(wTx(i)+b)。
如果 y ( i ) = 1 y^{(i)}=1 y(i)=1,我们期望 w T x ( i ) + b ≫ 0 w^Tx^{(i)}+b\gg0 wTx(i)+b≫0
如果 y ( i ) = − 1 y^{(i)}=-1 y(i)=−1,我们期望 w T x ( i ) + b ≪ 0 w^Tx^{(i)}+b\ll0 wTx(i)+b≪0
y ( i ) ( w T x ( i ) + b ) > 0 y^{(i)}(w^Tx^{(i)}+b)>0 y(i)(wTx(i)+b)>0,这样分类才是正确的。
对于整个训练集的函数间隔的定义为 γ ^ = min i   γ ^ ( i ) \hat\gamma=\mathop {\min }\limits_i\,\hat\gamma^{(i)} γ^=iminγ^(i),在前面说过,仅仅正确预测是不够的,还需要使得预测结果可信度很大,即需要使得 γ ^ \hat\gamma γ^尽可能大,通过观察函数间隔的定义我们可以很容易的想到 w → 2 w    b → 2 b w\rightarrow2w\,\,b\rightarrow 2b w→2wb→2b就可以使 γ ^ 翻 倍 \hat\gamma翻倍 γ^翻倍。但是也很容易理解这样单纯的是 γ ^ \hat\gamma γ^最大并没有什么意义,我们需要限制 ∣ ∣ w ∣ ∣ = 1 ||w||=1 ∣∣w∣∣=1,然后最大化 γ ^ \hat\gamma γ^才有意义。
几何间隔

上面讨论了函数间隔,现在看看几何间隔。上图中点
A
A
A到分解线的距离为
γ
\gamma
γ,交点为
B
B
B,因为
B
B
B在分隔线上因此满足
w
T
(
x
(
i
)
−
γ
(
i
)
w
∣
∣
w
∣
∣
)
+
b
=
0
w^T(x^{(i)}-\gamma^{(i)}\frac{w}{||w||})+b=0
wT(x(i)−γ(i)∣∣w∣∣w)+b=0,其中点
A
A
A的坐标为
x
(
i
)
x^{(i)}
x(i),点
B
B
B的坐标被表示为
x
(
i
)
−
γ
(
i
)
w
∣
∣
w
∣
∣
x^{(i)}-\gamma^{(i)}\frac{w}{||w||}
x(i)−γ(i)∣∣w∣∣w。进而可以得出:
w
T
x
(
i
)
+
b
=
γ
(
i
)
w
T
w
∣
∣
w
∣
∣
=
γ
(
i
)
∣
∣
w
∣
∣
γ
(
i
)
=
w
T
∣
∣
w
∣
∣
x
+
b
∣
∣
b
∣
∣
w^Tx^{(i)}+b=\gamma^{(i)}\frac{w^Tw}{||w||}=\gamma^{(i)}||w||\\ \gamma^{(i)}=\frac{w^T}{||w||}x+\frac{b}{||b||}
wTx(i)+b=γ(i)∣∣w∣∣wTw=γ(i)∣∣w∣∣γ(i)=∣∣w∣∣wTx+∣∣b∣∣b
通常我们会将几何间隔表示为:
γ
(
i
)
=
y
(
i
)
[
w
T
∣
∣
w
∣
∣
x
(
i
)
+
b
∣
∣
b
∣
∣
]
\gamma^{(i)}=y^{(i)}[\frac{w^T}{||w||}x^{(i)}+\frac{b}{||b||}]
γ(i)=y(i)[∣∣w∣∣wTx(i)+∣∣b∣∣b]
可以看出如果说 ∣ ∣ w ∣ ∣ = 1 ||w||=1 ∣∣w∣∣=1,那么 γ ^ ( i ) = γ ( i ) \hat\gamma^{(i)}=\gamma^{(i)} γ^(i)=γ(i),但是更一般的情形是 γ ( i ) = γ ^ ( i ) ∣ ∣ w ∣ ∣ \gamma^{(i)}=\frac{\hat\gamma^{(i)}}{||w||} γ(i)=∣∣w∣∣γ^(i)。
对于一批数据其几何间隔的定义为:
γ = min i γ ( i ) \gamma=\mathop {\min }\limits_i\gamma^{(i)} γ=iminγ(i)
最大间隔分类器
其主要思想就是让间隔最大,进而使得预测出来的结果更为可信。
max γ ; w , b γ s . t      y ( i ) ( w T x ( i ) + b ) ≥ γ ∣ ∣ w ∣ ∣ = 1 \mathop {\max }\limits_{\gamma;w,b}\gamma\\ s.t\,\,\,\,y^{(i)}(w^Tx^{(i)}+b)\ge\gamma\\ ||w||=1 γ;w,bmaxγs.ty(i)(wTx(i)+b)≥γ∣∣w∣∣=1
在这些限定下即使让 w → 10 w , b → 10 b w\rightarrow10w,b\rightarrow10b w→10w,b→10b也不会改变其几何间隔。
函数间隔的定义应当是来源于直观理解:逻辑回归中,只要 θ T x > 0 \theta^Tx>0 θTx>0,那么我们就认为其预测结果为1,我们知道 θ T x \theta^Tx θTx的值越大,那么其预测出来的结果越可信,因为计算出来的值刚好距离分界线不远,你说它是正常邮件还是垃圾邮件都是可以的,如果说 θ T x ≫ 0 \theta^Tx\gg0 θTx≫0,那么我们认为它有很大几率是一封垃圾邮件。在支持向量机中 g ( z ) = { 1 i f    z ≥    0 − 1 o t h e r w i s e g(z)=\begin{cases}1 & if \,\,z\ge\,\,0\\-1&otherwise\end{cases} g(z)={1−1ifz≥0otherwise,其中 z = w T x + b z=w^Tx+b z=wTx+b,因此有了函数间隔的定义 γ ^ ( i ) = y ( i ) ( w T x ( i ) + b ) \hat\gamma^{(i)}=y^{(i)}(w^Tx^{(i)}+b) γ^(i)=y(i)(wTx(i)+b),即这个值越大约可信,但是如果没有限定条件单纯的大没有什么用,因此引入了几何间隔,几何间隔是来自于对几何距离的直观求解。














 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









