







活动地址:CSDN21天学习挑战赛
往期回顾:
数据分析—pandas(一)
数据分析—pandas(二)
数据重塑和轴向旋转
层次化索引
层次化索引是pandas的一项重要功能,它能使我们在一个轴上拥有多个索引
- series的层次化索引:
import pandas as pd
import numpy as np
s = pd.Series(np.arange(1,10), index = [['a','a','a','b','b','c','c','d','d'], [1,2,3,1,2,3,1,2,3]])
print(s) #类似于合并单元格
>>>
a 1 1
2 2
3 3
b 1 4
2 5
c 3 6
1 7
d 2 8
3 9
dtype: int32
print(s.index)
>>>
MultiIndex([('a', 1),
('a', 2),
('a', 3),
('b', 1),
('b', 2),
('c', 3),
('c', 1),
('d', 2),
('d', 3)],
)
print(s['a']) #外层索引
>>>
1 1
2 2
3 3
dtype: int32
print(s['a':'c']) #切片
>>>
a 1 1
2 2
3 3
b 1 4
2 5
c 3 6
1 7
dtype: int32
print(s[:,1]) #内层索引
>>>
a 1
b 4
c 7
dtype: int32
通过unstack方法可以将Series变成一个DataFrame
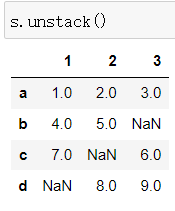
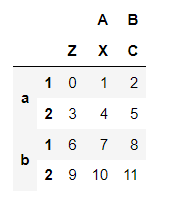
- Dataframe的层次化索引:
对于DataFrame来说,行和列都能进行层次化索引。
data = pd.DataFrame(np.arange(12).reshape(4,3), index = [['a','a','b','b'],[1,2,1,2]], columns = [['A','A','B'],['Z','X','C']])
data
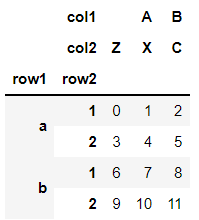
对行与列进行命名
data.index.names = ["row1","row2"]
data.columns.names = ["col1", "col2"]
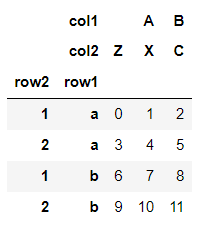
对与行位置的调整
data.swaplevel("row1","row2") #位置调整
set_index可以把列变成索引
reset_index是把索引变成列
- 取消层次化索引
reset_index()
数据旋转
.T可以直接让数据的行列进行交换
dataframe也可以使用stack和unstack,转化为层次化索引的Series
数据分组,分组运算
GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表
import pandas as pd
import numpy as np
df = pd.read_excel(r'C:\Users\数据分析\movie2.xlsx', index_col = 0)
# 按照电影的产地进行分组
group = df.groupby(df["产地"])
# 可以计算分组后各个的统计量
print(group.mean())
只会对数值变量进行分组运算
我们也可以传入多个分组变量
import pandas as pd
import numpy as np
df = pd.read_excel(r'C:\Users\数据分析\movie2.xlsx', index_col = 0)
print(df.groupby([df["产地"],df["年代"]]).mean()) #根据两个变量进行分组
离散化处理
在实际的数据分析项目中,对有的数据属性,我们往往并不关注数据的绝对取值,只关心它所处的区间或者等级
比如,我们可以把评分9分及以上的电影定义为A,7到9分定义为B,5到7分定义为C,3到5分定义为D,小于3分定义为E。
离散化也可称为分组、区间化。
Pandas为我们提供了方便的函数cut():
pd.cut(x,bins,right = True,labels = None, retbins = False,precision = 3,include_lowest = False)
参数解释:
- x:需要离散化的数组、Series、DataFrame对象
- bins:分组的依据,
- right = True,
- include_lowest = False,默认左开右闭,可以自己调整。
- labels:是否要用标记来替换返回出来的数组,
- retbins:返回x当中每一个值对应的bins的列表,
- precision精度。
import pandas as pd
import numpy as np
df = pd.read_excel(r'C:\Users\数据分析\movie2.xlsx', index_col = 0)
df["评分等级"] = pd.cut(df["评分"], [0,3,5,7,9,10], labels = ['E','D','C','B','A']) #labels要和区间划分一一对应
print(df)
合并数据集
append
先把数据集拆分为多个,再进行合并
import pandas as pd
import numpy as np
df = pd.read_excel(r'C:\Users\数据分析\movie2.xlsx', index_col = 0)
df_usa = df[df.产地 == "中国台湾"]
df_china = df[df.产地 == "中国大陆"]
print(df_china.append(df_usa))
#直接追加到后面,最好是变量相同的
merge
pd.merge(left, right, how = ‘inner’, on = None, left_on = None, right_on = None,left_index = False, right_index = False, sort = True, suffixes = (’_x’, ‘_y’), copy = True, indicator = False, validate=None)
concat
将多个数据集进行批量合并
import pandas as pd
import numpy as np
df = pd.read_excel(r'C:\Users\数据分析\movie2.xlsx', index_col = 0)
df1 = df[:10]
df2 = df[100:110]
df3 = df[200:210]
df4 = pd.concat([df1,df2,df3],axis = 0)
# 默认axis = 0,列拼接需要修改为1
print(df4)
往期回顾:
数据分析—pandas(一)
数据分析—pandas(二)
















 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











