







活动地址:CSDN21天学习挑战赛
数据分析---pandas
数据分析—pandas(二)
上一篇点这里:数据分析—pandas(一)
数据格式转换
- 在做数据分析的时候,原始数据往往会因为各种各样的原因产生各种数据格式的问题。
- 数据格式是我们非常需要注意的一点,数据格式错误往往会造成很严重的后果。
- 并且,很多异常值也是我们经过格式转换后才会发现,对我们规整数据,清洗数据有着重要的作用。
1、查看格式(dtype)
import pandas as pd
import numpy as np
df = pd.read_excel(r"C:\Users\数据分析\movie_data.xlsx",index_col = 0)
print(df["投票人数"].dtype)
>>> dtype('int64')
2、转换格式(astype)
import pandas as pd
import numpy as np
df = pd.read_excel(r"C:\Users\数据分析\movie_data.xlsx",index_col = 0)
df["投票人数"] = df["投票人数"].astype("int") #转换格式
排序
sort_values(by=‘’,ascending)
- 单值排序
默认从小到大,设置ascending=False则从大到小
import pandas as pd
import numpy as np
df = pd.read_excel(r"C:\Users\数据分析\movie_data.xlsx",index_col = 0)
df.sort_values(by = "投票人数", ascending = False)[:5] #默认从小到大
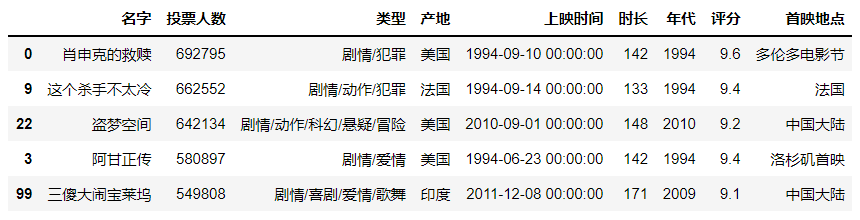
- 多值排序
列表中的顺序决定先后顺序
import pandas as pd
import numpy as np
df = pd.read_excel(r"C:\Users\数据分析\movie_data.xlsx",index_col = 0)
df.sort_values(by = ["评分","投票人数"], ascending = False) #列表中的顺序决定先后顺序
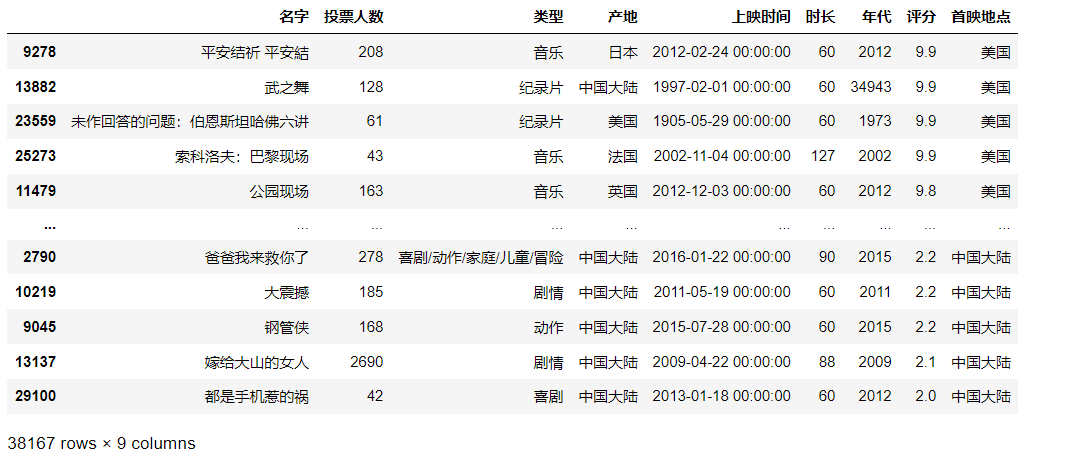
基本统计分析
1、描述性统计
dataframe.describe():对dataframe中的数值型数据进行描述性统计
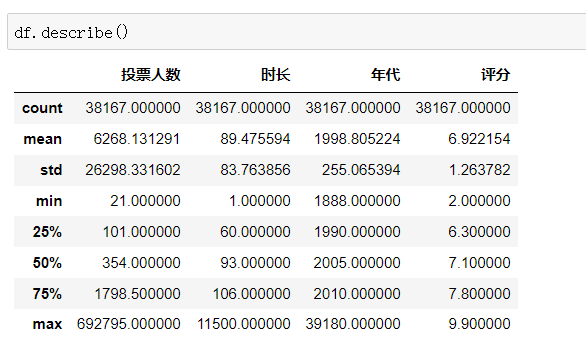
通过描述性统计,可以发现一些异常值,很多异常值往往是需要我们逐步去发现的。
例如:改年代最大值为39180,显然不符合事实。因此我们需要作出修改。
import pandas as pd
import numpy as np
df = pd.read_excel(r"C:\Users\数据分析\movie_data.xlsx",index_col = 0)
df.drop(df[df["时长"] > 1000].index, inplace = True) #删除异常数据
df.index = range(len(df)) #解决删除后索引不连续的问题
print(df)
2、最值
- max() 最大值
- min() 最小值

3、均值和中值
- mean() 均值
- median() 中值

4、方差、标准差
- var() 方差
- std() 标准差

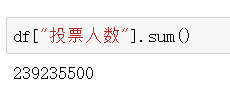
5、求和
- sum()求和
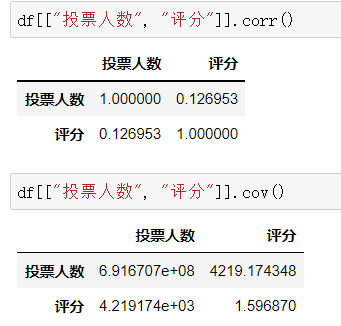
6、相关系数和协方差
- corr() 相关系数
- cov() 协方差
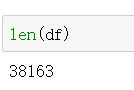
7、计数
- len()求长度,计数
数据透视
-
Excel中数据透视表的使用非常广泛,其实Pandas也提供了一个类似的功能,名为pivot_table。
-
pivot_table非常有用,我们将重点解释pandas中的函数pivot_table。
-
使用pandas中的pivot_table的一个挑战是,你需要确保你理解你的数据,并清楚地知道你想通过透视表解决什么问题。虽然pivot_table看起来只是一个简单的函数,但是它能够快速地对数据进行强大的分析。
pivot_table(df, index, values, aggfunc, fill_value )
1、基础形式
pd.pivot_table(df, index = ["年代"]) #统计各个年代中所有数值型数据的均值(默认)
2、也可以有多个索引。实际上,大多数的pivot_table参数可以通过列表获取多个值。
pd.pivot_table(df, index = ["年代", "产地"]) #双索引
3、也可以指定需要统计汇总的数据
pd.pivot_table(df, index = ["年代", "产地"], values = ["评分"])
4、还可以指定函数,来统计不同的统计值
pd.pivot_table(df, index = ["年代", "产地"], values = ["投票人数"], aggfunc = np.sum)
5、非数值(NaN)难以处理。如果想移除它们,可以使用“fill_value”将其设置为0
pd.pivot_table(df, index = ["产地"], aggfunc = [np.sum, np.mean], fill_value = 0)
6、加入margins = True,可以在下方显示一些总和数据。
pd.pivot_table(df, index = ["产地"], aggfunc = [np.sum, np.mean], fill_value = 0, margins = True)
7、对不同值执行不同的函数:可以向aggfunc传递一个字典。不过,这样做有一个副作用,那就是必须将标签做的更加整洁才行。
pd.pivot_table(df, index = ["产地"], values = ["投票人数", "评分"], aggfunc = {"投票人数":np.sum, "评分":np.mean}, fill_value = 0)
下一篇点这里:数据分析—pandas(三)
















 2391
2391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











