







目录
哈希表原理:
哈希的分类
可以把它简单地理解为数组,但其实它更像python中的字典
哈希集合:
头文件:#include <unordered_set>
创建哈希集合:unordered_set<type> set;
个人理解:
不如创建一个数组,因为创建一个哈希消耗的内存比较大= =,这里数组和哈希集合承担的作用其实是一样的= =
哈希映射:
头文件:#include <unordered_map>
创建哈希映射: unordered_map<type, type> map;
个人理解:
这个就是python的字典,第一个type是键(key),第二个type是值(value),通过键来查询值
可以理解为:在药房,药师通过看抽屉的标签来查询抽屉的药品,标签就是键,药品就是值
所以,哈希相当于用空间换时间,查询哈希的值,要比遍历数组查询值所需的时间要短.
哈希STL函数的使用:
引用哈希集合时的应用:
#include <unordered_set> // 当使用set时引用的模板库
#include<iostream>
using namespace std;
int main() {
// 创建一个哈希集合
unordered_set<int> hashset;
// 插入新的关键字
hashset.insert(3);
hashset.insert(2);
hashset.insert(1);
// 删除关键字
hashset.erase(2);
// 判断关键字是否在哈希集合中,如果在方法返回负数。如果在集合中返回真,否则返回假
if (hashset.count(2) <= 0) {
cout << "关键字2不在哈希集合中" << endl;
}
// 得到哈希集合的大小
cout << "The size of hash set is: " << hashset.size() << endl;
// 遍历哈希集合,注意要以指针的形式
for (auto it = hashset.begin(); it != hashset.end(); ++it) {
cout << (*it) << " ";
}
cout << "are in the hash set." << endl;
// 清除哈希集合
hashset.clear();
// 判断哈希结合是否为空
if (hashset.empty()) {
cout << "hash set is empty now!" << endl;
}
}
引用哈希表的应用:
#include<unordered_map>
#include<iostream>
using namespace std;
int main()
{
unordered_map<int,int>map;//创建哈希表
map[4] = 14;//直接赋值
map[5] = 15;
cout << map[4];//输出14
//通过insert()函数来添加元素
map.insert({ 5,15 });//参数为(键,值)
map.insert({ 5,16 });
cout << map[5]; //结果为15->一个下标只能对应一个值
//复制,重新构造一张新的哈希表
unordered_map<int, int> map{ {1,10},{2,12},{3,13} };
unordered_map<int, int> map1(map);
unordered_map<int, int>::iterator iter = hmap.begin();
unordered_map<int, int>::iterator iter = hmap.end();
bool isEmpty = map.empty();//判断是否为空
int size = hmap.size();//哈希表的大小
erase函数
map.erase(iter_begin); //删除开始位置的元素
map.erase(iter_begin, iter_end); //删除开始位置和结束位置之间的元素
map.erase(3); //删除key==3的键值对
//clear()函数:清空哈希表中的元素
map.clear();
unordered_map<int, int>::iterator iter;
iter = hmap.find(2); //返回key==2的迭代器,可以通过iter->second访问该key对应的元素
if(iter != hmap.end()) cout << iter->second;
int count = hmap.count(key);//统计哈希表键所对应的值的个数
//哈希表的遍历
for(auto iter=map.begin(); iter != map.end(); iter++){
cout << "key: " << iter->first << "value: " << iter->second <<endl;
}
小理解:
遇到不会的函数要积极动手查一查,你会发现有很多好用的函数
C语言是什么?不要联系我了,我现在只用C++
问:auto是啥?
答:auto是一种类型,像int,double,string,它能够根据后面是啥自动匹配对应的类型
通过下面的题目就会加深理解了^ ^
题目实战
1:存在重复元素

暴力的方法很容易想到:两个for嵌套:时间复杂度是:O(N^2)
我这里给出的是小暴力的方法:时间复杂度是O(N*logN)
bool containsDuplicate(vector<int>& nums)
{
sort(nums.begin(),nums.end());
for(int i=1;i<nums.size();i++)
if(nums[i]==nums[i-1])
return true;
retrun false;
}
哈希集合的方法:
思路解析:
遍历数组nums,将遍历到的元素插入hash集合中
如果哈希表的长度!=原数组的长度 -> 那么肯定有1个以上的重复元素插入到了哈希表
注意这只会导致元素作为索引对应的值增加,并不会使数组长度增加
画图理解:
原数组:
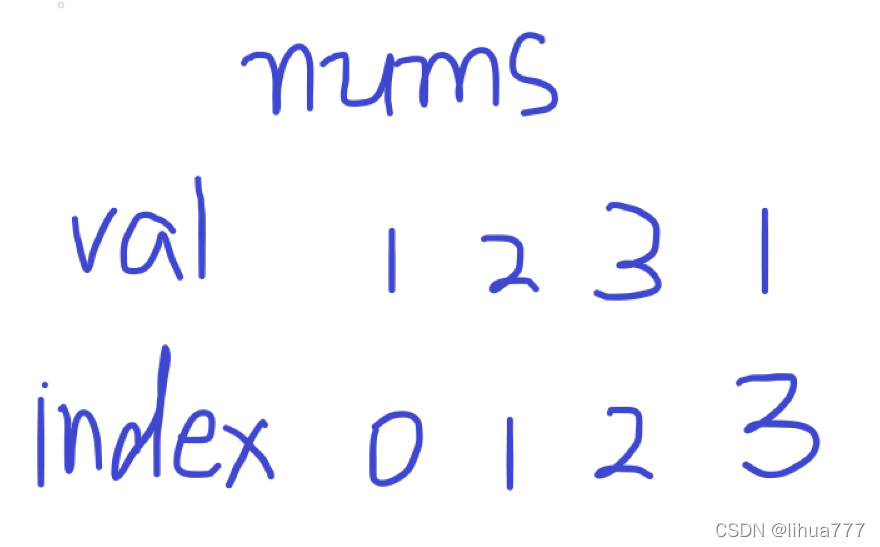
理解:原数组的val作为了hashset的index,原数组val的频数作为了hashset的val

bool containsDuplicate(vector<int>& nums) {
unordered_set<int>hash;
for (int a : nums)
{
hash.insert(a);
}
return hash.size() != nums.size();
}2:只出现一次的数字

思路解析:
这道题用位运算也非常简单,具体的写法用异或,可以看看我的一篇文章《位运算的应用》
与上题同一种思路,如果没有出现过就插入,如果出现过就删除
class Solution {
public:
int singleNumber(vector<int>& nums) {
unordered_set<int> hash;
for (auto& num : nums)//遍历数组
{
if (hash.count(num) > 0)//如果哈希表中有过一次元素
{
hash.erase(num);//删除该元素
}
else//如果哈希表之前没有过一次元素
{
hash.insert(num);//插入该元素
}
}//跳出循环后,哈希表中只剩下一个元素
return *hash.begin();//哈希表中的开头地址解引用就是仅有的那个元素
}
};3:两个数组的交集

思路解析:
开一个答案数组,用哈希表遍历存nums1的频数,遍历nums2,查找nums2是否有该元素,如果有,则尾插入答案数组,并在nums2中删除这个元素,防止重复出现
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> hashset;
vector<int> result;
for (auto val : nums1)
{
hashset.insert(val);
}
for (auto val : nums2)
{
if (hashset.count(val) > 0)
{
result.push_back(val);
hashset.erase(val);
}
}
return result;
}
};4:快乐数

思路解析:
设计一个函数cal 计算按照规律变化后的数字,并在哈希表中进行查询,如果哈希表中存在这个数,那么我们就可以知道,该数发生了重复,那么就直接返回false;反之如果这个数变了1,就跳出循环,返回true;
class Solution {
public:
int cal(int n)//计算规则后的数
{
int ans = 0;
while (n)
{
ans = ans + pow(n % 10, 2);
n = n / 10;
}
return ans;
}
bool isHappy(int n) {
unordered_set<int> hashset;
while (n != 1)//当不等于1的时候继续
{
n = cal(n);
if (hashset.count(n))//如果计算后的数字与哈希存的数字重复
{
return false;//返回错误
}
hashset.insert(n);//如果没有则,插入到哈希中
}
return true;
}
};5:赎金信(字母异位词的开始)

思路解析:
开一个26长度的数组去存储字母出现的频数,遍历第一个字符串,每遍历到一个字母就++
遍历第二个字符串,每遍历到一个字母就--,最后查找数组中是否有负数的情况,若有则说明第一个字符串不能由第二个字符串变形而来
代码实现:
class Solution {
public:
bool canConstruct(string s, string t) {
int record[26]={0};
for(int i=0;i<t.size();i++)
{
record[t[i]-'a']++;
}
for(int i=0;i<s.size();i++)
{
record[s[i]-'a']--;
}
for(int i=0;i<26;i++)
{
if(record[i]<0)
{
return false;
}
}
return true;
}
};6:字母异位词分组

思路解析:
与上题相同,判断是否位字母异位词,这道题的难点是,将单词分类,并归纳在一起
这里需要到了哈希表,而不是哈希集合,因为我们需要将单词排序后作为索引,而不是将数字作为索引,这是一种映射关系
这里就是哈希映射的的开始了^ ^
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string> >map;
for (int i = 0; i < strs.size(); i++)//将取出的字符串排序后作为一类
{
string str = strs[i];
sort(str.begin(), str.end());
map[str].push_back(strs[i]);//将未排序的字符串插入至已排序好的那一类
}
vector<vector<string> >ans;
for (auto it = map.begin(); it != map.end(); it++)//遍历尾插
{
ans.push_back(it->second);
}
return ans;
}
};补充:it->first是哈希表中的键,it->second是哈希表中的值
7:找到字符串中所有字母的异位词(滑动窗口+哈希)

思路解析:
用scount数组存s字符串中的频数,用pcount数组存p字符串中的频数
以strlen(p)为长度作为滑窗,每次遍历判断长度为strlen(p)的scount是否与pcount相等
如果相等就插入答案数组,如果不相等就continue
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int slen = s.size();
int plen = p.size();
if (slen < plen)
{
return vector<int>();
}
vector<int> ans;
vector<int> sCount(26);
vector<int> pCount(26);
for (int i = 0; i < plen; i++)
{
sCount[s[i] - 'a']++;
pCount[p[i] - 'a']++;//用哈希表记录频数
}
if (sCount == pCount)
{
ans.emplace_back(0);//如果这两个一开始频数相等,返回索引0
}
for (int i = 0; i < slen - plen; i++)
{
sCount[s[i] - 'a']--;//滑动窗口从1开始滑!
sCount[s[i + plen] - 'a']++;
if (sCount == pCount)//判断此时窗口内的哈希是否与pcount相等
{
ans.emplace_back(i + 1);//若相等,尾插索引
}
}
return ans;
}
};8:两数之和
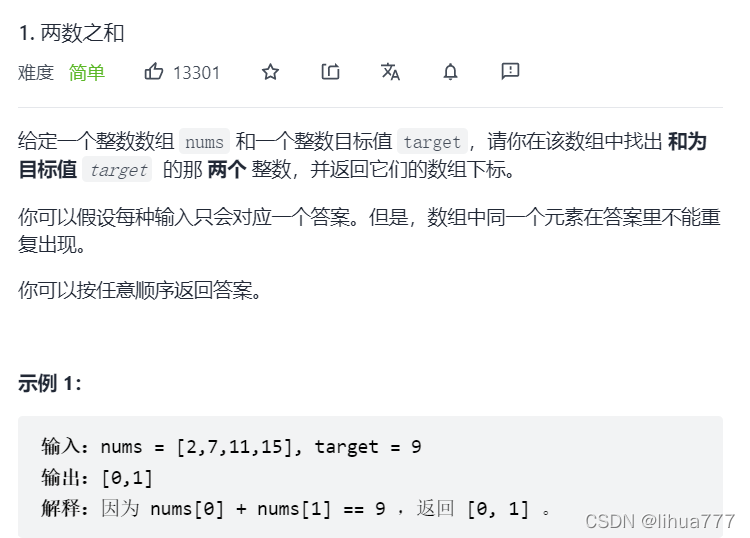
思路解析:
我们这里采用了哈希表的方法,遍历一遍数组,用哈希表查看是否存在{target-nums[i]}元素
如果存在则返回{target-nums[i]},若不存在则将插入{键:nums[i],值:i}
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int>hashmap;
for (int i = 0; i < nums.size(); i++)
{
if (hashmap.count(target - nums[i]))
{
return { hashmap[target - nums[i]],i };
}
hashmap[nums[i]] = i;
}
return { -1,-1 };
}
};补充:这里的键和值的关系非常巧妙,注意体会^ ^
9:四数相加||

思路解析:
注释已经很清楚了^ ^
这道题是升级版的两数之和
class Solution {
public:
int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {
unordered_map<int, int> map; //key:a+b的数值,value:a+b数值出现的次数
// 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
for (int a : A) {
for (int b : B) {
umap[a + b]++;
}
}
int count = 0; // 统计a+b+c+d = 0 出现的次数
// 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
for (int c : C) {
for (int d : D) {
if (map.count(0 - (c + d))) {
count += map[0 - (c + d)];
}
}
}
return count;
}
};补充:关于find和count,我更喜欢用count ^ ^ 二者都是查找哈希表
find是如果找不到就返回哈希表的尾地址
count是如果找到不到就返回0














 1377
1377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









