






MNIST任务是作为初学者来说, 是一个不错的起点。掌握MNIST任务的实现,以此为后续的CV(计算机视觉)和DL(深度学习)打下良好基础的基础。
目录
1.任务背景
MNIST(Modified National Institute of Standards and Technology)数据集是一个广泛使用的手写数字识别数据集。它包含了从0到9的数字的灰度图像,通常用于训练和测试图像识别算法。MNIST数据集是由纽约大学的Yann LeCun教授及其同事创建的,它是对原始的NIST数据集进行修改和整理后的版本。
MNIST数据集包含60,000个训练样本和10,000个测试样本。每个样本都是一个28x28像素的灰度图像,代表了0到9中的一个数字。这些图像是从不同的手写体、不同的书写风格和不同的字体中提取的,因此包含了大量的变异性。
2.任务流程
为了让大家更能理解mnist的任务实现,这里绘制了流程图:
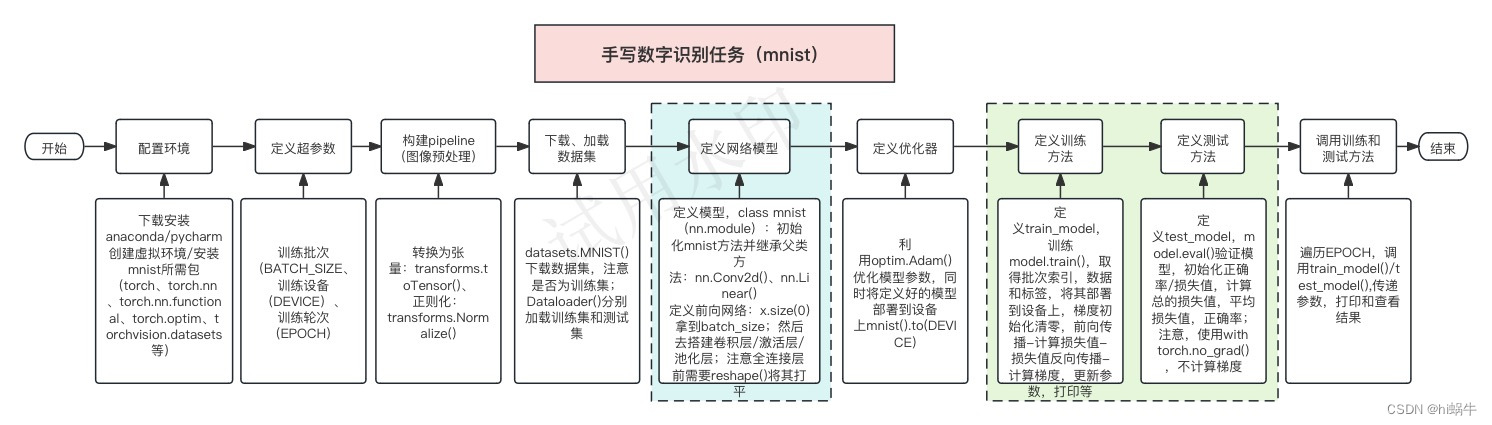
3.代码实现
为了源码的可读性,给出了每行源码及其注释。
代码已在pytorch框架调试(NVIDIA RTX 3060 12G,anaconda+pycharm),大家可直接拿来使用,正确率可以达到99%以上,如果达不到,可以根据硬件条件,固定随机种子,修改模型超参数,以达到最优。
'''1.加载必要的库'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
'''2.定义超参数'''
BATCH_SIZE=64 # 每个批次处理的图像
EPOCH=10 # 训练数据集的轮次:数据集的循环运行几轮
DEVICE=torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 判断是否用GPU还是CPU训练
'''3.构建pipeline,对图像做预处理(transform)'''
pipeline=transforms.Compose([
transforms.ToTensor(), # 将图片转换成tensor
transforms.Normalize((0.1307,),(0.3081,)) # 正则化,降低模型复杂度
])
'''4.下载、加载数据集'''
torch.manual_seed(0) #固定随机种子,大家可以尝试不同的种子测试,择选最好的一次
train_set=datasets.MNIST('data',train=True,download=True,transform=pipeline) # 下载训练集
test_set=datasets.MNIST('data',train=False,download=True,transform=pipeline) # 下载测试集
train_loader=DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True) # 加载训练集
test_loader=DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=True) # 加载测试集 (这里顺序可以不打乱)
'''5.定义网络模型'''
class mnist(nn.Module): # 构建mnist模型,并继承module类
def __init__(self): # 初始化mnist方法
super().__init__() # 继承父类的方法
self.conv1=nn.Conv2d(1,10,5) # 创建一个卷积模型,1:灰度图通道,10:输出通道,5:卷积核(kernel)大小
self.conv2=nn.Conv2d(10,20,3) # 创建一个卷积模型,10:输入通道,20:输出通道,3:kernel大小
self.drop_out=nn.Dropout2d(0.25)
self.fc1=nn.Linear(20*10*10,500) # 20*10*10:输入通道,500:输出通道
self.fc2=nn.Linear(500,10) # # 500:输入通道,10:输出通道
def forward(self,x):
input_size=x.size(0) # 取到第0维:batch_size
x=self.conv1(x) # 输入:batch_size*1*28*28,输出:batch_size*10*24*24(24=28-5+1,padding=0,stride=1)
x=F.relu(x) # 保持shape不变,表达能力更强
x=F.max_pool2d(x,2,2) #最大池化层,步长是2,24/2=12,结果:batch_size*10*12*12
x=self.conv2(x) # 输入:batch_size*10*12*12,输出:batch_size*20*10*10
x=F.relu(x)
x=x.reshape(input_size, -1) # 计算其维度 2000=20*10*10,并将其打平
x=self.fc1(x) # 输入:batch_size=2000, 输出:batch_size*500
x = F.relu(x)
x=self.fc2(x) # 输入:batch_size=500, 输出:batch_size*10
x = F.relu(x)
output=F.log_softmax(x,dim=1) #计算分类后,每个数字的概率值
return output
'''6.定义优化器'''
model=mnist().to(DEVICE) # 创建模型,并部署到设备上
optimizer=optim.Adam(model.parameters()) # 优化模型的参数
'''7.定义训练方法'''
def train_model(model,device,train_loader,optimizer,epoch): # 定义训练方法
model.train() #训练模型
loss_total=0
for batch_index,(data,target) in enumerate(train_loader):
data,target=data.to(device),target.to(device) # 把数据部署到设备上
optimizer.zero_grad() # 梯度初始化为0
output=model(data) # 前向传播,得到训练后的结果
loss=F.cross_entropy(output,target) # 计算损失值
loss.backward() # 将损失值进行反向传播
optimizer.step() # 参数的优化更新
loss_total+=loss.item() # 累加一个epoch所有损失值
loss_epoch=loss_total/len(train_loader) # 计算机每一个epoch的平均损失值
print(f'Train epoch:{epoch} \t loss_epoch:{loss_epoch:0.6f}') # 打印epoch及平均损失值
'''8.定义测试方法'''
def test_model(model,device,test_loader):
model.eval() # 设置模型的评估模式
correct=0.0 # 初始化正确率
loss_test=0.0 # 初始化损失值
with torch.no_grad(): # 测试环境,不计算梯度,也不进行反向传播
for data,target in test_loader:
data,target=data.to(device),target.to(device) # 将数据移动到设备上
output=model(data) # 前向传播
loss_test+=F.cross_entropy(output,target).item() # 累加当前批次的损失值之和
pred = output.max(1, keepdim=True)[1] # 找到概率值最大的下标
correct+=pred.eq(target.view_as(pred)).sum().item() # 计算正确的样本数量
loss_test/=len(test_loader.dataset) # 计算测试集平均的损失
Accuracy=100*correct/len(test_loader.dataset)
print(f'Test_loss:{loss_test:.4f} \t Accuracy:{Accuracy:.3f}\n')
'''9.调用训练和测试的方法'''
for epoch in range(EPOCH):
train_model(model,DEVICE,train_loader,optimizer,epoch)
test_model(model,DEVICE,test_loader)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









