






- 梯度的定义
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。比如函数f(x,y),分别对x,y求偏导数,求得的梯度向量就是(∂f/∂x, ∂f/∂y)T
从几何意义上讲,就是函数变化增加最快的地方。具体来说,对于函数f(x,y),在点(x0,y0),沿着梯度向量的方向就是(∂f/∂x0, ∂f/∂y0)T的方向是f(x,y)增加最快的地方。或者说,沿着梯度向量的方向,更加容易找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是 -(∂f/∂x0, ∂f/∂y0)T的方向,梯度减少最快,也就是更加容易找到函数的最小值。
注意:
- 梯度是一个向量,即有方向有大小;
- 梯度的方向是最大方向导数的方向;
- 梯度的值是最大方向导数的值。
- 梯度下降法
由以上梯度定义可知,在变量空间的某一点处, 梯度方向是函数上升最快的方向,我们若要求解最大值点,通过取梯度方向即可,而我们需要求解的是最小值点,那么在优化目标函数的时候,自然是沿着负梯度方向去减小函数值,以此达到我们的优化目标。
其迭代过程为:
![]()
其中x为可行解,α为步长,p为方向,从这个过程中可以看出只需要确定方向以及步长,即可开始进行迭代。 既然在变量空间的某一点处,函数沿梯度方向具有最大的变化率,那么在优化目标函数的时候,自然是沿着负梯度方向去减小函数值,以此达到我们的优化目标。 如下图所示:
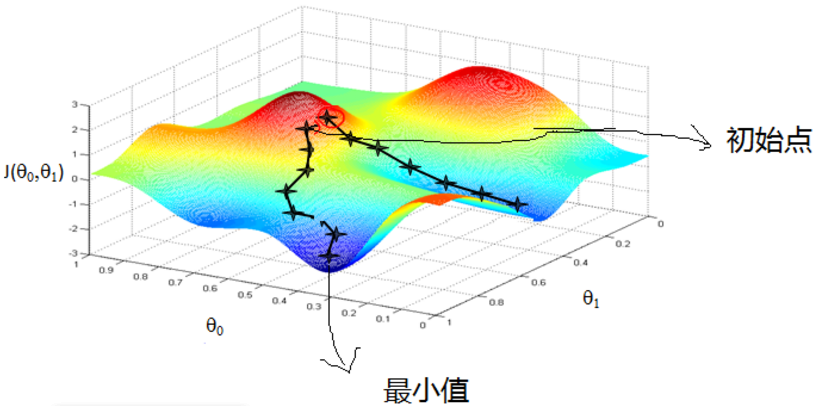
算法过程:
1)确定当前位置的损失函数的梯度
2)用步长乘以损失函数的梯度,得到当前位置下降的距离,即对应于前面登山例子中的某一步。
3)确定是否所有的,梯度下降的距离都小于,如果小于则算法终止,当前所有的(i=0,1,...n)即为最终结果。否则进 入步骤4.
4)更新所有的向量,更新完毕后继续转入步骤1。
梯度下降法是一种最优化算法,在最优化理论里面也叫最速下降法,在常用的优化算法当中算是最简单的一种算法了。一般来说求解优化问题根据具体情况有很多其他更好的办法,不过下降法思想是其他大多数优化迭代算法的基础。
缺点:
固定步长进行迭代,其优点就是简单方便,但是缺点就是收敛速度慢,并且有个时候不一定能收敛。对于梯度下降法来说,虽然每一步是最速下降的,但是全局收敛速度并不快,特别是在接近最小值的时候,梯度很小,导致下降的速度减慢,对于一些狭长地带甚至会"之字形"下降。
- 梯度下降法和梯度上升法的关系
在机器学习算法中,在最小化损失函数时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数,和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。
梯度下降法和梯度上升法是可以互相转化的。比如我们需要求解损失函数f(θ)的最小值,这时我们需要用梯度下降法来迭代求解。但是实际上,我们可以反过来求解损失函数 -f(θ)的最大值,这时梯度上升法就派上用场了。
- 梯度下降法的其他算法
1.批量梯度下降法
批量梯度下降法,是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新
θi=θi−α∑j(hθ(x0,x1,...xn)−yj)xi
由于我们有m个样本,这里求梯度的时候就用了所有m个样本的梯度数据。
2.随机梯度下降法
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。对应的更新公式是:
θi=θi−α(hθ(x0,x1,...xn)−yj)xi
随机梯度下降法,和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
- 例:用梯度下降法求x^2+y^2的最小值并画图
python代码实现:
import numpy as np
import operator
def f(x,y):
return x**2+y**2
def g(t):
return 2*t
X = []
Y = []
Z = []
x = 2
y = 2
z = 2
step = 0.1
f_change = f(x,y)
f_current = f(x,y)
X.append(x)
Y.append(y)
Z.append(f_current)
while f_change > 1e-20:
x = x - step*g(x)
y = y - step*g(y)
tmp = f(x,y)
f_change = np.abs(f_current - tmp)
f_current = tmp
X.append(x)
Y.append(y)
Z.append(f_current)
print("最小值点为:\n",(x,y,f_current))
import matplotlib
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
X1=np.arange(-2,2,0.05)
Y1=np.arange(-2,2,0.05)
X1,Y1=np.meshgrid(X1,Y1) #meshgrid() 函数,用于从x1到x2数列产生网格
Z1=X1**2+Y1**2
ax.plot_surface(X1,Y1,Z1,rstride=1,cstride=1,cmap='rainbow')
ax.plot(X,Y,Z,'ro--')
plt.show()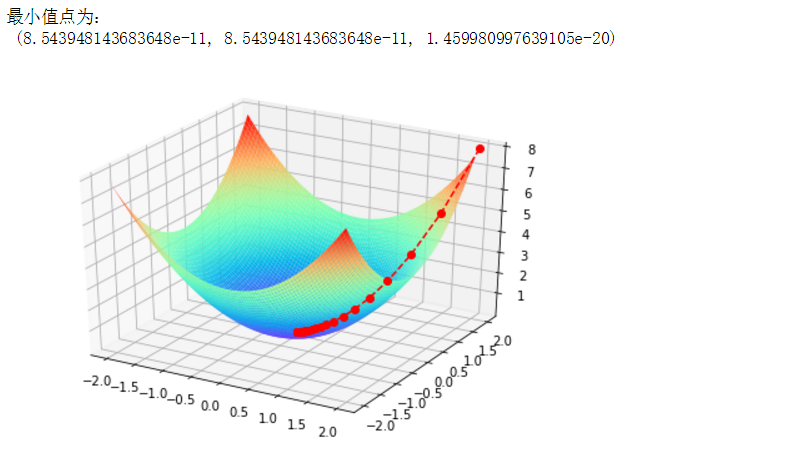















 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









