






目录
引言
本周阅读了一篇基于Transformer的增量语义分割方法(TISS)的文献,语义分割是计算机视觉中的一个基本问题,但现有的卷积神经网络方法在增量学习中存在灾难性遗忘问题,该文章通过引入两种基于补丁的对比损失,旨在减轻灾难性遗忘并提高模型性能。而Transformer 简单点看其实就是 self-attention 模型的叠加,在self-attention中进一步学习了Multi-Head Attention的相关知识。
Abstract
This week, I read a literature on Transformer based Incremental Semantic Segmentation Method (TISS). Semantic segmentation is a fundamental problem in computer vision, but existing convolutional neural network methods suffer from catastrophic forgetting in incremental learning. This article aims to reduce catastrophic forgetting and improve model performance by introducing two patch based contrastive losses. To put it simply, Transformer is actually a superposition of self attention models, in which we further learned the relevant knowledge of Multi Head Attention.
一、文献阅读
1、题目
Delving into Transformer for Incremental Semantic Segmentation
2、引言
增量语义分割(ISS)是一项新兴任务,通过增量添加新类来更新旧模型。目前,基于卷积神经网络的方法在ISS中占主导地位。然而,研究表明,这种方法很难在学习新任务的同时保持对旧任务的良好表现(灾难性遗忘)。相比之下,基于Transformer的方法在抑制灾难性遗忘方面具有天然的优势,因为它能够对长期和短期任务进行建模。在这项工作中,我们探索了基于Transformer的架构更适合ISS的原因,并相应地提出了一种基于Transformer进行增量语义分割的方法TISS。此外,为了更好地缓解灾难性遗忘,同时保持ISS上的可转移性,我们引入了两种拼接对比损失来分别模拟相似特征和增强特征多样性,这可以进一步提高TISS的性能。
3、方法
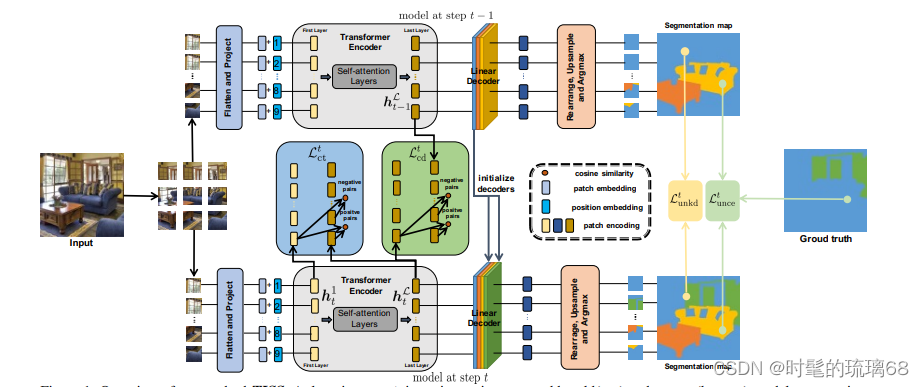
本文介绍了一种基于Transformer的增量语义分割方法TISS。该方法旨在解决CNN架构在增量语义分割中的灾难性遗忘问题。通过利用Transformer架构的优势,将蒸馏方法与Transformer架构相结合,以缓解遗忘问题,并通过引入两种新颖的基于补丁的对比损失进一步抑制灾难性遗忘,提高新任务的性能。
在学习步骤t,将类c的线性解码器参数表示为{ωtc,βtc}∈θt,其中ω和β表示其权重和偏差。

在步骤 t 提出了在从模型的第一层和最后一层学习的表示之间的拼接对比损失 。
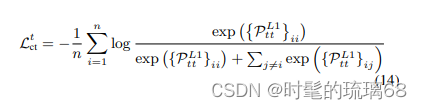
TISS由编码器和线性解码器组成。编码器基于ViT,具有不同的大小(Tiny、Small、Base和Large)。解码器将补丁表示映射到分割图。为了改善Transformer在增量语义分割中的性能,引入了两种基于补丁的损失:补丁对比蒸馏损失(Ltcd)和补丁对比损失(Ltct)。Ltcd通过约束当前模型(Mt)的最后一层的补丁表示与先前模型(Mt-1)的最后一层的补丁表示相似,增强了模型积累知识的能力。Ltct通过约束第一层和第t步模型的最后一层的补丁表示与其他补丁相似和不同,提高了模型在新任务上的泛化能力。第t步的总损失定义为Lttotal,它是补丁损失和其他损失的组合。每个损失的权重(wt)根据需要进行设置。
4、实验过程

使用Pascal-VOC 2012数据集进行了三种不同的实验,分别是单类别添加、一次性添加五个类别和逐步添加五个类别。对于Pascal-VOC 2012,批量大小为12,训练30个epochs;对于ADE20K,批量大小为8,训练60个epochs。使用20%的训练集作为验证集,最终结果报告在数据集的标准验证集上。使用了两种实验协议,即不相交设置和重叠设置。在训练配置方面,使用了SGD优化器和相同的学习率策略、动量和权重衰减。还对ADE20K数据集进行了类似的实验,考虑了一次性添加最后50个类别、每次添加10个类别和分两步添加最后100个类别的情况。
5、实验结果
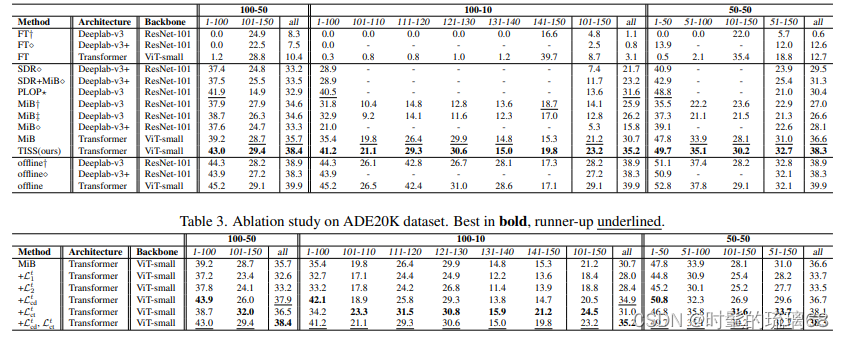
ADE20K数据集包含物体和场景类别,相比Pascal-VOC 2012更具挑战性。进行了三种不同的实验,分别是一次性添加最后50个类别(100-50),每次添加最后50个类别10个类别(100-10),以及分两步添加最后100个类别。实验结果表明,基于Transformer的架构更适用于抑制增量语义分割中的灾难性遗忘问题。TISS方法在旧类别上的表现优于其他方法,新类别上也有显著提升。冻结BN层在抑制灾难性遗忘方面是有效的。
6、结论
TISS在Pascal-VOC 2012数据集的所有类别中表现优异,超越了其他方法,在不同学习步骤中积累先前知识的能力以及学习新知识的能力得到了强调,在不同任务中的表现均优于MiB方法,特别是在添加新类别的任务中。
二、Multi-Head Attention
Encoder 和 Decoder 结构中公共的 layer之一是 Multi-Head Attention,其是由多个 Self-Attention 并行组成的。Encoder block 只包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。
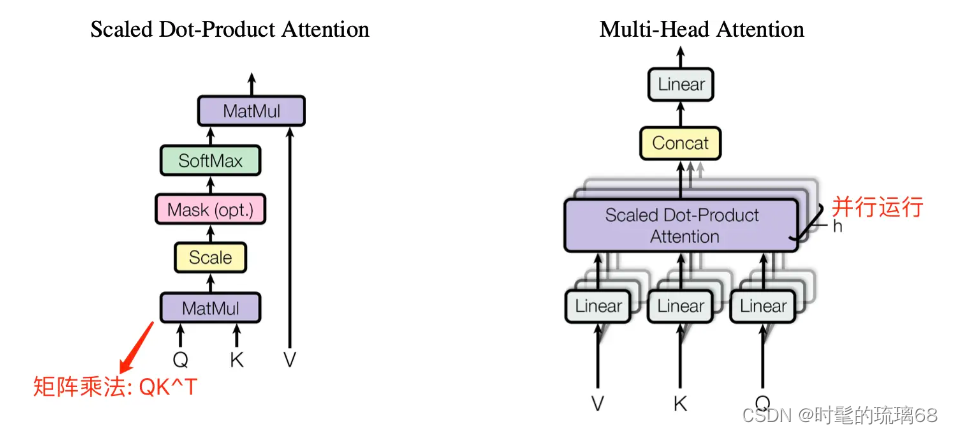
1、Self-Attention 结构
Self-Attention 中文翻译为自注意力机制,论文中叫作 Scale Dot Product Attention,它是 Transformer 架构的核心,其结构如下图所示:

在 Self-Attention 中,Q、K、V 是在同一个输入(比如序列中的一个单词)上计算得到的三个向量。具体来说,我们可以通过对原始输入词的 embedding 进行线性变换(比如使用一个全连接层),来得到 Q、K、V。
在计算 Self-Attention 时,Q、K、V 被用来计算注意力分数,即用于表示当前位置和其他位置之间的关系。注意力分数可以通过 Q 和 K 的点积来计算,然后将分数除以 8,再经过一个 softmax 归一化处理,得到每个位置的权重。然后用这些权重来加权计算 V 的加权和,即得到当前位置的输出。
将分数除以 8 的操作,对应图中的
Scale层,这个参数 8 是 K 向量维度 64 的平方根结果。
2、Self-Attention 实现
输入序列单词的 Embedding Vector 经过线性变换(Linear 层)得到 Q、K、V 三个向量,并将它们作为 Self-Attention 层的输入。假设输入序列的长度为 seq_len,则 Q、K 和 V 的形状为(seq_len,d_k), 表示每个词或向量的维度,也是 Q、K 矩阵的列数。在论文中,输入给 Self-Attention 层的 Q、K、V 的向量维度是 64, Embedding Vector 和 Encoder-Decoder 模块输入输出的维度都是 512。
Embedding Vector 的大小是我们可以设置的超参数—基本上它就是我们训练数据集中最长句子的长度。
Self-Attention 层的计算过程用数学公式可表达为:
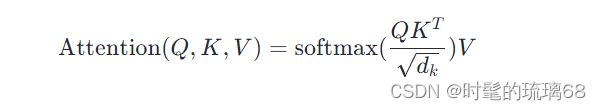
以下是一个示例代码,它创建了一个 ScaleDotProductAttention 层,并将 Q、K、V 三个张量传递给它进行计算:
class ScaleDotProductAttention(nn.Module):
def __init__(self, ):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim = -1)
def forward(self, Q, K, V, mask=None):
K_T = K.transpose(-1, -2) # 计算矩阵 K 的转置
d_k = Q.size(-1)
# 1, 计算 Q, K^T 矩阵的点积,再除以 sqrt(d_k) 得到注意力分数矩阵
scores = torch.matmul(Q, K_T) / math.sqrt(d_k)
# 2, 如果有掩码,则将注意力分数矩阵中对应掩码位置的值设为负无穷大
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 3, 对注意力分数矩阵按照最后一个维度进行 softmax 操作,得到注意力权重矩阵,值范围为 [0, 1]
attn_weights = self.softmax(scores)
# 4, 将注意力权重矩阵乘以 V,得到最终的输出矩阵
output = torch.matmul(attn_weights, V)
return output, attn_weights
# 创建 Q、K、V 三个张量
Q = torch.randn(5, 10, 64) # (batch_size, sequence_length, d_k)
K = torch.randn(5, 10, 64) # (batch_size, sequence_length, d_k)
V = torch.randn(5, 10, 64) # (batch_size, sequence_length, d_k)
# 创建 ScaleDotProductAttention 层
attention = ScaleDotProductAttention()
# 将 Q、K、V 三个张量传递给 ScaleDotProductAttention 层进行计算
output, attn_weights = attention(Q, K, V)
# 打印输出矩阵和注意力权重矩阵的形状
print(f"ScaleDotProductAttention output shape: {output.shape}") # torch.Size([5, 10, 64])
print(f"attn_weights shape: {attn_weights.shape}") # torch.Size([5, 10, 10])
3、Multi-Head Attention结构
Multi-Head Attention (MHA) 是基于 Self-Attention (SA) 的一种变体。MHA 在 SA 的基础上引入了“多头”机制,将输入拆分为多个子空间,每个子空间分别执行 SA,最后将多个子空间的输出拼接在一起并进行线性变换,从而得到最终的输出。
对于 MHA,之所以需要对 Q、K、V 进行多头(head)划分,其目的是为了增强模型对不同信息的关注。具体来说,多组 Q、K、V 分别计算 Self-Attention,每个头自然就会有独立的 Q、K、V 参数,从而让模型同时关注多个不同的信息,这有些类似 CNN 架构模型的多通道机制。
下图是论文中 Multi-Head Attention 的结构图。

从图中可以看出, MHA 结构的计算过程可总结为下述步骤:
- 将输入 Q、K、V 张量进行线性变换(
Linear层); - 将前面步骤输出的张量,按照头的数量(
n_head)拆分为n_head子张量; - 每个子张量并行计算注意力分数,即执行 dot-product attention 层;
- 将这些子张量进行拼接
concat,并经过线性变换得到最终的输出张量;
因为 GPU 的并行计算特性,步骤2中的张量拆分和步骤4中的张量拼接,其实都是通过 review 算子来实现的。同时,也能发现SA 和 MHA 模块的输入输出矩阵维度都是一样的。
4、Multi-Head Attention 实现
Multi-Head Attention 层的输入同样也是三个张量:查询(Query)、键(Key)和值(Value),其计算过程用数学公式可表达为:
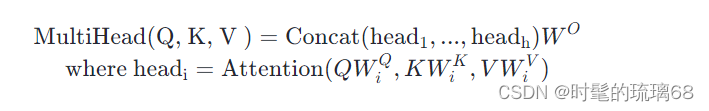
一般用 d_model 表示输入嵌入向量的维度, n_head 表示分割成多少个头,因此,d_model//n_head 自然表示每个头的输入和输出维度,在论文中 d_model = 512,n_head = 8,d_model//n_head = 64。值得注意的是,由于每个头的维数减少,总计算成本与具有全维的单头注意力是相似的。
Multi-Head Attention 层的 Pytorch 实现代码如下所示
class MultiHeadAttention(nn.Module):
"""Multi-Head Attention Layer
Args:
d_model: Dimensions of the input embedding vector, equal to input and output dimensions of each head
n_head: number of heads, which is also the number of parallel attention layers
"""
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention()
self.w_q = nn.Linear(d_model, d_model) # Q 线性变换层
self.w_k = nn.Linear(d_model, d_model) # K 线性变换层
self.w_v = nn.Linear(d_model, d_model) # V 线性变换层
self.fc = nn.Linear(d_model, d_model) # 输出线性变换层
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v) # size is [batch_size, seq_len, d_model]
# 2, split by number of heads(n_head) # size is [batch_size, n_head, seq_len, d_model//n_head]
q, k, v = self.split(q), self.split(k), self.split(v)
# 3, compute attention
sa_output, attn_weights = self.attention(q, k, v, mask)
# 4, concat attention and linear transformation
concat_tensor = self.concat(sa_output)
mha_output = self.fc(concat_tensor)
return mha_output
def split(self, tensor):
"""
split tensor by number of head(n_head)
:param tensor: [batch_size, seq_len, d_model]
:return: [batch_size, n_head, seq_len, d_model//n_head], 输出矩阵是四维的,第二个维度是 head 维度
# 将 Q、K、V 通过 reshape 函数拆分为 n_head 个头
batch_size, seq_len, _ = q.shape
q = q.reshape(batch_size, seq_len, n_head, d_model // n_head)
k = k.reshape(batch_size, seq_len, n_head, d_model // n_head)
v = v.reshape(batch_size, seq_len, n_head, d_model // n_head)
"""
batch_size, seq_len, d_model = tensor.size()
d_tensor = d_model // self.n_head
split_tensor = tensor.view(batch_size, seq_len, self.n_head, d_tensor).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return split_tensor
def concat(self, sa_output):
""" merge multiple heads back together
Args:
sa_output: [batch_size, n_head, seq_len, d_tensor]
return: [batch_size, seq_len, d_model]
"""
batch_size, n_head, seq_len, d_tensor = sa_output.size()
d_model = n_head * d_tensor
concat_tensor = sa_output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return concat_tensor
总结
本周在关于transfomer的学习中阅读文献和其self-attention进一步学习深入代码相关知识,对其有了更深入的理解,接下来会更进一步的学习。















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









